Hudi 数据湖的插入,更新,查询,分析操作示例
Hudi 数据湖的插入,更新,查询,分析操作示例
作者:Grey
原文地址:
前置工作
首先,需要先完成
本文基于上述四个环境已经搭建完成的基础上进行 Hudi 数据湖的插入,更新,查询操作。
开发环境
Scala 2.11.8
JDK 1.8
需要熟悉 Maven 构建项目和 Scala 一些基础语法。
操作步骤
master 节点首先启动集群,执行:
stop-dfs.sh && start-dfs.sh
启动 yarn,执行:
stop-yarn.sh && start-yarn.sh
然后准备一个 Mave 项目,在 src/main/resources 目录下,将 Hadoop 的一些配置文件拷贝进来,分别是
$HADOOP_HOME/etc/hadoop/core-site.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
注意,需要在你访问集群的机器上配置 host 文件,这样才可以识别 master 节点。
$HADOOP_HOME/etc/hadoop/hdfs-site.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
$HADOOP_HOME/etc/hadoop/yarn-site.xml 文件,目前还没有任何配置
<?xml version="1.0"?>
<configuration>
</configuration>
然后,设计实体的数据结构,
package git.snippet.entity
case class MyEntity(uid: Int,
uname: String,
dt: String
)
插入数据代码如下
package git.snippet.test
import git.snippet.entity.MyEntity
import git.snippet.util.JsonUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object DataInsertion {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
insertData(sparkSession)
}
def insertData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/mydata/data1")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = JsonUtil.getJsonData(item.getString(0))
MyEntity(jsonObject.getIntValue("uid"), jsonObject.getString("uname"), jsonObject.getString("dt"))
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid"))
.withColumn("hudipart", col("dt")) //增加hudi分区列
result.write.format("org.apache.hudi")
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.upsert.shuffle.parallelism", 2)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "myDataTable")
.option("hoodie.datasource.write.partitionpath.field", "hudipart") //分区列
.mode(SaveMode.Overwrite)
.save("/snippet/data/hudi")
}
}
然后,在 master 节点先准备好数据
vi data1
输入如下数据
{'uid':1,'uname':'grey','dt':'2022/09'}
{'uid':2,'uname':'tony','dt':'2022/10'}
然后创建文件目录,
hdfs dfs -mkdir /mydata/
把 data1 放入目录下
hdfs dfs -put data1 /mydata/
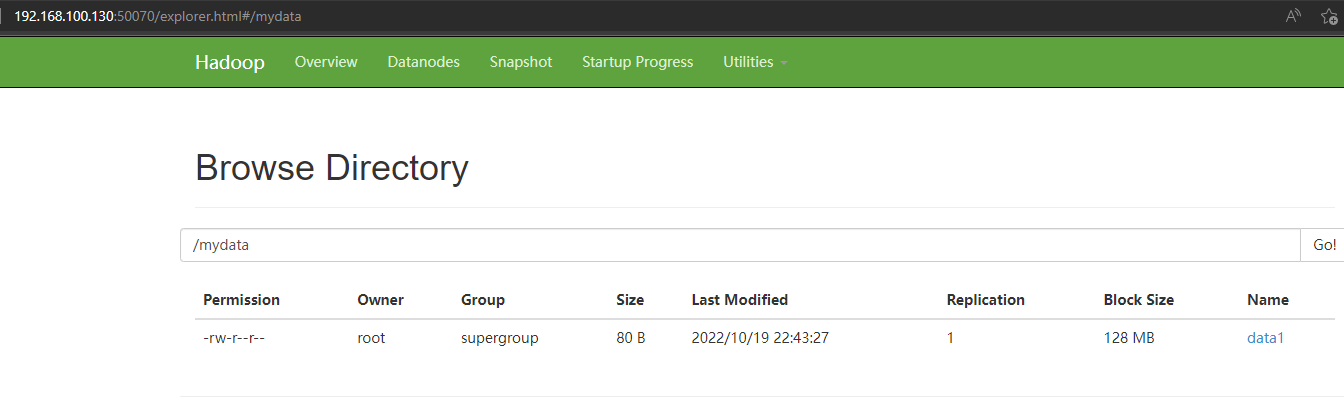
访问:http://192.168.100.130:50070/explorer.html#/mydata
可以查到这个数据
接下来执行插入数据的 scala 代码,执行完毕后,验证一下
访问:http://192.168.100.130:50070/explorer.html#/snippet/data/hudi/2022
可以查看到插入的数据

准备一个 data2 文件
cp data1 data2 && vi data2
data2 的数据更新为
{'uid':1,'uname':'grey1','dt':'2022/11'}
{'uid':2,'uname':'tony1','dt':'2022/12'}
然后执行
hdfs dfs -put data2 /mydata/
更新数据的代码,我们可以做如下调整,完整代码如下
package git.snippet.test
import git.snippet.entity.MyEntity
import git.snippet.util.JsonUtil
import org.apache.hudi.{DataSourceReadOptions, DataSourceWriteOptions}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object DataUpdate {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
updateData(sparkSession)
}
def updateData(sparkSession: SparkSession) = {
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val commitTime = System.currentTimeMillis().toString //生成提交时间
val df = sparkSession.read.text("/mydata/data2")
.mapPartitions(partitions => {
partitions.map(item => {
val jsonObject = JsonUtil.getJsonData(item.getString(0))
MyEntity(jsonObject.getIntValue("uid"), jsonObject.getString("uname"), jsonObject.getString("dt"))
})
})
val result = df.withColumn("ts", lit(commitTime)) //添加ts 时间戳列
.withColumn("uuid", col("uid")) //添加uuid 列
.withColumn("hudipart", col("dt")) //增加hudi分区列
result.write.format("org.apache.hudi")
// .option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.upsert.shuffle.parallelism", 2)
.option("PRECOMBINE_FIELD_OPT_KEY", "ts") //指定提交时间列
.option("RECORDKEY_FIELD_OPT_KEY", "uuid") //指定uuid唯一标示列
.option("hoodie.table.name", "myDataTable")
.option("hoodie.datasource.write.partitionpath.field", "hudipart") //分区列
.mode(SaveMode.Append)
.save("/snippet/data/hudi")
}
}
执行更新数据的代码。
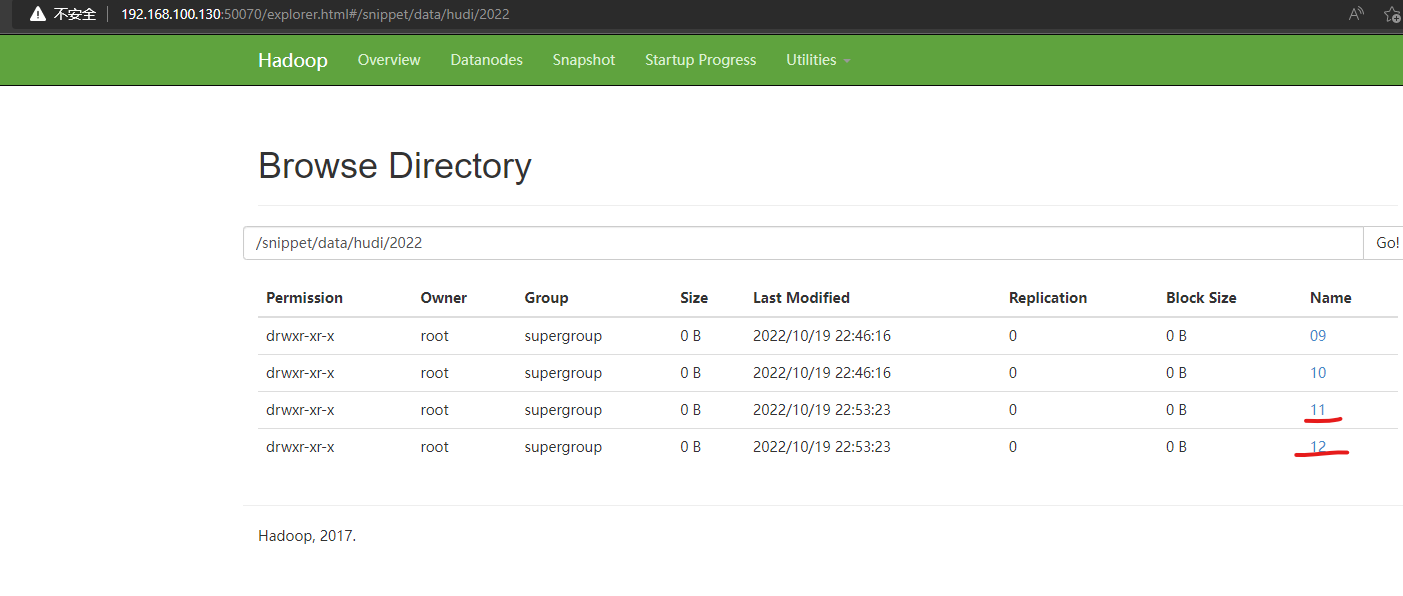
验证一下,访问:http://192.168.100.130:50070/explorer.html#/snippet/data/hudi/2022
可以查看到更新的数据情况
数据查询的代码也很简单,完整代码如下
package git.snippet.test
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DataQuery {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("MyFirstDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val ssc = sparkSession.sparkContext
ssc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
queryData(sparkSession)
}
def queryData(sparkSession: SparkSession) = {
val df = sparkSession.read.format("org.apache.hudi")
.load("/snippet/data/hudi/*/*")
df.show()
println(df.count())
}
}
执行,输出以下信息,验证成功。

数据查询也支持很多查询条件,比如增量查询,按时间段查询等。
接下来是 flink 实时数据分析的服务,首先需要在 master 上启动 kafka,并创建 一个名字为 mytopic 的 topic,详见Linux 下搭建 Kafka 环境
相关命令如下
创建topic
kafka-topics.sh --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --create --topic mytopic
生产者启动配置
kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic mytopic
消费者启动配置
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic mytopic
然后运行如下代码
package git.snippet.analyzer;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class DataAnalyzer {
public static void main(String[] args) {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.100.130:9092");
properties.setProperty("group.id", "snippet");
//构建FlinkKafkaConsumer
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>("mytopic", new SimpleStringSchema(), properties);
//指定偏移量
myConsumer.setStartFromLatest();
final DataStream<String> stream = env.addSource(myConsumer);
env.enableCheckpointing(5000);
stream.print();
try {
env.execute("DataAnalyzer");
} catch (Exception e) {
e.printStackTrace();
}
}
}
其中
properties.setProperty("bootstrap.servers", "192.168.100.130:9092");
根据自己的配置调整,然后通过 kakfa 的生产者客户端输入一些数据,这边可以收到这个数据,验证完毕。
完整代码见
Hudi 数据湖的插入,更新,查询,分析操作示例的更多相关文章
- Apache Hudi数据跳过技术加速查询高达50倍
介绍 在 Hudi 0.10 中,我们引入了对高级数据布局优化技术的支持,例如 Z-order和希尔伯特空间填充曲线(作为新的聚类算法),即使在经常使用过滤器查询大表的复杂场景中,也可以在多个列而非单 ...
- C 线性表的链式存储实现及插入、删除等操作示例
一.链式存储的优势 线性表的存储可以通过顺序存储或链式存储实现,其中顺序存储基于数组实现(见本人上一篇博客),在进行插入删除等操作时,需对表内某一部分元素逐个移动,效率较低.而链式结构不依赖于地址连续 ...
- C 线性表的顺序存储实现及插入、删除等操作示例
一.线性表的定义 线性表(Linear List)是由同一类型元素构成的有序序列的线性结构.线性表中元素的个数称为线性表的长度:线性表内没有元素(长度为0)时,称为空表:表的起始位置称为表头,表的结束 ...
- 使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入 大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的.遵循的基本原则之一是文件的"一次写入多次读取"访问模型.这对于处理 ...
- 数据湖框架选型很纠结?一文了解Apache Hudi核心优势
英文原文:https://hudi.apache.org/blog/hudi-indexing-mechanisms/ Apache Hudi使用索引来定位更删操作所在的文件组.对于Copy-On-W ...
- 使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主 ...
- Apache Hudi:云数据湖解决方案
1. 引入 开源Apache Hudi项目为Uber等大型组织提供流处理能力,每天可处理数据湖上的数十亿条记录. 随着世界各地的组织采用该技术,Apache开源数据湖项目已经日渐成熟. Apache ...
- 印度最大在线食品杂货公司Grofers的数据湖建设之路
1. 起源 作为印度最大的在线杂货公司的数据工程师,我们面临的主要挑战之一是让数据在整个组织中的更易用.但当评估这一目标时,我们意识到数据管道频繁出现错误已经导致业务团队对数据失去信心,结果导致他们永 ...
- 构建数据湖上低延迟数据 Pipeline 的实践
T 摘要 · 云原生与数据湖是当今大数据领域最热的 2 个话题,本文着重从为什么传统数仓 无法满足业务需求? 为何需要建设数据湖?数据湖整体技术架构.Apache Hudi 存储模式与视图.如何解决冷 ...
随机推荐
- 完成 DolphinScheduler 新手任务赢好礼活动 | 倒计时3 天
想轻松参与 DolphinScheduler 项目贡献吗? 想获得 500 元京东购物卡吗? 参与活动,有机会得更多活动奖励! 活动截止至6月30日 了解更多详情: 在你参与 DolphinSched ...
- Linux 06 用户组管理
参考源 https://www.bilibili.com/video/BV187411y7hF?spm_id_from=333.999.0.0 版本 本文章基于 CentOS 7.6 概述 每个用户都 ...
- Ceph 块存储 创建的image 映射成块设备
将创建的volume1映射成块设备 [root@mysql-server ceph]# rbd map rbd_pool/volume1 rbd: sysfs write failed RBD ima ...
- 048_末晨曦Vue技术_处理边界情况之使用$root访问根实例
处理边界情况之使用$root访问根实例 点击打开视频教程 在每个 new Vue 实例的子组件中,其根实例可以通过 $root property 进行访问. 例如,在这个根实例中: src\main. ...
- 【NOI P模拟赛】最短路(树形DP,树的直径)
题面 给定一棵 n n n 个结点的无根树,每条边的边权均为 1 1 1 . 树上标记有 m m m 个互不相同的关键点,小 A \tt A A 会在这 m m m 个点中等概率随机地选择 k k k ...
- CF1019B The hat (二分)
题面 题解 如果位置为i的人与对面的差是x,i+1位置由于只能+1或-1,所以i+1位置与对面的差就是x.x+2或x-2,可以发现,奇偶性不变. 所以只要判断出是奇差,就可以直接输出"! - ...
- 【Java】学习路径51-线程组
平时创建线程的时候,系统会默认为线程分组. 我们可以使用 ThreadGroup tg1 = t1.getThreadGroup(); 取得t1的线程组对象. 然后使用getName获得线程组名称. ...
- Eclipse配置Tomcat搭建java Web (JSP)开发环境
配置Tomcat服务 1.打开窗口-首选项-Server-Runtiome Environments 2.点击ADD,选择对应的Tomcat版本,点击下一步 路径选择Tomcat解压后的文件夹目录,点 ...
- 在UniApp的H5项目中,生成二维码和扫描二维码的操作处理
在我们基于UniApp的H5项目中,需要生成一些二维码进行展示,另外也需要让用户可以扫码进行一定的快捷操作,本篇随笔介绍一下二维码的生成处理和基于H5的扫码进行操作.二维码的生成,使用了JS文件wea ...
- 记Mybatis动态sql
目录 记MyBatis动态SQL 1.< SQL >标签 2.< if >标签 3.分支标签 1.第一种:用在查询条件上用choose-when:otherwise可不要 2. ...