使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面
查看源代码你会发现

全是js代码,说明今日头条的内容是通过js动态生成的。
用火狐浏览器F12查看得知
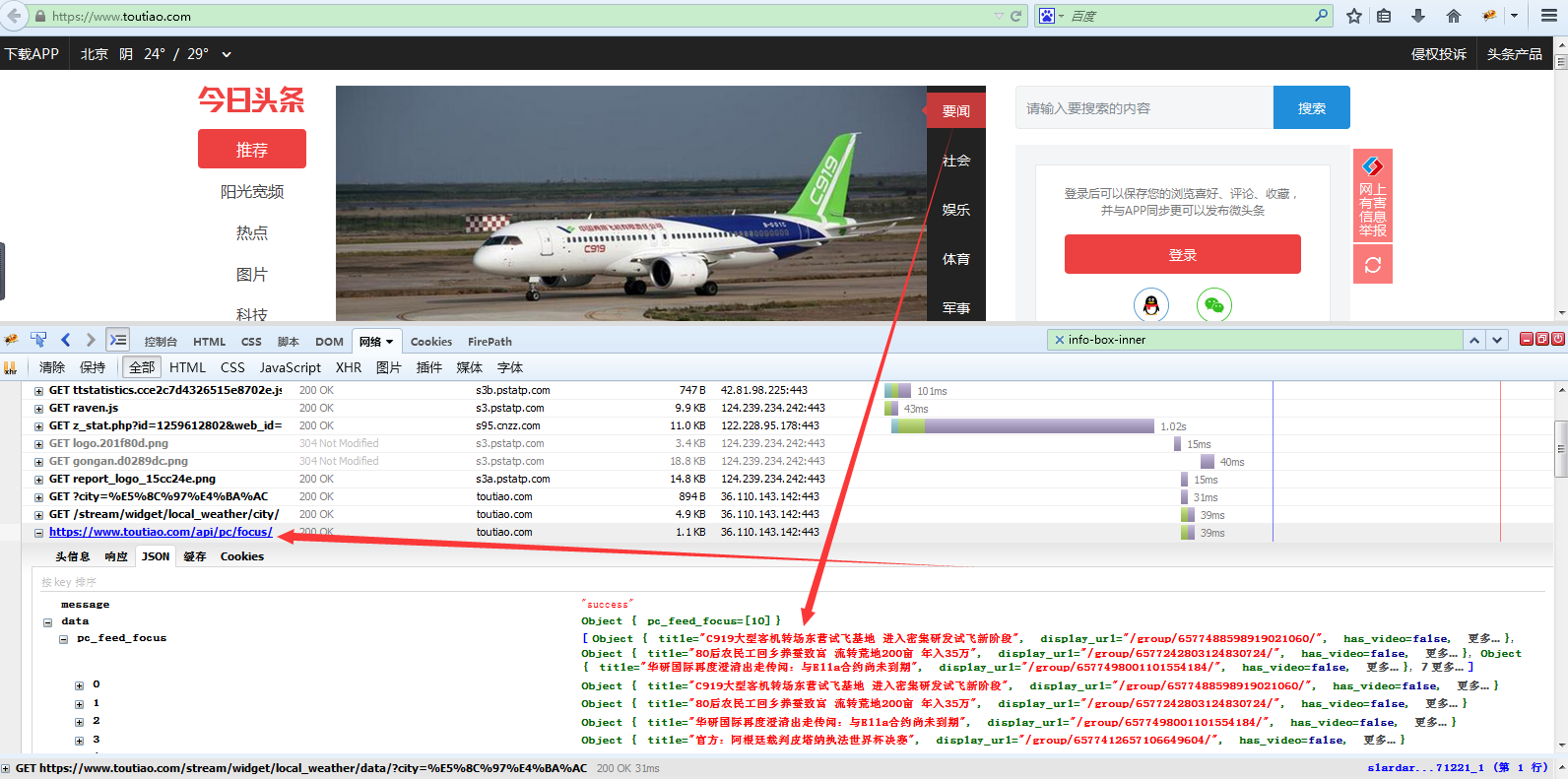
得到了今日头条的推荐新闻的接口地址:https://www.toutiao.com/api/pc/focus/
单独访问这个地址得到
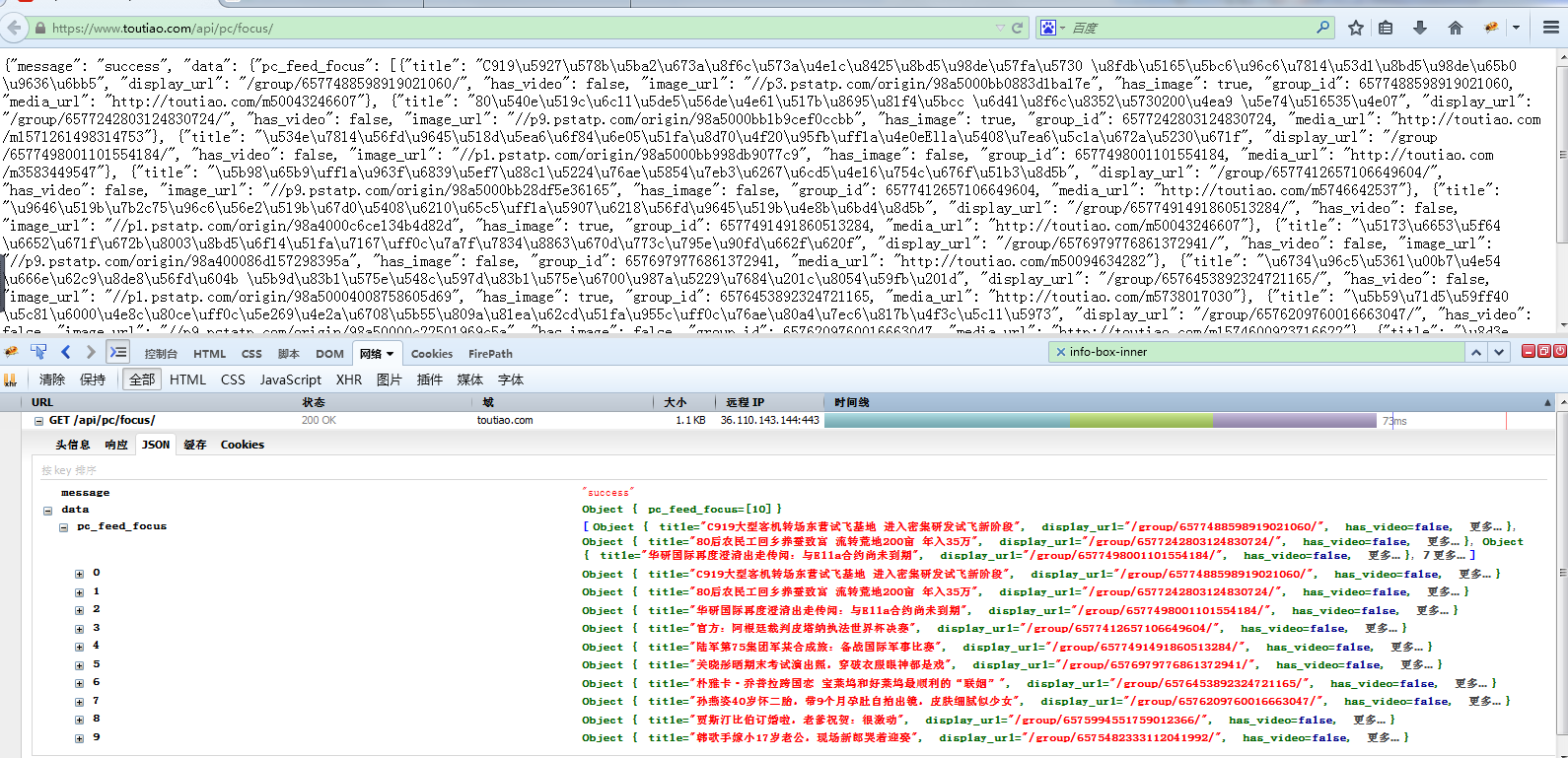
此接口得到的数据格式为json数据
我们用scrapy+selenium+PhantomJS的方式获取今日头条推荐的内容
下面是是scrapy中最核心的代码,位于spiders中的toutiao_example.py
# -*- coding: utf-8 -*-
import scrapy
import json
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
import re class ToutiaoExampleSpider(scrapy.Spider):
name = 'toutiao_example'
allowed_domains = ['toutiao.com']
start_urls = ['https://www.toutiao.com/api/pc/focus/'] ###今日头条焦点的api接口
def parse(self, response):
conten_json=json.loads(response.text)
conten_news=conten_json['data'] ###从json数据中抽取data字段数据,其中data字段数据里面包含了pc_feed_focus这个字段,其中这个字段包含了:新闻的标题title,链接url等信息
for aa in conten_news['pc_feed_focus']:
title=aa['title']
link_url='https://www.toutiao.com'+aa['display_url'] ###如果写(www.toutiao.com'+aa['display_url'])会报错,加上https://,(https://www.toutiao.com'+aa['display_url'])则不会报错!
link_url_new=link_url.replace('group/','a')###把链接https://www.toutiao.com/group/6574248586484122126/,放到浏览器中,地址会自动变成https://www.toutiao.com/a6574248586484122126/这个。所以我们需要把group/ 替换成a yield scrapy.Request(link_url_new, callback=self.next_parse) def next_parse(self, response): dcap = dict(DesiredCapabilities.PHANTOMJS) # 设置useragent信息
dcap['phantomjs.page.settings.userAgent'] = (
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0 ') # 根据需要设置具体的浏览器信息
driver = webdriver.PhantomJS(desired_capabilities=dcap) #封装浏览器信息) # 指定使用的浏览器, #driver.set_page_load_timeout(5) # 设置超时时间
driver.get(response.url)##使用浏览器请求页面 time.sleep(3)#加载3秒,等待所有数据加载完毕 title=driver.find_element_by_class_name('title').text ###.text获取元素的文本数据
content1=driver.find_element_by_class_name('abstract-index').text###.text获取元素的文本数据
content2=driver.find_element_by_class_name('abstract').text###.text获取元素的文本数据 content=content1+content2 print(title,content,6666666666666666)
driver.close() #data = driver.page_source# 获取网页文本
#driver.save_screenshot('1.jpg') # 系统截图保存
运行代码我们得到结果为标题加内容呈现方式如下

使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)的更多相关文章
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- Python 爬虫爬取今日头条街拍上的图片
# 今日头条--街拍 import requests from urllib.parse import urlencode import os from hashlib import md5 from ...
- 使用python-aiohttp爬取今日头条
http://blog.csdn.net/u011475134/article/details/70198533 原出处 在上一篇文章<使用python-aiohttp爬取网易云音乐>中, ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- 爬虫七之分析Ajax请求并爬取今日头条
爬取今日头条图片 这里只讨论出现的一些问题,代码在最下面github链接里. 首先,今日头条取消了"图集"这一选项,因此对于爬虫来说效率降低了很多: 在所有代码都完成后,也许是爬取 ...
- Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
随机推荐
- java+testng接口测试入门
testNG是一个测试框架,它能组织测试用例按照你想要的方式进行运行,并输出一定格式的便于阅读的测试报告(结果),通过java+testng的方式说明一下接口测试的基本使用方法. 一.环境搭建 a)千 ...
- 自然人税收管理系统扣缴客户端Sqlite数据库有密码的,如何破解读取呢
https://www.cnblogs.com/Charltsing/p/EPPortal.html 有人问我能不能直接读自然人税收管理系统扣缴客户端,因为需要导出数据做处理. 看了一下,这个客户端是 ...
- Make a Person 闭包
用下面给定的方法构造一个对象. 方法有 getFirstName(), getLastName(), getFullName(), setFirstName(first), setLastName(l ...
- Python_range
range 当作定义的数字范围列表. 满足顾头不顾腚,可以加步长,与for循环结合使用. 一般使用 for i in range(0, 101): print(i) 结果: #[0,1,2,3,... ...
- Python百题计划
一.基础篇 想要像类似执行shell脚本一样执行Python脚本,需要在py文件开头加上什么?KEY:#!/usr/bin/env python Python解释器在加载 .py 文件中的代码时,会对 ...
- 原生sql整理
mysql -uroot -p #登录mysql命令password: #输入密码 mysql> #每条mysql命令后面都要加分号结尾show databases; #打印整个mysql数据库 ...
- 编译安装MySQL5.6失败的相关问题解决方案
Q0:需要安装git 解决方案: #CentOS yum install git #ubuntu apt-get install git Q1:CMAKE_CXX_COMPILER could be ...
- JAVA反射优化
****************** 转自 https://my.oschina.net/19921228/blog/3042643 *********************** 比较反射与正常实例 ...
- 搭建一个MP-demo(mybatis_plus)
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发.提高效率而生. 搭建一个简单的MP-demo 1.配置pom.xml ...
- MCMC算法解析
MCMC算法的核心思想是我们已知一个概率密度函数,需要从这个概率分布中采样,来分析这个分布的一些统计特性,然而这个这个函数非常之复杂,怎么去采样?这时,就可以借助MCMC的思想. 它与变分自编码不同在 ...