scrapy爬取数据的基本流程及url地址拼接
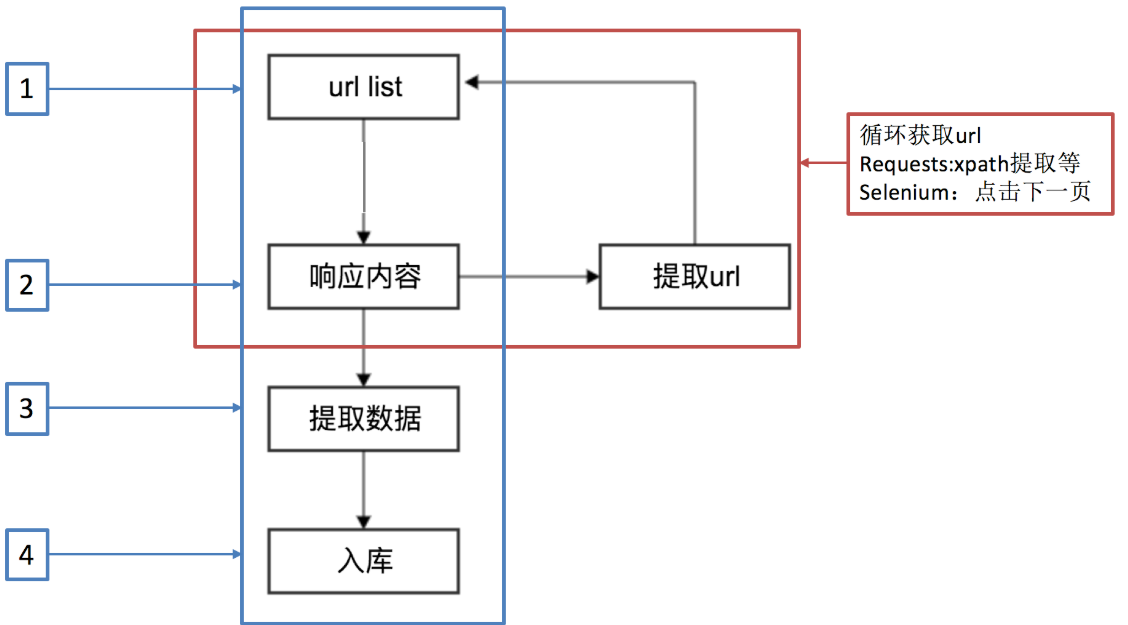


上面的代码应该改成:yield item
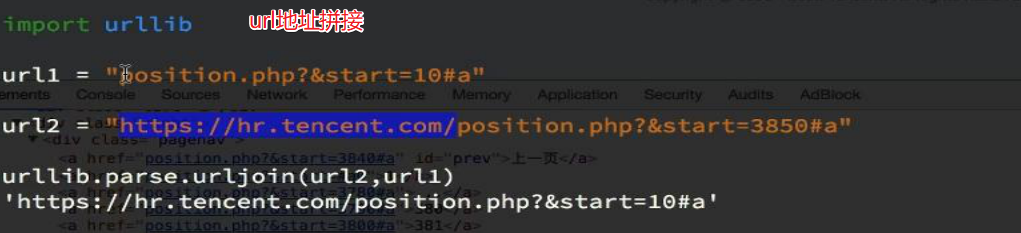
#主站链接 用来拼接
base_site = 'https://www.jpdd.com' def parse(self,response):
book_urls = response.xpath('//table[@class="p-list"]//a/@href').extract() for book_url in book_urls:
url = self.base_site + book_url
yield scrapy.Request(url, callback=self.getInfo) #获取下一页
next_page_url = self.base_site + response.xpath(
'//table[@class="p-name"]//a[contains(text(),"下一页")]/@href'
).extract()[0] yield scrapy.Request(next_page_url, callback=self.parse)
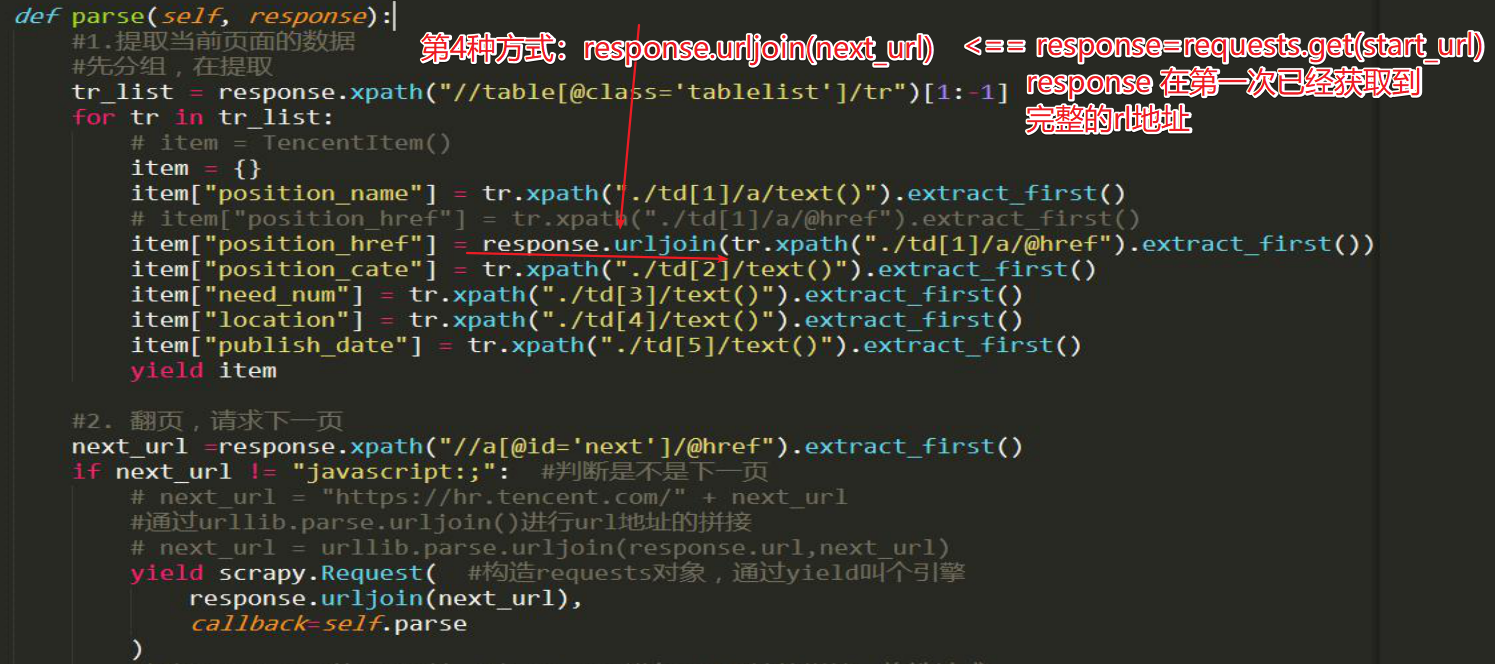
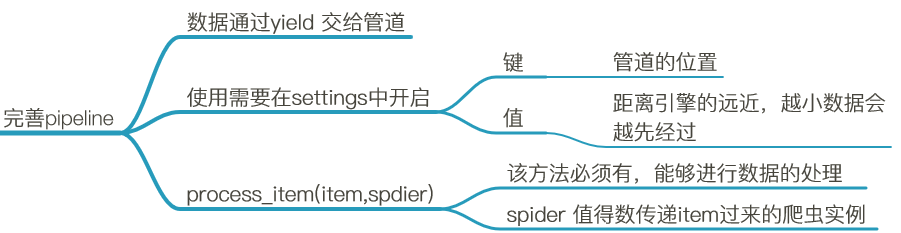


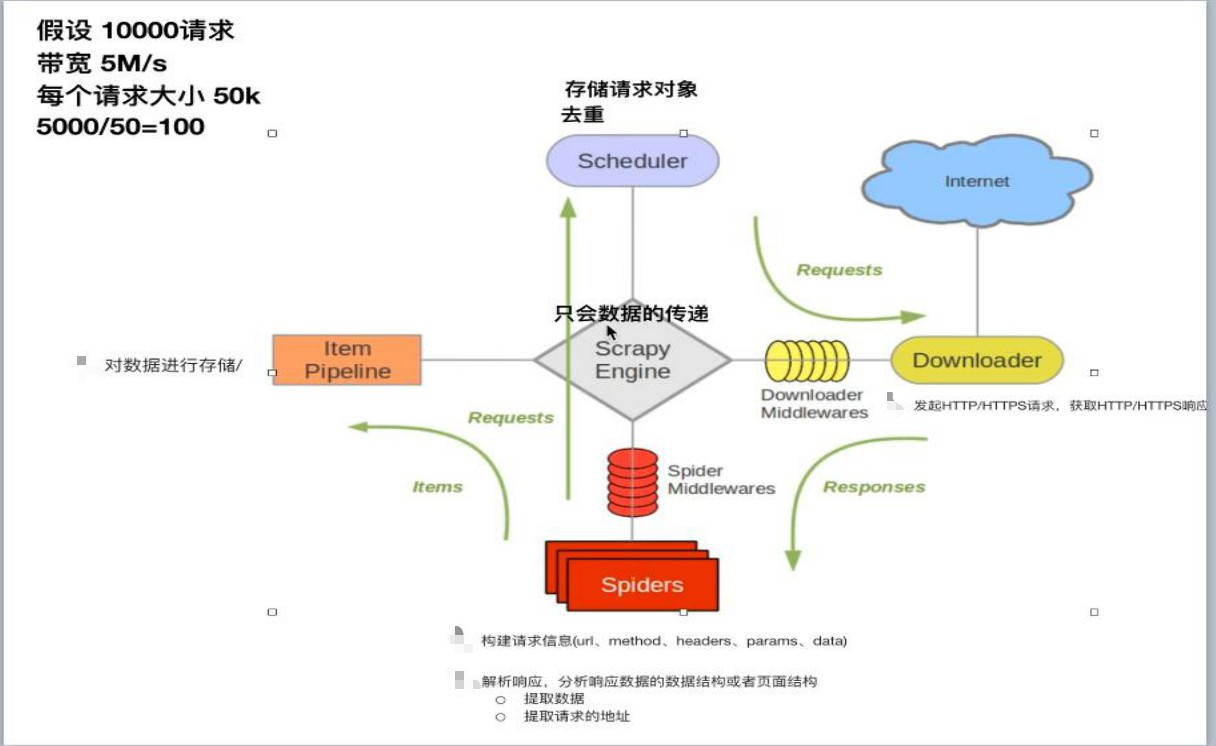
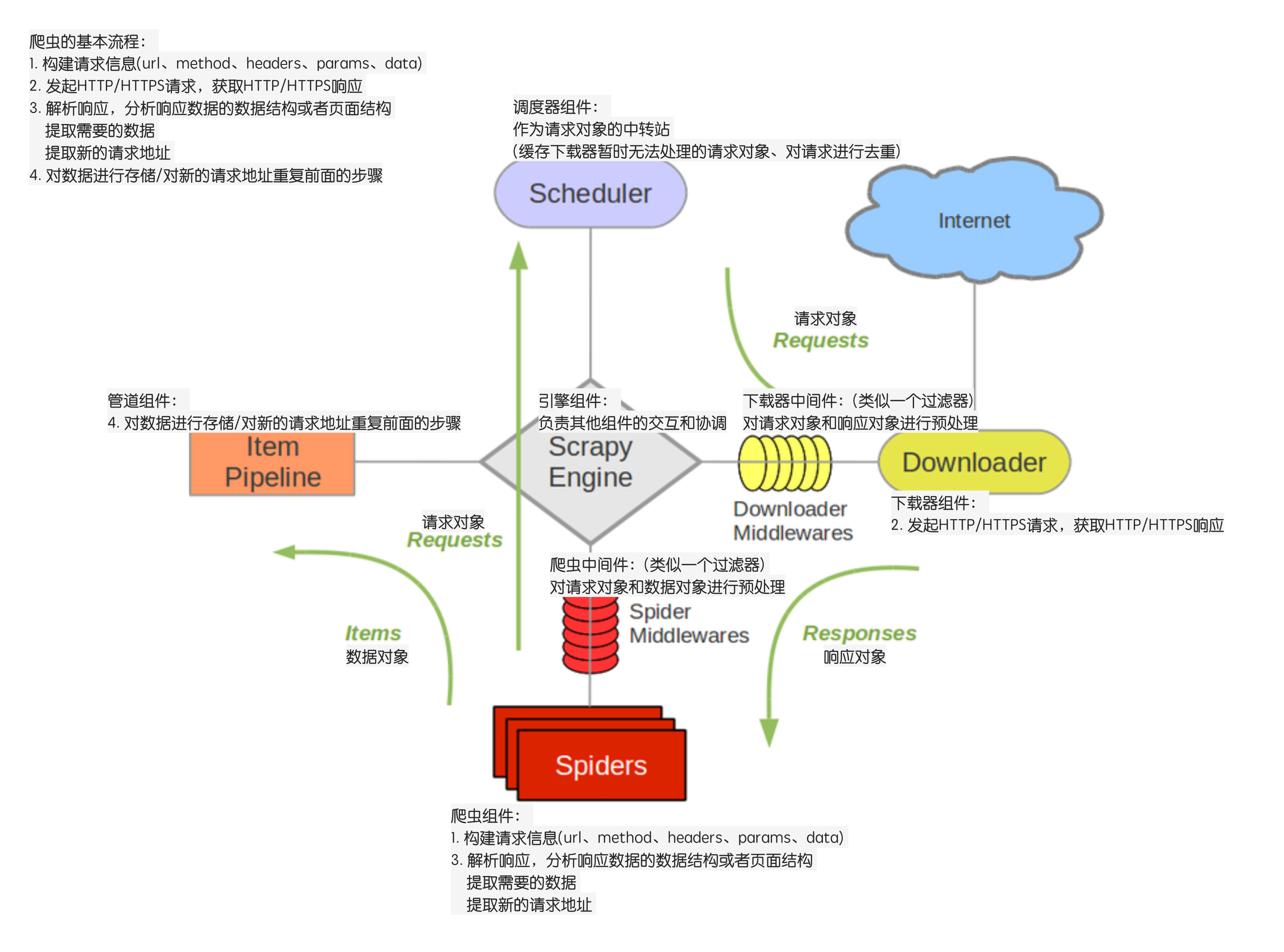
------数字越小,表示离引擎越近,数据越先经过处理,反之 。
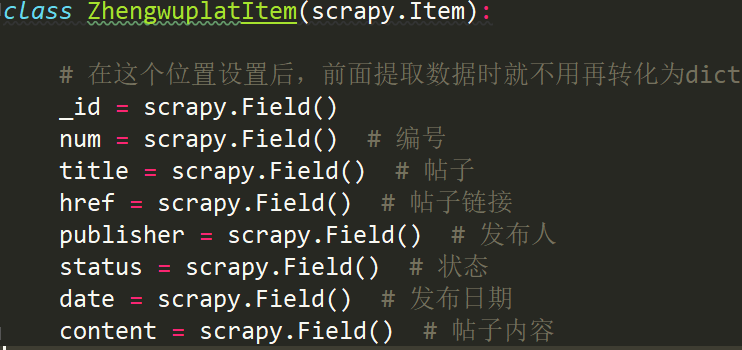
from yanguan.items import YanguanItem
item = YanguanItem() #实例化
参数说明:
括号中的参数为可选参数
callback:表示当前的url的响应交给哪个函数去处理
meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
dont_filter:默认会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
scrapy爬取数据的基本流程及url地址拼接的更多相关文章
- 如何提升scrapy爬取数据的效率
在配置文件中修改相关参数: 增加并发 默认的scrapy开启的并发线程为32个,可以适当的进行增加,再配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100. ...
- 将scrapy爬取数据通过django入到SQLite数据库
1. 在django项目根目录位置创建scrapy项目,django_12是django项目,ABCkg是scrapy爬虫项目,app1是django的子应用 2.在Scrapy的settings.p ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- 42.scrapy爬取数据入库mongodb
scrapy爬虫采集数据存入mongodb采集效果如图: 1.首先开启服务切换到mongodb的bin目录下 命令:mongod --dbpath e:\data\db 另开黑窗口 命令:mongo. ...
- scrapy爬取数据进行数据库存储和本地存储
今天记录下scrapy将数据存储到本地和数据库中,不是不会写,因为小编每次都写觉得都一样,所以记录下,以后直接用就可以了-^o^- 1.本地存储 设置pipel ines.py class Ak17P ...
- scrapy爬取数据保存csv、mysql、mongodb、json
目录 前言 Items Pipelines 前言 用Scrapy进行数据的保存进行一个常用的方法进行解析 Items item 是我们保存数据的容器,其类似于 python 中的字典.使用 item ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 爬虫必知必会(6)_提升scrapy框架爬取数据的效率之配置篇
如何提升scrapy爬取数据的效率:只需要将如下五个步骤配置在配置文件中即可 增加并发:默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_ ...
- 提高Scrapy爬取效率
1.增加并发: 默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100. 2.降低 ...
随机推荐
- DOM的介绍
一 . DOM 介绍 什么是DOM DOM:文档对象模型.DOM 为文档提供了结构化表示,并定义了如何通过脚本来访问文档结构.目的其实就是为了能让js操作html元素而制定的一个规范. DOM就是由节 ...
- B. Two Buttons
这是Codeforces Round #295 (Div. 2) 的B 题,题意为: 给出n, m, 有两种操作,n 减一 和 n 乘以 2,问最少要多少次操作才能把n 变成 m. Sample te ...
- mvn 创建的项目 导入到eclipse
首先,我的工具版本如下: jdk: java version "1.6.0_10-rc2"; maven: apache-maven-3.1.0; eclipse: MyEclip ...
- HDU3247 Resource Archiver —— AC自动机 + BFS最短路 + 状压DP
题目链接:https://vjudge.net/problem/HDU-3247 Resource Archiver Time Limit: 20000/10000 MS (Java/Others) ...
- 城市旅游ppt模板
城市旅游ppt模板,城市,旅游,旅行,休闲. 下载:http://www.huiyi8.com/lvyoumuban/ppt/
- SpringBoot_01_正确、安全地停止SpringBoot应用服务
二.参考资料 1.正确.安全地停止SpringBoot应用服务
- Gym - 101341I:Matrix God(随机算法)
题意:给出N,以及三个矩阵A,B,C,大小都为N*N.问是否满足A*B=C: N<1000: 思路:由于矩阵乘法的复杂度为O(N^3):而部分验证又不能保证结果正确.我们巧妙地利用矩阵乘法的结合 ...
- 作业3rd
第三周作业 课本学习 使用nmap扫描特定靶机 使用nessus扫描特定靶机 靶机网络情况如下 在攻击机使用Nessus,步骤如下 新建一个扫描 填入目的主机ip,点击开始进行扫描 等待 扫描结果如下 ...
- python之系统编程 --进程
1.调试(PDB) 代码: [root@master gaoji]# vim test2.py 1 #!/usr/local/bin/python3 2 # -*- coding:utf-8 -*- ...
- Codeplus2017 12月赛——可做题1
题目:https://www.luogu.org/problemnew/show/P4030 可以发现一个矩阵是巧妙矩阵当且仅当其所有二阶子矩阵都是巧妙矩阵: 将不巧妙的二阶矩阵计为1,维护二维前缀和 ...