【python爬虫】一个简单的爬取百家号文章的小爬虫
需求
用“老龄智能”在百度百家号中搜索文章,爬取文章内容和相关信息。
观察网页
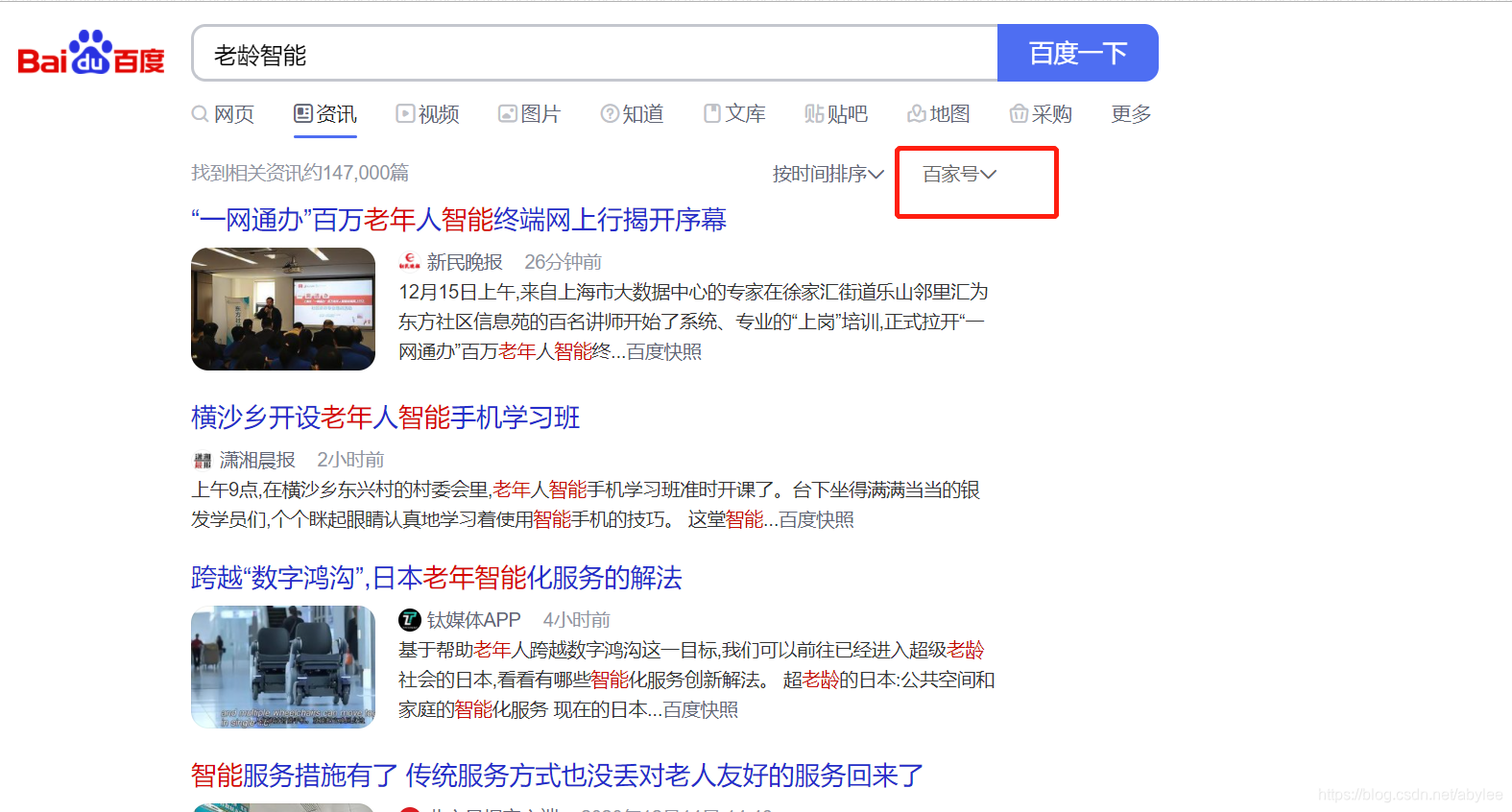
红色框框的地方可以选择资讯来源,我这里选择的是百家号,因为百家号聚合了来自多个平台的新闻报道。首先看了一下robots.txt,基本上对爬虫没有什么限制。然后就去定位网页元素,我的思路是先把上图搜索页的每篇文章的链接爬取下来,然后放在list里循环访问获取内容,这里再提一下为什么选百家号,因为你获取不同文章的链接之后,百家号文章页面的网页结构都是一样的。
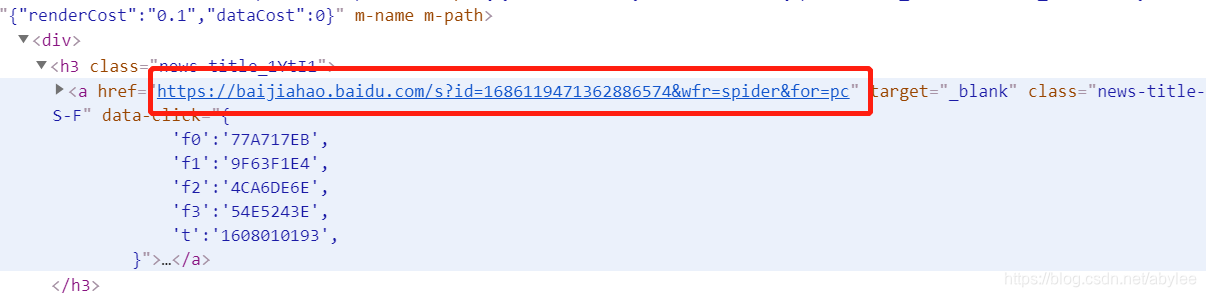
通过Chrome浏览器F12可以轻松定位到文章链接。但是还要考虑翻页的问题,一般没啥反爬的网站,都是通过url就可以实现翻页。
https://www.baidu.com/s?tn=news&rtt=4&bsst=1&cl=2&wd=%E8%80%81%E9%BE%84%E6%99%BA%E8%83%BD&medium=2&x_bfe_rqs=20001&x_bfe_tjscore=0.000000&tngroupname=organic_news&newVideo=12&rsv_dl=news_b_pn&pn=20
https://www.baidu.com/s?tn=news&rtt=4&bsst=1&cl=2&wd=%E8%80%81%E9%BE%84%E6%99%BA%E8%83%BD&medium=2&x_bfe_rqs=03E80&x_bfe_tjscore=0.000000&tngroupname=organic_news&newVideo=12&rsv_dl=news_b_pn&pn=10
以上分别是第三页和第二页的url,很明显,最后的“pn=”后面的数字决定了页码,第一页显然是pn=0。好了现在就可以开始写爬虫了。
写代码
先写获取文章链接的部分。爬虫首先需要确认好headers的内容,我这里就用了user-agent和host,我试了一下,百度的话host还是需要的。
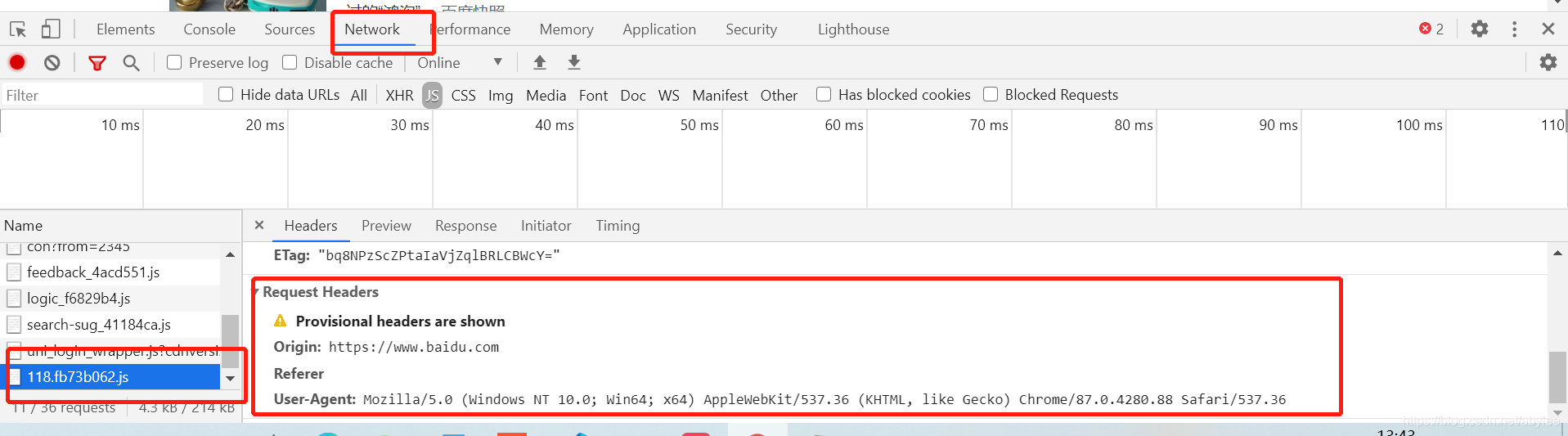
还是Chrome浏览器F12一下,在network里面随便点个东西,找到requests headers就可以找到我们需要的信息,将里面的user-agent和host复制进自己的代码中。
import requests
from bs4 import BeautifulSoup
import sys
import time
from openpyxl import workbook
from openpyxl import load_workbook
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
'Host': 'www.baidu.com'
}
headers1 = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
'Host': 'baijiahao.baidu.com'
}
导入库之后,这里我定义了两个header,第一个是百度搜索页使用,第二个是爬百家号文章时要用的。
#获取百家号文章链接
def get_connect(link):
try:
r = requests.get(link, headers=headers, timeout=10)
if 200 != r.status_code:
return None
url_list = []
soup = BeautifulSoup(r.text, "lxml")
div_list = soup.find_all('div', class_='result-op c-container xpath-log new-pmd')
for div in div_list:
mu = div['mu'].strip()
url_list.append(mu)
print(mu)
return get_content(url_list)
except Exception as e:
print('e.message:\t', e)
finally:
print(u'go ahead!\n\n')
这里是定义了获取百家号链接,也就是爬取百度搜索页的函数,直接用bs4解析网页就行了,没什么难的,用了try exception做一下报错机制。
#获取百家号内容
def get_content(url_list):
try:
for url in url_list:
clist=[] #空列表存储文章内容
r1 = requests.get(url,headers=headers1,timeout=10)
soup1 = BeautifulSoup(r1.text, "lxml")
s1 = soup1.select('.article-title > h2:nth-child(1)')
s2 = soup1.select('.date')
s3 = soup1.select('.author-name > a:nth-child(1)')
s4 = soup1.find_all('span',class_='bjh-p')
title = s1[0].get_text().strip()
date = s2[0].get_text().strip()
source = s3[0].get_text().strip()
for t4 in s4:
para = t4.get_text().strip() #获取文本后剔除两侧空格
content = para.replace('\n','') #剔除段落前后的换行符
clist.append(content)
content = ''.join('%s' %c for c in clist)
ws.append([title,date,source,content])
print([title,date])
wb.save('XXX.xlsx')
except Exception as e:
print("Error: ",e)
finally:
wb.save('XXX.xlsx') #保存已爬取的数据到excel
print(u'OK!\n\n')
爬虫定位网页元素一般有bs4普通的find方法,css选择器,xpath(用soup.select方法)等路径。firefox浏览器在F12中右键你想要获取的元素可以选择是要CSS选择器还是xpath。
#主函数
if __name__ == '__main__':
raw_url='https://www.baidu.com/s?tn=news&rtt=4&bsst=1&cl=2&wd=老龄智能&medium=2&x_bfe_rqs=20001&x_bfe_tjscore=0.000000&tngroupname=organic_news&newVideo=12&rsv_dl=news_b_pn&pn='
wb = workbook.Workbook() # 创建Excel对象
ws = wb.active # 获取当前正在操作的表对象
# 往表中写入标题行,以列表形式写入!
ws.append(['title','dt','source','content'])
#通过循环完成url翻页
for i in range(1000):
link=raw_url+str(i*10)
get_connect(link)
print('page',i+1)
#time.sleep(5)
wb.save('XXX.xlsx')
print('finished')
wb.close()
最后把主函数写好,用一个for循环实现翻页操作,range范围这里我拍脑袋给的1000,根据实际情况来吧还是得。
实际效果

完事儿!
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理
想要获取更多Python学习资料可以加
QQ:2955637827私聊
或加Q群630390733
大家一起来学习讨论吧!
【python爬虫】一个简单的爬取百家号文章的小爬虫的更多相关文章
- 【nodejs 爬虫】使用 puppeteer 爬取链家房价信息
使用 puppeteer 爬取链家房价信息 目录 使用 puppeteer 爬取链家房价信息 页面结构 爬虫库 pupeteer 库 实现 打开待爬页面 遍历区级页面 方法一 方法二 遍历街道页面 遍 ...
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- 一个简单的爬取b站up下所有视频的所有评论信息的爬虫
心血来潮搞了一个简单的爬虫,主要是想知道某个人的b站账号,但是你知道,b站在搜索一个用户时,如果这个用户没有投过稿,是搜不到的,,,这时就只能想方法搞到对方的mid,,就是 space.bilibil ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
- Python爬虫入门教程 42-100 爬取儿歌多多APP数据-手机APP爬虫部分
1. 儿歌多多APP简单分析 今天是手机APP数据爬取的第一篇案例博客,我找到了一个儿歌多多APP,没有加固,没有加壳,没有加密参数,对新手来说,比较友好,咱就拿它练练手,熟悉一下Fiddler和夜神 ...
- Python 基础语法+简单地爬取百度贴吧内容
Python笔记 1.Python3和Pycharm2018的安装 2.Python3基础语法 2.1.1.数据类型 2.1.1.1.数据类型:数字(整数和浮点数) 整数:int类型 浮点数:floa ...
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 用Python实现的一个简单的爬取省市乡镇的行政区划信息的脚本
# coding=utf-8 # Creeper import os import bs4 import time import MySQLdb import urllib2 import datet ...
随机推荐
- 利用css3和js实现旋转木马图片小demo
先看效果图: 上源码 html代码 <!DOCTYPE html> <html lang="en"> <head> <meta chars ...
- 【数学】康托展开 && 康托逆展开
(7.15)康托展开,就是把全排列转化为唯一对应自然数的算法.它可以建立1 - n的全排列与[1, n!]之间的自然数的双向映射. 1.康托展开: 尽管我并不清楚康托展开的原理何在,这个算法的过程还是 ...
- MySQL查询练习2
MySQL查询练习2 导读: 本次MySQL的查询语句是本人考试题目: 所有题目都已通过: 该查询练习并没有sql文件进行检查: 如果有书写以及其他错误欢迎指出. 题目正文: 1.找出借书超过5本的借 ...
- NameServer 与zk
1.nameServer 之间互不通信,故不存在强一致性,即不同的producer看到的视图可能时不一样的,(如何保证最终一致的?) 2.nameServer维护的boker信息 发生变化时,不会像z ...
- SpringCloud 源码系列(1)—— 注册中心 Eureka(上)
Eureka 是 Netflix 公司开源的一个服务注册与发现的组件,和其他 Netflix 公司的服务组件(例如负载均衡.熔断器.网关等)一起,被 Spring Cloud 整合为 Spring C ...
- nacos单机,集群安装部署
nacos单机启动 准备 下载nacos安装包 下载地址 准备centos环境 (本次测试使用docker) PS C:\Users\Administrator> docker run -tid ...
- 基于struts2的记住账号密码的登录设计
一个简单的基于struts2的登录功能,实现的额外功能有记住账号密码,登录错误提示.这里写上我在设计时的思路流程,希望大家能给点建设性的意见,帮助我改善设计. 登录功能的制作,首先将jsp界面搭建出来 ...
- 洛谷P3906 Hoof Paper, Scissor (记忆化搜索)
这道题问的是石头剪刀布的的出题问题 首先不难看出这是个dp题 其次这道题的状态也很好确定,之前输赢与之后无关,确定三个状态:当前位置,当前手势,当前剩余次数,所以对于剪刀,要么出石头+1分用一次机会, ...
- OpenCV阈值处理函数threshold处理32位彩色图像的案例
☞ ░ 前往老猿Python博文目录 ░ 一.概述 openCV图像的阈值处理又称为二值化,之所以称为二值化,是它可以将一幅图转换为感兴趣的部分(前景)和不感兴趣的部分(背景).转换时,通常将某个值( ...
- 老猿学5G扫盲贴:N6接口用户平面协议栈对应的网络分层模型
在网络通信模型中,都对应有分层的网络结构,如开放式系统互联(OSI)的七层模型(物理层.数据链路层.网络层.传输层.会话层.表示层和应用层)以及TCP/IP四层(网络接口层.网络层.传输层和应用层)模 ...