Flink-v1.12官方网站翻译-P006-Intro to the DataStream API
DataStream API介绍
本次培训的重点是广泛地介绍DataStream API,使你能够开始编写流媒体应用程序。
哪些数据可以流化?
Flink的DataStream APIs for Java和Scala将让你流式处理任何它们可以序列化的东西。Flink自己的序列化器被用于
- 基本类型,即:字符串、长型、整数、布尔型、数组
- 复合类型。Tuples, POJOs, and Scala case classes.
而Flink又回到了Kryo的其他类型。也可以在Flink中使用其他序列化器。特别是Avro,得到了很好的支持。
Java元组和POJO
Flink的原生序列化器可以有效地操作元组和POJOs。
Tuples(元组)
对于Java,Flink定义了自己的Tuple0到Tuple25类型。
Tuple2<String, Integer> person = Tuple2.of("Fred", 35);
// zero based index!
String name = person.f0;
Integer age = person.f1;
POJOs
如果满足以下条件,Flink将数据类型识别为POJO类型(并允许 "按名称 "字段引用)。
- 类是公共的和独立的(没有非静态的内部类)。
- 该类有一个公共的无参数构造函数。
- 类(以及所有超级类)中的所有非静态、非瞬态字段要么是公共的(而且是非最终的),要么有公共的getter-和setter-方法,这些方法遵循Java beans中getter和setter的命名约定。
例如
public class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
. . .
};
}
Person person = new Person("Fred Flintstone", 35);
Flink的序列化器支持POJO类型的模式进化。
Scala元组和案例类
就像你期望的那样生效。
一个完整的例子
这个例子将一个关于人的记录流作为输入,并将其过滤为只包括成年人。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction; public class Example { public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2)); DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
}); adults.print(); env.execute();
} public static class Person {
public String name;
public Integer age;
public Person() {}; public Person(String name, Integer age) {
this.name = name;
this.age = age;
}; public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
流执行环境
每个Flink应用都需要一个执行环境,本例中的env。流式应用需要使用一个StreamExecutionEnvironment。
在你的应用程序中进行的DataStream API调用建立了一个作业图,这个作业图被附加到StreamExecutionEnvironment上。当调用env.execute()时,这个图会被打包并发送给JobManager,JobManager将作业并行化,并将它的片断分配给任务管理器执行。你的作业的每个并行片断将在一个任务槽中执行。
注意,如果你不调用execute(),你的应用程序将不会被运行。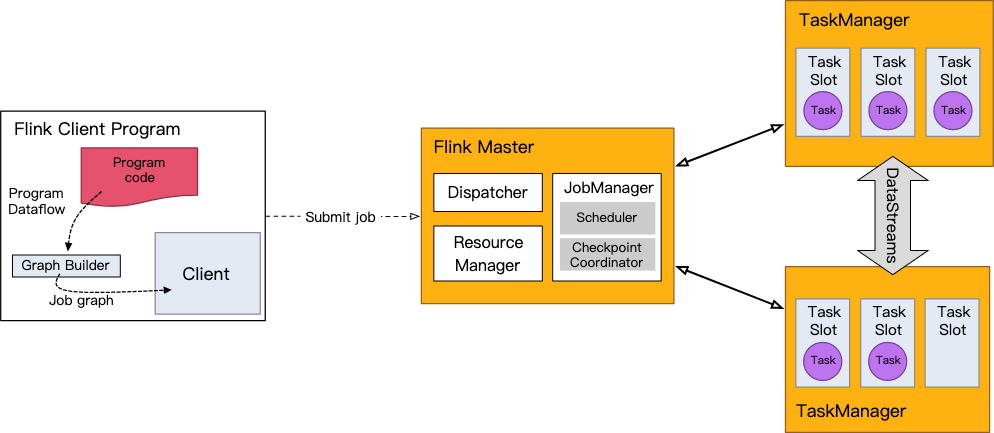
这种分布式运行时取决于你的应用程序是可序列化的。它还要求所有的依赖关系对集群中的每个节点都是可用的。
基础数据流来源
上面的例子使用env.fromElements(...)构造了一个DataStream<Person>。这是一种方便的方法,可以将一个简单的流组合起来,用于原型或测试。StreamExecutionEnvironment上还有一个fromCollection(Collection)方法。所以,你可以用这个方法来代替。
List<Person> people = new ArrayList<Person>();
people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));
DataStream<Person> flintstones = env.fromCollection(people);
另一种方便的方法是在原型开发时将一些数据导入流中,使用socket
DataStream<String> lines = env.socketTextStream("localhost", 9999)
或文件
DataStream<String> lines = env.readTextFile("file:///path");
在实际应用中,最常用的数据源是那些支持低延迟、高吞吐量并行读取并结合倒带和重放的数据源--这是高性能和容错的先决条件--如Apache Kafka、Kinesis和各种文件系统。REST API和数据库也经常被用于流的丰富。
基本数据流汇集
上面的例子使用 adults.print()将其结果打印到任务管理器的日志中(当在 IDE 中运行时,它将出现在你的 IDE 的控制台中)。这将在流的每个元素上调用toString()。
输出结果看起来像这样
1> Fred: age 35
2> Wilma: age 35其中1>和2>表示哪个子任务(即线程)产生的输出。
在生产中,常用的汇包括StreamingFileSink、各种数据库和一些pub-sub系统。
调试
在生产中,你的应用程序将在远程集群或一组容器中运行。而如果它失败了,它将会远程失败。JobManager和TaskManager日志对调试此类故障非常有帮助,但在IDE内部进行本地调试要容易得多,Flink支持这一点。你可以设置断点,检查本地变量,并逐步检查你的代码。你也可以步入Flink的代码,如果你好奇Flink是如何工作的,这可以是一个很好的方式来了解它的内部结构。
实践
在这一点上,你知道了足够的知识,可以开始编码和运行一个简单的DataStream应用程序。克隆flink-training repo,按照README中的说明操作后,进行第一个练习。过滤一个流(Ride Cleansing)。
进一步阅读
- Flink Serialization Tuning Vol. 1: Choosing your Serializer — if you can
- Anatomy of a Flink Program
- Data Sources
- Data Sinks
- DataStream Connectors
Flink-v1.12官方网站翻译-P006-Intro to the DataStream API的更多相关文章
- Flink-v1.12官方网站翻译-P002-Fraud Detection with the DataStream API
使用DataStream API进行欺诈检测 Apache Flink提供了一个DataStream API,用于构建强大的.有状态的流式应用.它提供了对状态和时间的精细控制,这使得高级事件驱动系统的 ...
- Flink-v1.12官方网站翻译-P015-Glossary
术语表 Flink Application Cluster Flink应用集群是一个专用的Flink集群,它只执行一个Flink应用的Flink作业.Flink集群的寿命与Flink应用的寿命绑定. ...
- Flink-v1.12官方网站翻译-P022-Working with State
有状态程序 在本节中,您将了解Flink为编写有状态程序提供的API.请看一下Stateful Stream Processing来了解有状态流处理背后的概念. 带键值的数据流 如果要使用键控状态,首 ...
- Flink-v1.12官方网站翻译-P019-Generating Watermarks
生成水印 在本节中,您将了解 Flink 提供的 API,用于处理事件时间时间戳和水印.关于事件时间.处理时间和摄取时间的介绍,请参考事件时间的介绍. 水印策略介绍 为了使用事件时间,Flink需要知 ...
- Flink-v1.12官方网站翻译-P017-Execution Mode (Batch/Streaming)
执行模式(批处理/流处理) DataStream API 支持不同的运行时执行模式,您可以根据用例的要求和作业的特点从中选择.DataStream API 有一种 "经典 "的执行 ...
- Flink-v1.12官方网站翻译-P016-Flink DataStream API Programming Guide
Flink DataStream API编程指南 Flink中的DataStream程序是对数据流实现转换的常规程序(如过滤.更新状态.定义窗口.聚合).数据流最初是由各种来源(如消息队列.套接字流. ...
- Flink-v1.12官方网站翻译-P013-Timely Stream Processing
及时的流处理 介绍 及时流处理是有状态流处理的一种扩展,其中时间在计算中起着一定的作用.其中,当你做时间序列分析时,当做基于某些时间段(通常称为窗口)的聚合时,或者当你做事件处理时,事件发生的时间很重 ...
- Flink-v1.12官方网站翻译-P011-Concepts-Overview
概念-概览 实践培训解释了作为Flink的API基础的有状态和及时流处理的基本概念,并提供了这些机制如何在应用中使用的例子.有状态的流处理是在数据管道和ETL的背景下介绍的,并在容错部分进一步发展.在 ...
- Flink-v1.12官方网站翻译-P007-Data Pipelines & ETL
数据管道和ETL 对于Apache Flink来说,一个非常常见的用例是实现ETL(提取.转换.加载)管道,从一个或多个源中获取数据,进行一些转换和/或丰富,然后将结果存储在某个地方.在这一节中,我们 ...
随机推荐
- LeetCode498 对角线遍历
给定一个含有 M x N 个元素的矩阵(M 行,N 列),请以对角线遍历的顺序返回这个矩阵中的所有元素,对角线遍历如下图所示. 示例: 输入: [ [ 1, 2, 3 ], [ 4, 5, 6 ], ...
- 【C++】《C++ Primer 》第十七章
第十七章 标准库特殊设施 一.tuple类型 tuple是类似pair的模板,每个pair的成员类型都不相同,但每个pair都恰好有两个成员. 不同的tuple类型的成员类型也不相同,一个tuple可 ...
- 【LeetCode】365.水壶问题
题目描述 解题思路 思路一:裴蜀定理-数学法 由题意,每次操作只会让桶里的水总量增加x或y,或者减少x或y,即会给水的总量带来x或y的变化量,转为数字描述即为:找到一对整数a,b使得下式成立: ax+ ...
- GCC 概述:C 语言编译过程详解
Tags: C Description: 关于 GCC 的个人笔记 GCC 概述 对于 GCC 6.1 以及之后的版本,默认使用的 C++ 标准是 C++ 14:使用 -std=c++11 来指定使用 ...
- 基于JavaFX实现的音乐播放器
前言 这个是本科四年的毕业设计,我个人自命题的一个音乐播放器的设计与实现,其实也存在一些功能还没完全开发完成,但粗略的答辩也就过去了,还让我拿了个优秀,好开心.界面UI是参考网易云UWP版本的,即使这 ...
- /usr/local/mysql/bin/mysqlbinlog -vv /var/lib/bin/mysql-bin.000008 --base64-output=DECODE-ROWS --start-pos=307
/usr/local/mysql/bin/mysqlbinlog -vv /var/lib/bin/mysql-bin.000008 --base64-output=DECODE-ROWS --st ...
- service代理模式及负载均衡
[root@k8s-master ~]# vim service.yaml apiVersion: v1 kind: Service metadata: name: my-service spec: ...
- Jquery实现对Array数组实现类似Linq的Lambda表达式的Where方法筛选
平时使用Linq,习惯了Lambda表达式,用着非常顺手,奈何在Jquery里面不能这样用,只能循环一个个判断.趁空闲时间找了找,自己写了这样的扩展方法.目前写出了三种方案,没有比较性能,觉得都可以用 ...
- MYSQL(将数据加载到表中)
1. 创建和选择数据库 mysql> CREATE DATABASE menagerie; mysql> USE menagerie Database changed 2. 创建表 mys ...
- 生僻标签 fieldset 与 legend 的妙用
谈到 <fieldset> 与 <legend>,大部分人肯定会比较陌生,在 HTML 标签中,属于比较少用的那一批. 我最早知道这两个标签,是在早年学习 reset.css ...