【python爬虫】bilibili综合热门页面视频图片爬取
此博客仅作为交流学习
我用python来爬取bilibili综合热门页面视频图片
首先分析页面:
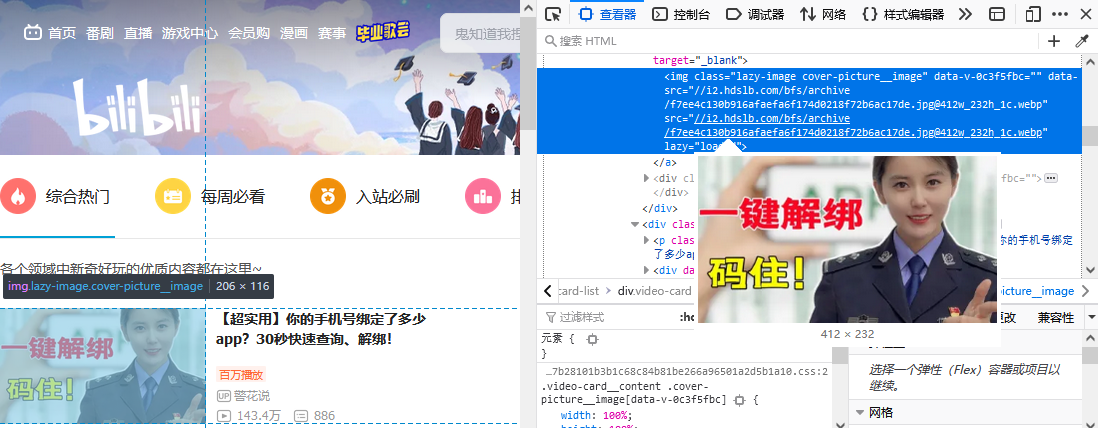
如上图所示,当我们想要在页面爬取图片时,往往得不到页面图片的地址,这时我们也得不到图片
开始抓包分析:
点击Network,CTRL+R开始抓包点击下面页面
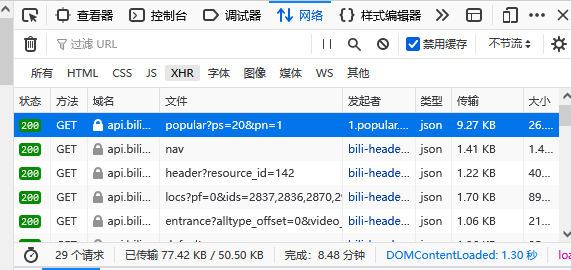
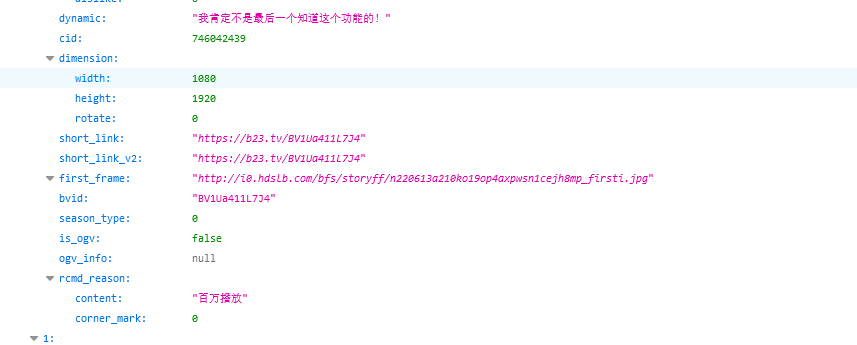
发现页面是json
那么,只要进入当前页面解析并提取页面信息便可以拿到图片地址,进而得到视频封面了
查看响应
发现抓包得到的页面信息有限,只有热门页面的一部分
下拉页面发现

出现了当前页面又一信息链接
那么根据观察发现,只有不断下拉时,页面就会开始加载信息
根据抓包页面链接进行for循环解析页面提取数据并保存信息:
import requests
import pprint
import time for i in range(1,12):
url = 'https://api.bilibili.com/x/web-interface/popular?ps=20&pn=' + str(i)
response = requests.get(url=url)
data = response.json()
#pprint.pprint(data) #将页面内容规范为易懂可视页面
card = data['data']['list']
#print(card)
for card in card:
pic = card.get('pic',None) #图片地址获取
title = card.get('title',None)
# print([pic,title]) imgname = pic.split('/')[-1]
img = requests.get(pic)
with open(imgname, 'wb') as file:
file.write(img.content)
print(imgname)
time.sleep(2)
效果:
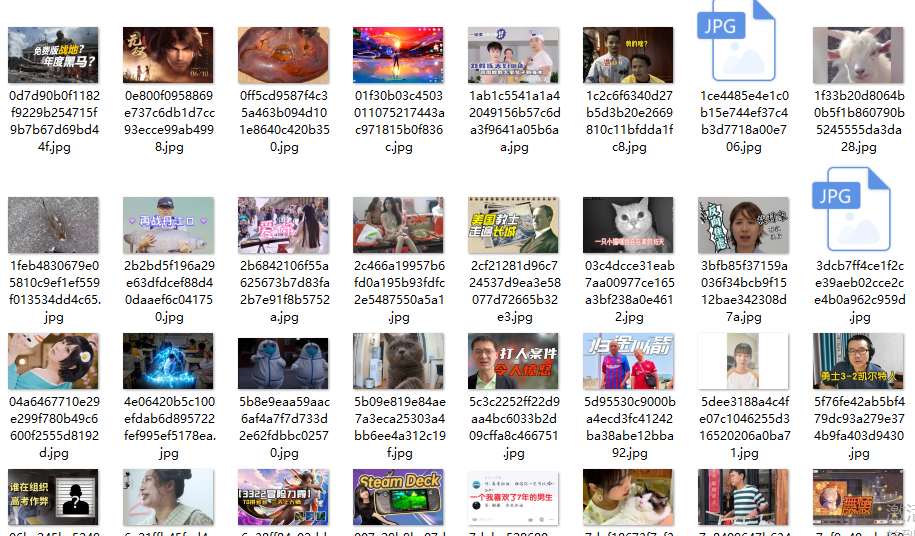
【python爬虫】bilibili综合热门页面视频图片爬取的更多相关文章
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- python爬虫11 | 这次,将带你爬取b站上的NBA形象大使蔡徐坤和他的球友们
在上一篇中 python爬虫10 | 网站维护人员:真的求求你们了,不要再来爬取了!! 小帅b给大家透露了我们这篇要说的牛逼利器 selenium + phantomjs 如果你看了 python爬虫 ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台
网站地址:https://srm.dongfang.com/bid_detail.screen 东方电气采购的页面看似很友好,实际上并不好爬取 在观察网页的审查元素之后发现,1处的网页响应只是单纯的一 ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
随机推荐
- js指南
1.for /in: 与for/of相比,可迭代对象不同,in后面可以是任意对象.数组.字符串.集合和映射可迭代. object.keys() object.values() object.e ...
- Windows11右键改Win10
Win11改Win10右键模式 1.以管理员身份运行CMD控制台 2.在控制台中输入下列代码后回车执行 reg add "HKCU\Software\Classes\CLSID\{86ca1 ...
- 【其他】etcd
配置 node1 name: etcd-1 data-dir: /data/etcd/node1 listen-client-urls: http://127.0.0.1:6701 advertise ...
- PointGNN未修改之前实验结果 ---car
10个epoch中1-4:
- POI给单元格添加超链接(xls,xlsx)
package com.topcheer.html; import java.io.FileOutputStream; import java.io.IOException; import org.a ...
- 2-2 理解const
1 const 在引用中注意不能为常量绑定一个非常量的引用 在指针中区分low-level const和top-level const const通常用于定义常量,一经定义不许修改,且使用const必 ...
- 【读书笔记】排列研究-模式避免-基础Pattern Avoidance
目录 模式避免的定义 避免Pattern q 的n-排列计数\(S_n(q)\) q长度是2 q长度是3 对一些模式q,做\(S_n(q)\)的阶估计 Backelin, West, and Xin给 ...
- android使用---->常用组件1
在TextView中创建空心文字 <TextView android:layout_width="wrap_content" android:layout_height=&q ...
- node-sass与node版本对照图
- LeeCode 91双周赛复盘
T1: 不同的平均值数目 思路:排序 + 双指针 + 哈希存储 public int distinctAverages(int[] nums) { Arrays.sort(nums); Set< ...