scrapy--selenium(二)
今天学习了很多,还是想给大家讲一讲正题:scrapy的动态加载AJax的网页爬取:selenium。让我们开始
三: 针对大型电商网站:京东网,因为比较有代表性,爬出来有点小成就。先给大家看下效果图。好让大家有点动力QAQ

一: 查看一下京东网加载商品的原理
1.1:将该网页加载的所有商品信息放入<li class="seckill_mod_goods">...</li>

1.2:获取网页源码,可以清楚的知道--无法在源码中找到商品信息所在的<li>...</li>标签

1.3: 那么现在问题来了,这些商品信息是从哪里加载出来的呢?那就是这次要将的Ajax动态加载信息,可以打开网页的审查元素,点击network,f5刷新,可以找到script类型的脚本
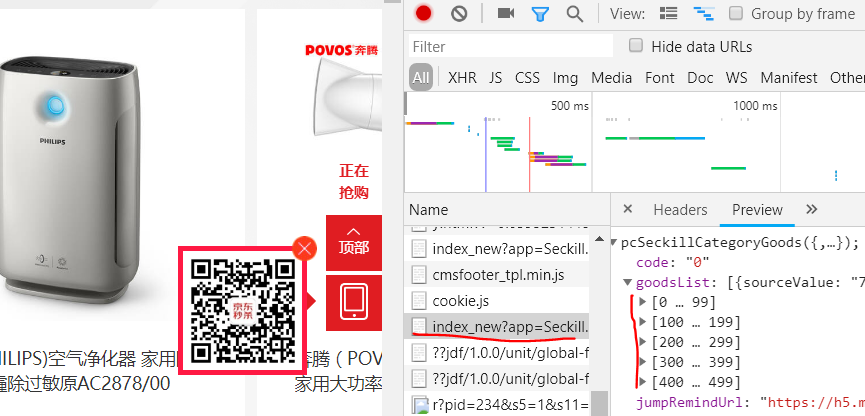
就是上图用红线画出来的script文件,查看中有[0..499]500个商品信息
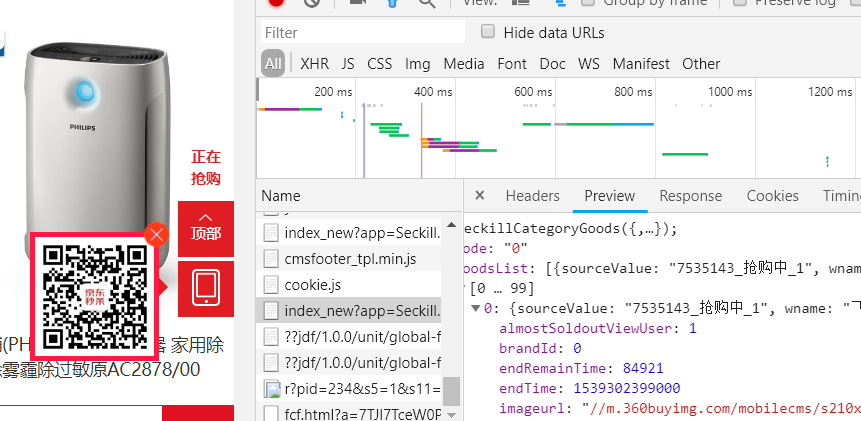
二: 了解了基本原理,再来看看源代码,就能很容易知道原理了__selenimu.py
#-*- coding:utf-8 -*-
import time
from selenium import webdriver
import pdb
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from lxml import etree
import re
from bs4 import BeautifulSoup chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options) # 请求京东页面
driver.get(
"https://miaosha.jd.com/category.html?cate_id=19")
time.sleep(3) img_list = []
# 逐渐滚动浏览器窗口,令ajax逐渐加载 for i in range(1,200):
js = ("var q=document.documentElement.scrollTop=" + str(300 * i)) # 谷歌 和 火狐
driver.execute_script(js)
time.sleep(0.3) # 拿到页面源码
html = etree.HTML(driver.page_source)
all_img_list = [] # 得到所有图片
img_group_list = html.xpath("//*[@class='seckill_mod_goods_link_img']/@src") # 收集所有图片链接到列表 for img_group in img_group_list:
img_of_group = re.findall(r'.*q70\.jpg$',img_group)
all_img_list.append(img_of_group) with open('vip.txt', 'w') as f:
#pdb.set_trace()
for img_list_item in all_img_list:
if img_list_item[0]:
f.write(img_list_item[0]+'\n')
else:
driver.quit()
# 退出浏览器
driver.quit()
scrapy--selenium(二)的更多相关文章
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- 使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面 查看源代码你会发现 全是js代码,说明今日头条的内容是通过js动态生成的. 用火狐浏览器F12查看得知 ...
- Scrapy+selenium爬取简书全站
Scrapy+selenium爬取简书全站 环境 Ubuntu 18.04 Python 3.8 Scrapy 2.1 爬取内容 文字标题 作者 作者头像 发布日期 内容 文章连接 文章ID 思路 分 ...
- python之scrapy篇(二)
一.创建工程 scarpy startproject xxx 二.编写iteam文件 # -*- coding: utf-8 -*- # Define here the models for your ...
- scrapy selenium 登陆zhihu
# -*- coding: utf-8 -*- # 导入依赖包 import scrapy from selenium import webdriver import time import json ...
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- 使用scrapy+selenium爬取淘宝网
--***2019-3-27测试有效***---- 第一步: 打开cmd,输入scrapy startproject taobao_s新建一个项目. 接着cd 进入我们的项目文件夹内输入scrapy ...
- python3.5以及scrapy,selenium,等 安装
一.python3.5安装和配置 在安装的时候无意间发现了,python3.6没有给我自定义安装的机会,直接就C盘见:因此我选择了python3.5.<安装部分跳过,至于一条吃过痛苦的建议:不要 ...
- java selenium (二) 环境搭建方法一
webdriver 就是selenium 2. webdriver 是一款优秀的,开源的,自动化测试框架. 支持很多语言. 本文描述的是用java Eclipse 如何搭建环境 阅读目录 ...
- scrapy + selenium 的动态爬虫
动态爬虫 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会 ...
随机推荐
- POJ 3660—— Cow Contest——————【Floyd传递闭包】
Cow Contest Time Limit:1000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u Submit ...
- grunt项目构建
最近想把项目里添加grunt,说白了就是前端自动化管理,具体配置如下: 用到以下几个部件: grunt-contrib-cssmin grunt-contrib-uglify grunt-contri ...
- CSS列表(新闻列表、导航条)常见写法
以下面这个UL做演示 <ul> <li><a href="#"><span>2014-4-1</span>教育</ ...
- svg用作背景图
svg用做背景图的几种方式 1. 直接使用 background: url('data:image/svg+xml;charset=utf-8,<svg width="10" ...
- npm下载某个版本
如果我想要引入的是Jquery的1.7.2版本,则输入npm intall jquery@1.7.2,那么npm包管理器就会帮助你下载jquery1.7.2的版本到你当前操作目录下的node_modu ...
- window系统安装jdk,jre
java开发少不了安装jdk.当然如果只是想运行其他人的java项目,只需要安装jre就行了,不需要安装jdk,jdk是编译用的.jdk可以同时安装多个 版本,只需要在项目部署时注意切换版本选择.在这 ...
- c++ 处理utf-8字符串
c++的字符串中的每一个元素都是一个字节.所以在装入utf8字符串的时候,其实是按照一定的规则编码的. 字符的8位中 如果0开头 则自己就是一个单位. 1字节 0xxxxxxx 2字节 110xxx ...
- May 04th 2017 Week 18th Thursday
No matter how far you may fly, never forget where you come from. 无论你能飞多远,都别忘了你来自何方. I never forget w ...
- Python 类的高级属性(可选)
1.slots实例:限制类的实例有合法的属性集,只有__slots__属性列表中的属性才可能成为实例属性. 对象的实例通常没有一个属性字典,可以在__slots__列表中包含一个属性字典__dict_ ...
- Jmeter入门4 添加断言 判断响应数据是否符合预期
发出请求之后,通过添加断言可以判断响应数据是否是我们的预期结果. 1 在Jmeter中发送一个登录的http请求(参数故意输入错误).结果肯定是登陆失败啦. 但结果树中http请求的图标显示‘绿色’表 ...