【爬虫】基于PUPPETEER页面爬虫
一、简介
本文简单介绍一下如何用puppeteer抓取页面数据。
二、下载
npm install puppeteer --save-dev
npm install typescrip --save-dev
三、实例
(一)实例一(看一段代码)
import { launch } from 'puppeteer';
async function maoyan_board_run() {
let browser = await launch({
ignoreHTTPSErrors: true,
headless: true,
executablePath: 'D:\\wangxiao\\chrome-win\\chrome-win\\chrome.exe',
args: ['--start-maximized']
});
const page = await browser.newPage();
await page.setViewport({width:1980,height:1080});
await page.goto('https://maoyan.com/board', { waitUntil: 'load' });
console.log(await page.title());
await browser.close();
}
maoyan_board_run();

运行后,答应出当前页面的title,分析一下这段代码做什么
- launch() 模拟启动一个浏览器,注意里面的参数,headless:true 无头模式,不打开浏览器,--start-maximized:浏览器最大化,executablePath:chromiun指定的路径
- browser.newPage() 打开一个新的页面
- page.setViewport() 指定窗口的高宽
- page.goto() 打开某个网站,waitUtil:load 加载完成
(二)分析页面selector
我们先分析一下这个页面,首先我们发现热门排行榜,电影名,主演,上映时间都是在一列一列的,那我们是不是只要获取一个,其他的都一样都获取到了
我们先分析一个名次
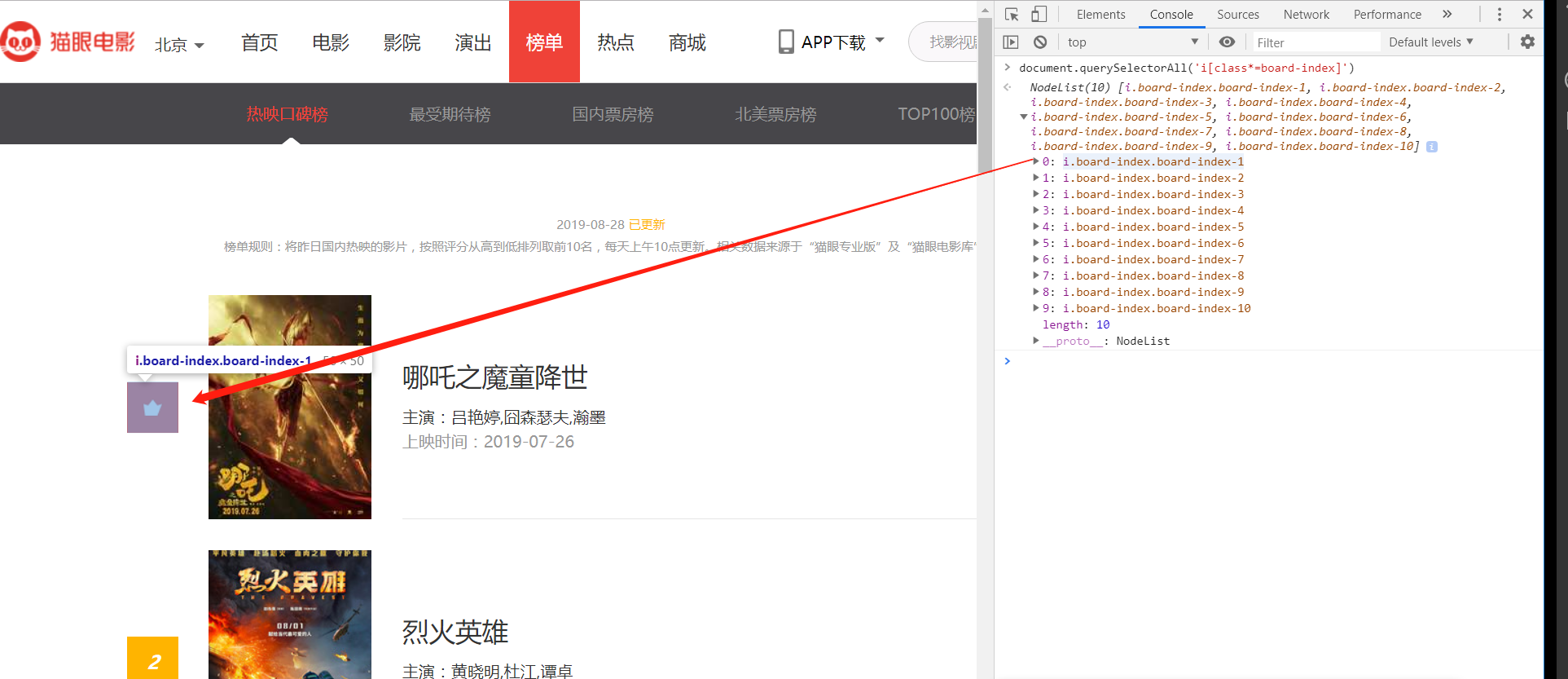
const movie_bank = 'i[class*=board-index]';
根据页面元素分析,要得到标签内的值($$eval用法不用说了,前面已经讲过了)
、

const banks = await page.$$eval(movie_bank, list =>
list.map(n => n.innerHTML)
);
其他内容获取方法依葫芦画瓢,完整代码如下
// 热门口碑榜-名次
const movie_bank = 'i[class*=board-index]';
// 热门口碑榜-名字
const movie_name = '.movie-item-info .name a';
// 热门口碑榜-主演
const movie_star = '.movie-item-info .star';
// 热门口碑榜-上映时间
const movie_releasetime = '.movie-item-info .releasetime';
// 热门口碑榜-图片
const board_lists_images = '.board-wrapper dd .image-link .board-img';
async function maoyan_board_run() {
let browser = await launch({
ignoreHTTPSErrors: true,
headless: true,
executablePath: 'D:\\wangxiao\\chrome-win\\chrome-win\\chrome.exe',
args: ['--start-maximized']
});
const page = await browser.newPage();
await page.setViewport({width:1980,height:1080});
await page.goto('https://maoyan.com/board', { waitUntil: 'load' });
// await autoScroll(page);
const length = await page.evaluate( (movie_bank) => {
return document.querySelectorAll(movie_bank).length;
},movie_bank);
const banks = await page.$$eval(movie_bank, list =>
list.map(n => n.innerHTML)
);
const names = await page.$$eval(movie_name, list =>
list.map(n => n.getAttribute('title'))
);
const stars = await page.$$eval(movie_star, list =>
list.map(n => n.innerHTML.replace(/\n/g,"").replace(/\s/g,""))
);
const releasetimes = await page.$$eval(movie_releasetime, list =>
list.map(n => n.innerHTML)
);
let data = [];
for (let i =0;i<length;i++) {
data.push({
bank:banks[i],
name:names[i],
star:stars[i],
releasetime:releasetimes[i]
})
}
await page.waitFor(10000);
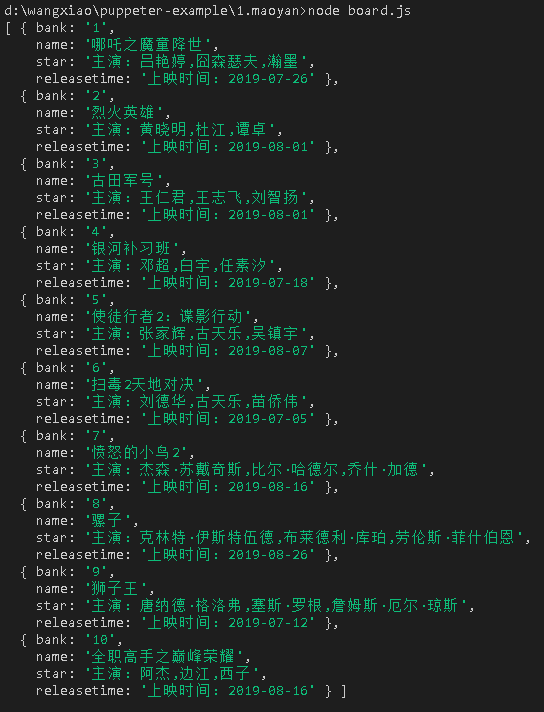
console.log(data);
await browser.close();
}
maoyan_board_run();
github:https://github.com/wangxiao9/puppeteer_spider
【爬虫】基于PUPPETEER页面爬虫的更多相关文章
- python爬虫之路——初识爬虫原理
爬虫主要做两件事 ①模拟计算机对服务器发起Request请求 ②接收服务器端的Response内容并解析,提取所需的信息 互联网页面错综复杂,一次请求不能获取全部信息.就需要设计爬虫的流程. 本书主要 ...
- 基于puppeteer模拟登录抓取页面
关于热图 在网站分析行业中,网站热图能够很好的反应用户在网站的操作行为,具体分析用户的喜好,对网站进行针对性的优化,一个热图的例子(来源于ptengine) 上图中能很清晰的看到用户关注点在那,我们不 ...
- 【java爬虫】---爬虫+基于接口的网络爬虫
爬虫+基于接口的网络爬虫 上一篇讲了[java爬虫]---爬虫+jsoup轻松爬博客,该方式有个很大的局限性,就是你通过jsoup爬虫只适合爬静态网页,所以只能爬当前页面的所有新闻.如果需要爬一个网站 ...
- web前端自动化测试/爬虫利器puppeteer介绍
web前端自动化测试/爬虫利器puppeteer介绍 Intro Chrome59(linux.macos). Chrome60(windows)之后,Chrome自带headless(无界面)模式很 ...
- 爬虫利器 Puppeteer
http://wintersmilesb101.online/2017/03/24/use-phantomjs-dynamic/ 一起学爬虫 Node.js 爬虫篇(三)使用 PhantomJS ...
- 爬虫抓取页面数据原理(php爬虫框架有很多 )
爬虫抓取页面数据原理(php爬虫框架有很多 ) 一.总结 1.php爬虫框架有很多,包括很多傻瓜式的软件 2.照以前写过java爬虫的例子来看,真的非常简单,就是一个获取网页数据的类或者方法(这里的话 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- Python 自用代码(scrapy多级页面(三级页面)爬虫)
2017-03-28 入职接到的第一个小任务,scrapy多级页面爬虫,从来没写过爬虫,也没学过scrapy,甚至连xpath都没用过,最后用了将近一周才搞定.肯定有很多low爆的地方,希望大家可以给 ...
- Python日记:基于Scrapy的爬虫实现
安装 pywin32 和python版本一致 地址 https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/安装过程中提示 ...
随机推荐
- Idea启动报错 Error:java: System Java Compiler was not found in classpath
报错信息:Error:java: System Java Compiler was not found in classpath 使用IDEA启动的时候出现了这个错误,查找了很久,才找到解决办法 1. ...
- 容器之间通讯方式\与pod关系
1.概述 k8s里面容器是存在于pod里面的,所以容器之间通讯,一般分为三种类型:1. pod内部容器之间 2. pod 与 pod 容器之间 3. pod 访问service服务 (1) pod内部 ...
- Git clone 克隆Github上的仓库,速度慢?
一. 终端输入: git config --global http.postBuffer 524288000 二. git替换https 三. windows 安装 https://motrix.ap ...
- Redis基础—了解Redis是如何做数据持久化的
之前的文章介绍了Redis的简单数据结构的相关使用和底层原理,这篇文章我们就来聊一下Redis应该如何保证高可用. 数据持久化 我们知道虽然单机的Redis虽然性能十分的出色, 单机能够扛住10w的Q ...
- 【SpringCloud】06.Eureka 总结
1.两个注解: @EnableEurekaServer--在启动类上添加 @EnableDiscoveryClient或@EnableEurekaClient--启动类加 因为Eureka支持多种注册 ...
- 【阿里云-大数据】阿里云DataWorks学习视频汇总
阿里云DataWorks学习视频汇总 注意:本文档中引用的视频均来自阿里云官方的帮助文档,本文档仅仅是汇总整理,方便学习. 阿里云DataWorks帮助文档链接:https://help.aliyun ...
- Mysql 日期-字符串转换。
mysql的字符串和日期类型的转换. 1.now()和curdate()的区别: now():datetime类型. mysql> select now(); +---------------- ...
- JSON小结【json-lib】
javabean:Address package com.baebae.model; public class Address { private String city; private Strin ...
- 用 Cloud Performance Test怎么录制测试脚本
Cloud Performance Test 云压力测试平台(以下简称:CPT)可以提供一站式全链路云压力测试服务,通过分布式压力负载机,快速搭建系统高并发运行场景,按需模拟千万级用户实时访问,并结合 ...
- 关于“Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured.”
Consider the following: If you want an embedded database (H2, HSQL or Derby), please put it on the c ...