统计学习方法 | 第3章 k邻近法 | 补充
namedtuple
不必再通过索引值进行访问,你可以把它看做一个字典通过名字进行访问,只不过其中的值是不能改变的。
sorted()适用于任何可迭代容器,list.sort()仅支持list(本身就是list的一个方法)
np.linalg.norm(求范数)
1、linalg=linear(线性)+algebra(代数),norm则表示范数。
2、函数参数
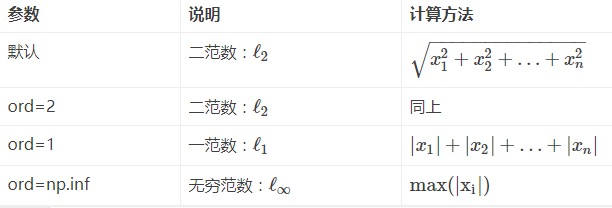
x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)①x: 表示矩阵(也可以是一维)
②ord:范数类型
向量的范数:
train_test_split函数
用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签。
格式:
X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.3, random_state=0)
参数解释:
train_data:被划分的样本特征集
train_target:被划分的样本标签
test_size:如果是浮点数,在0-1之间,表示样本占比;如果是整数的话就是样本的数量
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
itertools
Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数。
首先,我们看看itertools提供的几个“无限”迭代器:
>>> import itertools
>>> natuals = itertools.count(1)
>>> for n in natuals:
... print n
...
1
2
3
...
因为count()会创建一个无限的迭代器,所以上述代码会打印出自然数序列,根本停不下来,只能按Ctrl+C退出。
cycle()会把传入的一个序列无限重复下去:
>>> import itertools
>>> cs = itertools.cycle('ABC') # 注意字符串也是序列的一种
>>> for c in cs:
... print c
...
'A'
'B'
'C'
'A'
'B'
'C'
...
同样停不下来。
repeat()负责把一个元素无限重复下去,不过如果提供第二个参数就可以限定重复次数:
>>> ns = itertools.repeat('A', 10)
>>> for n in ns:
... print n
...
打印10次'A'
无限序列只有在for迭代时才会无限地迭代下去,如果只是创建了一个迭代对象,它不会事先把无限个元素生成出来,事实上也不可能在内存中创建无限多个元素。
无限序列虽然可以无限迭代下去,但是通常我们会通过takewhile()等函数根据条件判断来截取出一个有限的序列:
>>> natuals = itertools.count(1)
>>> ns = itertools.takewhile(lambda x: x <= 10, natuals)
>>> for n in ns:
... print n
...
打印出1到10
统计学习方法 | 第3章 k邻近法 | 补充的更多相关文章
- 统计学习方法 | 第3章 k邻近法
第3章 k近邻法 1.近邻法是基本且简单的分类与回归方法.近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的个最近邻训练实例点,然后利用这个训练实例点的类的多数来预测输入实例 ...
- 《统计学习方法》笔记三 k近邻法
本系列笔记内容参考来源为李航<统计学习方法> k近邻是一种基本分类与回归方法,书中只讨论分类情况.输入为实例的特征向量,输出为实例的类别.k值的选择.距离度量及分类决策规则是k近邻法的三个 ...
- 统计学习方法(三)——K近邻法
/*先把标题给写了.这样就能经常提醒自己*/ 1. k近邻算法 k临近算法的过程,即对一个新的样本,找到特征空间中与其最近的k个样本,这k个样本多数属于某个类,就把这个新的样本也归为这个类. 算法 ...
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 《统计学习方法(李航)》讲义 第03章 k近邻法
k 近邻法(k-nearest neighbor,k-NN) 是一种基本分类与回归方法.本书只讨论分类问题中的k近邻法.k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类 ...
- 统计学习三:1.k近邻法
全文引用自<统计学习方法>(李航) K近邻算法(k-nearest neighbor, KNN) 是一种非常简单直观的基本分类和回归方法,于1968年由Cover和Hart提出.在本文中, ...
- 统计学习三:2.K近邻法代码实现(以最近邻法为例)
通过上文可知k近邻算法的基本原理,以及算法的具体流程,kd树的生成和搜索算法原理.本文实现了kd树的生成和搜索算法,通过对算法的具体实现,我们可以对算法原理有进一步的了解.具体代码可以在我的githu ...
- 第三章 K近邻法(k-nearest neighbor)
书中存在的一些疑问 kd树的实现过程中,为何选择的切分坐标轴要不断变换?公式如:x(l)=j(modk)+1.有什么好处呢?优点在哪?还有的实现是通过选取方差最大的维度作为划分坐标轴,有何区别? 第一 ...
- 统计学习方法 | 第1章 统计学习方法概论 | Scipy中的Leastsq()
Scipy是一个用于数学.科学.工程领域的常用软件包,可以处理插值.积分.优化.图像处理.常微分方程数值解的求解.信号处理等问题.它用于有效计算Numpy矩阵,使Numpy和Scipy协同工作,高效解 ...
随机推荐
- Juit4 SpringBoot注解
@RunWith就是一个运行器 @RunWith(JUnit4.class)就是指用JUnit4来运行 @RunWith(SpringJUnit4ClassRunner.class),让测试运行于Sp ...
- 【leetcode】1287. Element Appearing More Than 25% In Sorted Array
题目如下: Given an integer array sorted in non-decreasing order, there is exactly one integer in the arr ...
- RSA加密解密,Base64String
///<remarks> /// DotNet.Utilities.RSACryption cryption = new DotNet.Utilities.RSACryption(); / ...
- jquery unbind()方法 语法
jquery unbind()方法 语法 作用:unbind() 方法移除被选元素的事件处理程序.该方法能够移除所有的或被选的事件处理程序,或者当事件发生时终止指定函数的运行.ubind() 适用于任 ...
- Shell登陆
Shell登录信息 注:只对本地终端起作用,远程终端不起作用(也就是说这个文件对远程登录是无效的). 修改后: 输出: 注:这里在配置文件中添加\l之后会显示终端(这里为终端1),按住Alt+F2可以 ...
- CDOJ 1133 菲波拉契数制 变直接统计为构造
菲波拉契数制 Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) Submit St ...
- mongodb Sort排序能够支持的最大内存限制为32M Plan executor error during find: FAILURE
1.一个比较老的游戏服维护,关服维护后启动时报错 2.看到关于mongodb的报错,于是去查一下mongodb的日志 Plan executor error during find: FAILURE, ...
- sh_14_字符串定义和遍历
sh_14_字符串定义和遍历 str1 = "hello python" str2 = '我的外号是"大西瓜"' print(str2) print(str1[ ...
- BZOJ 4221 [JOI2012春季合宿]Kangaroo (DP)
题目链接 https://www.lydsy.com/JudgeOnline/problem.php?id=4221 题解 orz WYC 爆切神仙DP 首先将所有袋鼠按大小排序.考虑从前往后DP, ...
- MySQL的安装教程
一.MYSQL的安装 首先登入官网下载mysql的安装包,官网地址:https://dev.mysql.com/downloads/mysql/ 一般下载这个就好,现在的最新版本是5.8,但是据说已经 ...