POJ3415 Common Substrings —— 后缀数组 + 单调栈 公共子串个数
题目链接:https://vjudge.net/problem/POJ-3415
| Time Limit: 5000MS | Memory Limit: 65536K | |
| Total Submissions: 12240 | Accepted: 4144 |
Description
A substring of a string T is defined as:
T(i, k)=TiTi+1...Ti+k-1, 1≤i≤i+k-1≤|T|.
Given two strings A, B and one integer K, we define S, a set of triples (i, j, k):
S = {(i, j, k) | k≥K, A(i, k)=B(j, k)}.
You are to give the value of |S| for specific A, B and K.
Input
The input file contains several blocks of data. For each block, the first line contains one integer K, followed by two lines containing strings A and B, respectively. The input file is ended by K=0.
1 ≤ |A|, |B| ≤ 105
1 ≤ K ≤ min{|A|, |B|}
Characters of A and B are all Latin letters.
Output
For each case, output an integer |S|.
Sample Input
2
aababaa
abaabaa
1
xx
xx
0
Sample Output
22
5
Source
题意:
给出两个字符串,求有多少对长度不小于k的公共子串,子串相同但位置不同也单独算作一对。
题解:
1.将两个字符串拼接在一起,中间用分隔符隔开,得到新串。并且需要记录每个位置上的字符(后缀)属于哪一个字符串。
2.求出新串的后缀数组。可知sa[i]和sa[j]的最长公共前缀为:min(height[k])i+1<=k<=j。
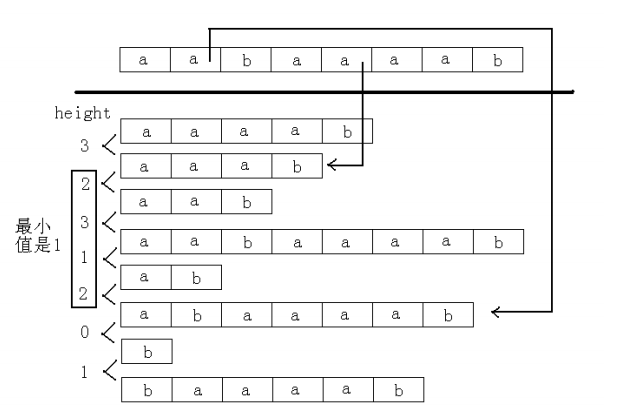
3.根据第二点,可以枚举sa数组,当遇到A串时,就先放着,当遇到B串时,就往前统计与所有A串的最长公共前缀,假如为len,那么就能增加len-k+1个公共前缀了。由于是按着sa的顺序枚举下去的,所以对于在B串下面的A串是没有统计到的,所以需要二次统计:把A串当成B串, B串当成A串,然后再进行统计,方可无遗漏。
4.往前统计时需要用到单调栈。
代码如下:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <vector>
#include <cmath>
#include <queue>
#include <stack>
#include <map>
#include <string>
#include <set>
using namespace std;
typedef long long LL;
const int INF = 2e9;
const LL LNF = 9e18;
const int MOD = 1e9+;
const int MAXN = 2e5+; int id[MAXN];
int r[MAXN], sa[MAXN], Rank[MAXN], height[MAXN];
int t1[MAXN], t2[MAXN], c[MAXN]; bool cmp(int *r, int a, int b, int l)
{
return r[a]==r[b] && r[a+l]==r[b+l];
} void DA(int str[], int sa[], int Rank[], int height[], int n, int m)
{
n++;
int i, j, p, *x = t1, *y = t2;
for(i = ; i<m; i++) c[i] = ;
for(i = ; i<n; i++) c[x[i] = str[i]]++;
for(i = ; i<m; i++) c[i] += c[i-];
for(i = n-; i>=; i--) sa[--c[x[i]]] = i;
for(j = ; j<=n; j <<= )
{
p = ;
for(i = n-j; i<n; i++) y[p++] = i;
for(i = ; i<n; i++) if(sa[i]>=j) y[p++] = sa[i]-j; for(i = ; i<m; i++) c[i] = ;
for(i = ; i<n; i++) c[x[y[i]]]++;
for(i = ; i<m; i++) c[i] += c[i-];
for(i = n-; i>=; i--) sa[--c[x[y[i]]]] = y[i]; swap(x, y);
p = ; x[sa[]] = ;
for(i = ; i<n; i++)
x[sa[i]] = cmp(y, sa[i-], sa[i], j)?p-:p++; if(p>=n) break;
m = p;
} int k = ;
n--;
for(i = ; i<=n; i++) Rank[sa[i]] = i;
for(i = ; i<n; i++)
{
if(k) k--;
j = sa[Rank[i]-];
while(str[i+k]==str[j+k]) k++;
height[Rank[i]] = k;
}
} int Stack[MAXN][], top;
LL cal(int k, int len, int flag)
{
LL sum = , tmp = ;
top = ;
for(int i = ; i<=len; i++)
{
if(height[i]<k)
tmp = top = ;
else
{
int cnt = ;
if(id[sa[i-]]==flag)
tmp += height[i]-k+, cnt++;
while(top> && height[i]<=Stack[top-][])
{
tmp -= 1LL*Stack[top-][]*(Stack[top-][]-height[i]);
cnt += Stack[top-][];
top--;
}
Stack[top][] = height[i];
Stack[top++][] = cnt;
if(id[sa[i]]!=flag)
sum += tmp;
}
}
return sum;
} char str[MAXN];
int main()
{
int k;
while(scanf("%d",&k)&&k)
{
int len = ;
scanf("%s", str);
int LEN = strlen(str);
for(int j = ; j<LEN; j++)
{
r[len] = str[j];
id[len++] = ;
}
r[len] = '$';
id[len++] = ;
scanf("%s", str);
LEN = strlen(str);
for(int j = ; j<LEN; j++)
{
r[len] = str[j];
id[len++] = ;
}
r[len] = ;
DA(r,sa,Rank,height,len,);
cout<< cal(k,len,)+cal(k,len,) <<endl;
}
}
POJ3415 Common Substrings —— 后缀数组 + 单调栈 公共子串个数的更多相关文章
- POJ3415 Common Substrings(后缀数组 单调栈)
借用罗穗骞论文中的讲解: 计算A 的所有后缀和B 的所有后缀之间的最长公共前缀的长度,把最长公共前缀长度不小于k 的部分全部加起来.先将两个字符串连起来,中间用一个没有出现过的字符隔开.按height ...
- poj 3415 Common Substrings 后缀数组+单调栈
题目链接 题意:求解两个字符串长度 大于等于k的所有相同子串对有多少个,子串可以相同,只要位置不同即可:两个字符串的长度不超过1e5; 如 s1 = "xx" 和 s2 = &qu ...
- poj 3415 Common Substrings——后缀数组+单调栈
题目:http://poj.org/problem?id=3415 因为求 LCP 是后缀数组的 ht[ ] 上的一段取 min ,所以考虑算出 ht[ ] 之后枚举每个位置作为右端的贡献. 一开始想 ...
- poj 3415 Common Substrings —— 后缀数组+单调栈
题目:http://poj.org/problem?id=3415 先用后缀数组处理出 ht[i]: 用单调栈维护当前位置 ht[i] 对之前的 ht[j] 取 min 的结果,也就是当前的后缀与之前 ...
- poj3415 Common Substrings (后缀数组+单调队列)
Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 9414 Accepted: 3123 Description A sub ...
- SPOJ - SUBST1 New Distinct Substrings —— 后缀数组 单个字符串的子串个数
题目链接:https://vjudge.net/problem/SPOJ-SUBST1 SUBST1 - New Distinct Substrings #suffix-array-8 Given a ...
- 【BZOJ-3238】差异 后缀数组 + 单调栈
3238: [Ahoi2013]差异 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 1561 Solved: 734[Submit][Status] ...
- BZOJ_3879_SvT_后缀数组+单调栈
BZOJ_3879_SvT_后缀数组+单调栈 Description (我并不想告诉你题目名字是什么鬼) 有一个长度为n的仅包含小写字母的字符串S,下标范围为[1,n]. 现在有若干组询问,对于每一个 ...
- BZOJ_3238_[Ahoi2013]差异_后缀数组+单调栈
BZOJ_3238_[Ahoi2013]差异_后缀数组+单调栈 Description Input 一行,一个字符串S Output 一行,一个整数,表示所求值 Sample Input cacao ...
随机推荐
- String转Map的工具类
借鉴代码 public class StringToMapUtil { public static Map<String, String> getValue(String param) { ...
- Linux系统救援模式应用:单用户模式找回密码
利用Linux系统救援模式找回密码 方法一: 开机时手要快按任意键,因为默认时间5s grub菜单,只有一个内核,没什么好上下选的,按e键.升级了系统或安装了Xen虚拟化后,就会有多个显示. 接下来显 ...
- xss跨站脚本攻击与防御读书笔记(原创)
XSS在客户端执行 可以任意执行js代码 0x01 xss 的利用方式 1. 钓鱼 案例:http://www.wooyun.org/bugs/wooyun-2014-076685 我是 ...
- 身份证号码正则匹配-javascript
function a(a, b) { return a.test(b) } function b(a) { return a = jQuery.trim(a), 0 == a.length } fun ...
- HDU1323_Perfection【水题】
Perfection Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total ...
- GitHub上编程语言流行度分析
GitHub已然是全球最流行的开源项目托管平台,项目数量眼下已经达到了千万级别.Adereth在Counting Stars on GitHub一文提供了一个很有意思的思路,那就是籍GitHub用户通 ...
- jsp获取web.xml 里的配置项
ServletContext servletContext = request.getSession().getServletContext(); String titl ...
- vs2013数据库连接对应的dll
mysql for visual studio 1.1.1mysql connector net 6.3.9mysql connector/odbc 5.3
- jquery在网页实时显示时间;
1.定义一个显示时间的位置 <div id="shijian"> </div> 2.jquery代码 function showTime() { var c ...
- libEasyPlayer RTSP windows播放器SDK API接口设计说明
概述 libEasyPlayer实现对RTSP直播流进行实时采集和解码显示,稳定,高效,低延时:解码可采用intel硬件解码和软件解码两种方式,能实时进行录像和快照抓图,OSD叠加等功能. API接口 ...