图解JAVA容器核心类库
JAVA容器详解
类继承结构图


HashMap
1. 对象的HashCode是用来在散列存储结构中确定对象的存储地址的。
2. 如果两个对象的HashCode相同,即在数组中的地址相同。而数组的元素是链表。这两个对象会放在同一链表上。
3. 如何确定是同一个对象? 通过equals方法。
4. HashMap默认的加载因子是0.75,默认最大容量是16。扩容大小:扩容原来的一倍。
因此可以得出HashMap的默认实际容量是:0.75*16=12,到了12就会扩容。
5. JAVA 7中的HashMap是数组和链表的结合体。JAVA 8中是数组 + 红黑树实现。
ConcurrentHashMap
1. JDK1.7版本:ReentrantLock+Segment+HashEntry
JDK1.8版本中synchronized+CAS+HashEntry+红黑树,已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发。
2. 查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
3. 定位一个元素的过程需要进行两次Hash操作。第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
TreeSet与TreeMap :可以保证按大小排序。
LinkedHashSet与LinkedHashMap:加了一个双向链表,能保证添加的顺序。
ArrayList与LinkedList:即数组和链表的优缺点。查询前者更高效,添加删除后者更高效。
线程不安全的类
HashMap、HashSet、ArrayList、LinkedList、TreeSet、TreeMap
同步容器
ArrayList -> Vector、Stack
HashMap -> HashTable(key和value不能为空)
- HashMap不是线程安全的,多线程环境容易导致CPU 100%
- HashTable使用synchronized来保证线程安全,效率低下。
Collections.synchronizedXXX(List,Set,Map):原理是直接使用synchronized修饰。一般并发够用,但是高并发情况下需要使用并发容器。
Collections.synchronizedList(l1);
Collections.synchronizedMap(new HashMap<String,String>());
Collections.synchronizedSet(new HashSet<String>());
Collections.synchronizedSortedMap(new TreeMap<String,String>());
Collections.synchronizedSortedSet(new TreeSet<String>());
并发容器 J.U.C(比同步容器更适合高并发)
ArrayList -> CopyOnWriteArrayList
写写才会阻塞,写不阻塞读。 适合大小比较小且读多写少的场景
HashSet -> CopyOnWriteArraySet
适合大小比较小且读多写少的场景
TreeSet(大小顺序) -> ConcurrentSkipListSet(同步+大小顺序)
适合大小比较小且读多写少的场景
HashMap -> ConcurrentHashMap(同步)
锁分段技术-数据分成一段一段存储(一段对应一个hashEntry数组,每个数组是一个链表结构的元素) ,为每一段数据分配一把锁,多线程访问不同数据段时,就不会产生竞争了。
TreeMap(大小顺序) -> ConcurrentSkipListMap(同步+大小顺序)
ConcurrentLinkedQueue 高效的并发队列,是高并发中性能最好的队列,先进先出,使用链表实现。入队了出队都采用CAS算法。(线程安全的LinkedList)
CopyOnWriteArrayList 详解
1. 读不加锁
2. 读写分离:写时复制的容器。
通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加, 而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
3. 最终一致:不能保证数据的实时一致性
对CopyOnWriteArrayList来说,线程1读取集合里面的数据,未必是最新的数据。因为线程2、线程3、线程4四个线程都修改了CopyOnWriteArrayList里面的数据,但是线程1拿到的还是最老的那个Object[] array,新添加进去的数据并没有,所以线程1读取的内容未必准确。不过这些数据虽然对于线程1是不一致的,
但是对于之后的线程一定是一致的,它们拿到的Object[] array一定是三个线程都操作完毕之后的Object array[],这就是最终一致。
4. 缺点:
不保证实时一致:在完成写入、删除和修改前,读取到的仍然是旧数据。
非常耗内存,写入和修改操作复制一个数组。数据量大时可能造成频繁的Yong GC和Full GC
Vector、Collections.synchronizedList 和 CopyOnWriteArrayList
Vector对所有操作进行了synchronized关键字修饰,性能应该比较差CopyOnWriteArrayList 读不加锁,读性能较好;但是在写操作时需要进行copy操作,写性能是三者最差的。适合读操作远远多于写操作Collections.synchronizedList性能较均衡,但是迭代操作并未加锁,所以需要时需要额外注意- Vector在迭代时进行修改也会有ConcurrentModificationException异常,可以通过加锁或者使用CopyOnWriteArrayList解决。
跳表:ConcurrentSkipListSet和ConcurrentSkipListMap
特点:与HashSet/HashMap相比,所有元素都是有序的。
- 跳跃表结构是拿空间换时间的一种结构,尽管空间占用不是很大。
- 查询、删除,平均时间复杂度都是O(logn),而插入的平均时间复杂度也是O(logn)
- 跳跃表不同于树结构,如红黑树等,它不需要花费过多的精力进行平衡算法,这也是跳跃表的性能优越的一个方面。

1. 多层结构,每一层都是一个有序的链表,
2. 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
3. 最底层(Level 1)的链表包含所有元素
4. 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
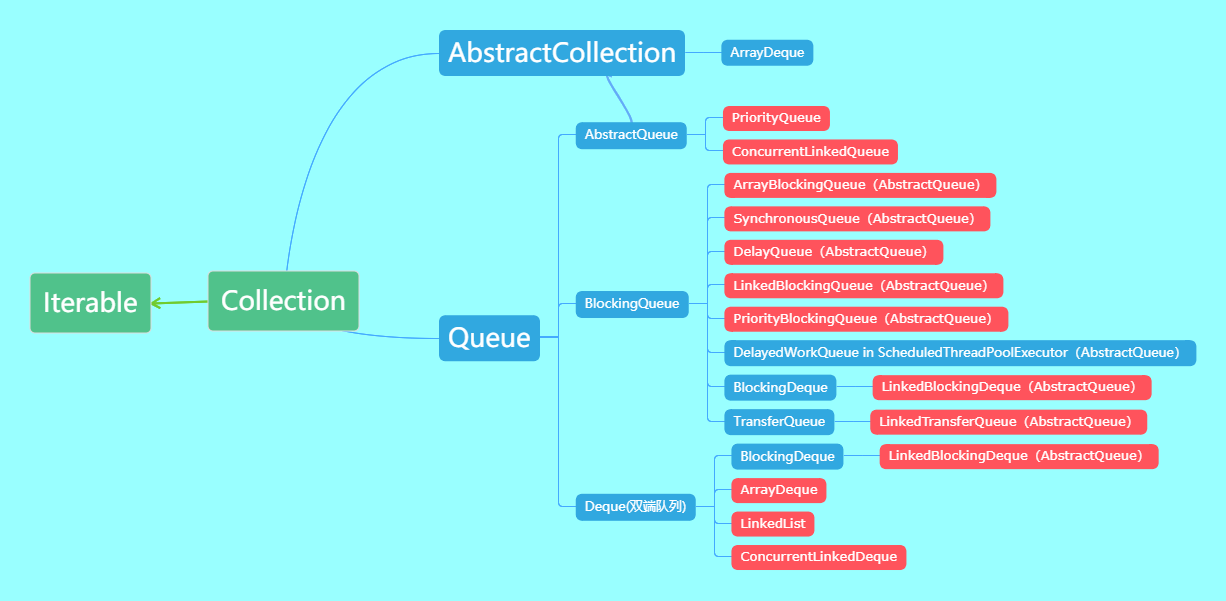
阻塞队列

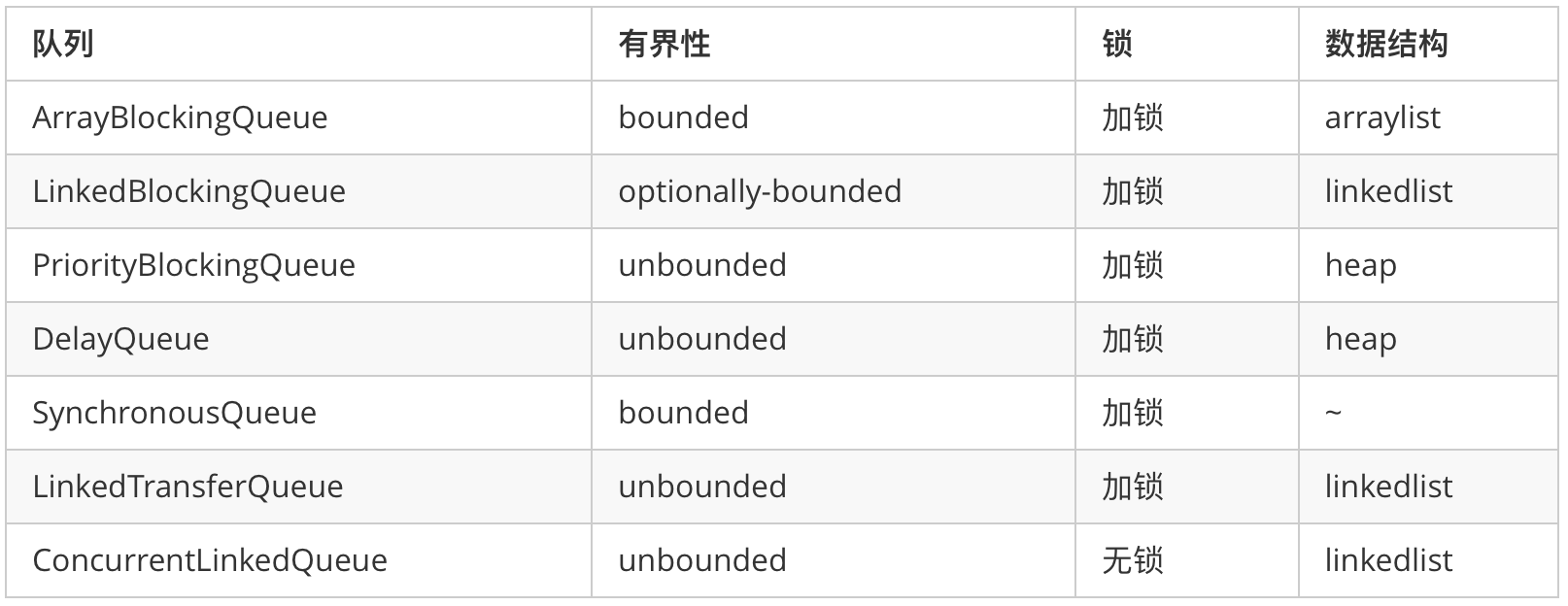
1.ArrayBlockingQueue:数组有界阻塞队列
2.LinkedBlockingQueue:链表有界阻塞队列,默认长度和最大长度都为Integer.MAX_VALUE
3.PriorityBlockingQueue:支持优先级排序的无界阻塞队列,默认情况下自然顺序,支持重现compareTo()方法
4.DelayQueue:使用PriorityQueue实现的支持延时获取元素的无界阻塞队列,元素必须实现Delayed接口,可以指定延迟多久后才能取出元素,期满才能取出。
5.SychronousQueue:一个不存储元素的阻塞队列。每一个Put操作必须等到一个take操作,否则不能继续添加。
6.LinkedTransferQueue:链表无界阻塞队列
7.LinkedBlokingDeque:链表双向阻塞队列-可以从两端插入和移除元素。
队列的底层一般分成三种:数组、链表和堆。其中,堆一般情况下是为了实现带有优先级特性的队列,暂且不考虑。
我们就从数组和链表两种数据结构来看,基于数组线程安全的队列,比较典型的是ArrayBlockingQueue,它主要通过加锁的方式来保证线程安全;基于链表的线程安全队列分成LinkedBlockingQueue和ConcurrentLinkedQueue两大类,前者也通过锁的方式来实现线程安全,而后者以及上面表格中的LinkedTransferQueue都是通过原子变量compare and swap(以下简称“CAS”)这种不加锁的方式来实现的。
通过不加锁的方式实现的队列都是无界的(无法保证队列的长度在确定的范围内);而加锁的方式,可以实现有界队列。在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列;同时,为了减少Java的垃圾回收对系统性能的影响,会尽量选择array/heap格式的数据结构。这样筛选下来,符合条件的队列就只有ArrayBlockingQueue。然而,ArrayBlockingQueue在实际使用过程中,会因为加锁和伪共享等出现严重的性能问题。
队列总结:如果真的是应对高并发场景,建议使用无锁内存队列Disruptor(单机性能极致)。Log4j 2、 Storm等都有应用。
可以参考:https://tech.meituan.com/2016/11/18/disruptor.html
图解JAVA容器核心类库的更多相关文章
- Java——容器类库框架浅析
前言 通常,我们总是在程序运行过程中才获得一些条件去创建对象,这些动态创建的对象就需要使用一些方式去保存.我们可以使用数组去存储,但是需要注意数组的尺寸一旦定义便不可修改,而我们并不知道程序在运行过程 ...
- 3)Java容器
3)Java容器 Java的集合框架核心主要有三种:List.Set和Map.这里的 Collection.List.Set和Map都是接口(Interface). List lst = new ...
- 【Java心得总结七】Java容器下——Map
我将容器类库自己平时编程及看书的感受总结成了三篇博文,前两篇分别是:[Java心得总结五]Java容器上——容器初探和[Java心得总结六]Java容器中——Collection,第一篇从宏观整体的角 ...
- 【Java心得总结六】Java容器中——Collection
在[Java心得总结五]Java容器上——容器初探这篇博文中,我对Java容器类库从一个整体的偏向于宏观的角度初步认识了Java容器类库.而在这篇博文中,我想着重对容器类库中的Collection容器 ...
- 【Java心得总结五】Java容器上——容器初探
在数学中我们有集合的概念,所谓的一个集合,就是将数个对象归类而分成为一个或数个形态各异的大小整体. 一般来讲,集合是具有某种特性的事物的整体,或是一些确认对象的汇集.构成集合的事物或对象称作元素或是成 ...
- Java 容器(list, set, map)
java容器类库的简化图: (虚线框表示接口, 实线框表示普通的类, 空心箭头表示特定的类实现了接口, 实心箭头表示某个类可以生成箭头所指的类对象) 继承Collection的主要有Set 和 Lis ...
- Java以基础类库
Java以基础类库JFC(Java Foundation Class)的形式为程序员提供编程接口API,类库中的类按照用途归属于不同的包中. (一)java.lang包 Java最常用的包都属于该包, ...
- 十二、EnterpriseFrameWork框架核心类库之与EntLib结合
从本章开始对框架的讲叙开始进入核心类库的讲解,前面都是对框架外在功能讲解,让人有个整体的概念,知道包含哪些功能与对系统开发有什么帮助.以后多章都是讲解核心类库的,讲解的方式基本按照代码的目录结构,这样 ...
- java容器---集合总结
思考为什么要引入容器这个概念? Java有多种方式保存对象(应该是对象的引用),例如使用数组时保存一组对象中的最有效的方式,如果你想保存一组基本类型的数据,也推荐使用这种方式,但大家知道数组是具有固定 ...
随机推荐
- Text多行文本框基本用法
1.Text(root,width,height,bg) 主窗口,宽度,高度,背景色 2.使用 .insert() 方法添加内容 Text 对象.insert(几行.几列,"内容" ...
- 线程_使用multiprocessing启动一个子进程及创建Process 的子类
from multiprocessing import Process import os # 子进程执行的函数 def run_proc(name): print("子进程运行中,名称:% ...
- PHP sqrt() 函数
实例 返回不同数的平方根: <?phpecho(sqrt(0) . "<br>");echo(sqrt(1) . "<br>"); ...
- Miller-Rabin素数测试算法
用来干嘛的 要判断一个数 \(n\) 是否为素数,最朴素直接的办法是以\(O(\sqrt n)\) 时间复杂度地从2到 \(\sqrt n\) 循环即可得到最准确的结果.但是如果在 \(n\) ...
- .NetCore 入门
.net core是什么? .net core是一个可以用来构建现代.可伸缩和高性能的跨平台软件应用程序的通用开发框架. 我们为什么要使用.net core,也就是说.net core有什么好处? 跨 ...
- 解决IIS发布时CS0016未能写入输出文件错误
今天遇到一个将asp.net项目部署到IIS后访问的时候报的一个错误: 在网上查询了相关资料后,解决方法如下: 找到C:\Windows\下的temp文件,右键属性>安全>编辑,给其中II ...
- Java助教工作总结
很荣幸在步入在研究生之际,有机会能协助代老师完成面向对象程序设计(java)课程的教学工作.这也是我人生中第一次接触助教工作,好多东西不太清楚,也没经验,有什么做的不好的,还望老师同学及时指出. 上周 ...
- PR基础
Windows->Workspace->Reset to saved layout 恢复工作区 Edit->Perferences->Auto Save 设置自动保存时间 资源 ...
- Elasticsearch第四篇:索引别名、添加或修改映射规则
项目中经常出现的问题,例如添加字段.修改字段,那原先的索引规则就要跟着改变,最好是一开始就给索引一个别名,修改字段时新增映射,然后将笔名指向新的映射,当然需要将之前的索引搬迁到新的映射当中. 1.获取 ...
- 2020-06-19:多线程消费kafka的时候,开发、测试环境都能每秒10w+,但是正式环境只能1w/s,正式环境不能重启,看怎么调试?
福哥答案2020-06-19: 答案来自群成员:基准测试. 观察 网络和磁盘的读写,实时与历史曲线,观察文件句柄/内存的使用情况.观察系统patch 基础库/运行时状态.