Scrapy 项目:QuotesBot
QuotesBot
This is a Scrapy project to scrape quotes from famous people from http://quotes.toscrape.com (github repo).
This project is only meant for educational purposes.
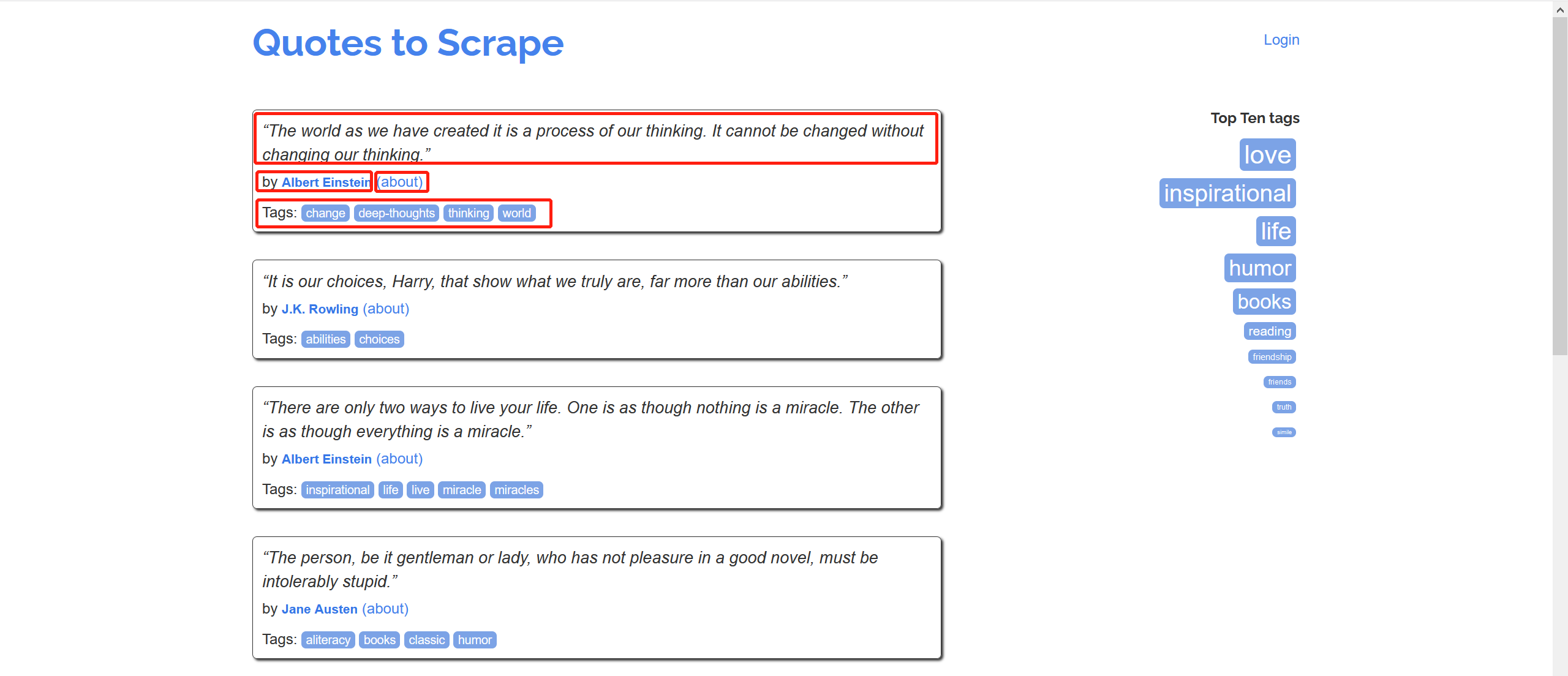
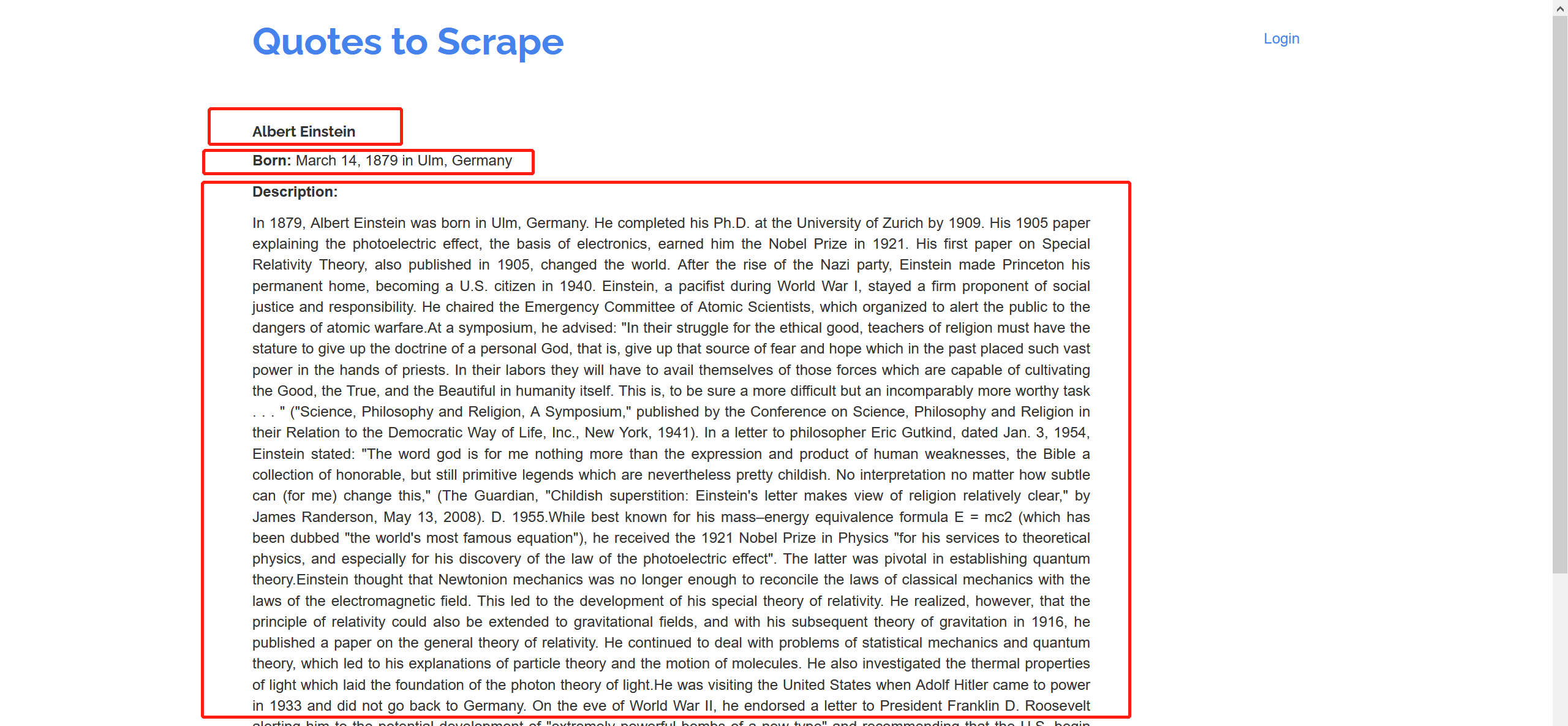
任务:
爬取该网站的名人名言、作者、作者信息(名字,生日、描述)以及名言标签,并保存
import scrapy
import re class AuthorSpider(scrapy.Spider):
name = "author"
start_urls = ["http://quotes.toscrape.com/"] def parse(self, response):
author_page_links = response.css('.author + a')
yield from response.follow_all(author_page_links, self.parse_author) next_page_links = response.css('li.next a')
yield from response.follow_all(next_page_links, self.parse) def parse_author(self, response):
def extract_with_css(query):
return response.css(query).get(default="").strip() yield {
"name": extract_with_css("h3.author-title::text"),
"birthdate": extract_with_css(".author-born-date::text"),
"bio": extract_with_css(".author-description::text"),
}
保存:
scrapy crawl spidername -o test.csv
项目练习:
Extracted data
This project extracts quotes, combined with the respective author names and tags. The extracted data looks like this sample:
{
'author': 'Douglas Adams',
'text': '“I may not have gone where I intended to go, but I think I ...”',
'tags': ['life', 'navigation']
}
Spiders
This project contains two spiders and you can list them using the list command:
$ scrapy list
toscrape-css
toscrape-xpath
Both spiders extract the same data from the same website, but toscrape-css employs CSS selectors, while toscrape-xpath employs XPath expressions.
You can learn more about the spiders by going through the Scrapy Tutorial.
Running the spiders
You can run a spider using the scrapy crawl command, such as:
scrapy crawl toscrape-css
If you want to save the scraped data to a file, you can pass the -o option:
scrapy crawl toscrape-css -o quotes.json
项目代码:
class QuotesbotSpider(scrapy.Spider):
name = "quotesbot"
start_urls = ["http://quotes.toscrape.com"] def parse(self, response, **kwargs):
for quote in response.css('div.quote'):
yield {
"author":quote.css(".author::text").get(),
"text":quote.css(".text::text").get(),
"tags":quote.css(".tags meta::attr(content)").get(),
} next_page_link = response.css("li.next a")
if next_page_link is not None:
yield from response.follow_all(next_page_link, callbac
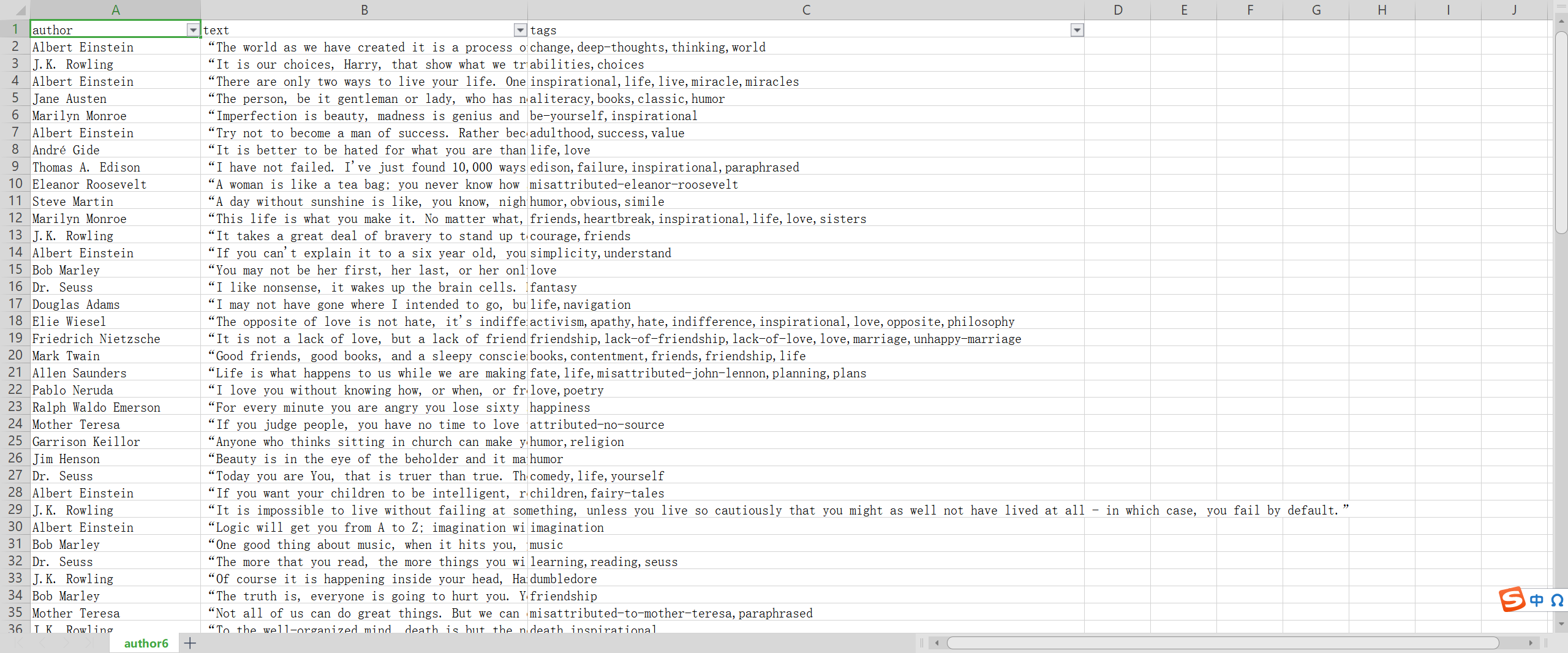
结果:
Scrapy 项目:QuotesBot的更多相关文章
- 亲测——pycharm下运行第一个scrapy项目 ©seven_clear
最近在学习scrapy,就想着用pycharm调试,但不知道怎么弄,从网上搜了很多方法,这里总结一个我试成功了的. 首先当然是安装scrapy,安装教程什么的网上一大堆,这里推荐一个详细的:http: ...
- scrapy(一)建立一个scrapy项目
本项目实现了获取stack overflow的问题,语言使用python,框架scrapy框架,选取mongoDB作为持久化数据库,redis做为数据缓存 项目源码可以参考我的github:https ...
- Python Scrapy项目创建(基础普及篇)
在使用Scrapy开发爬虫时,通常需要创建一个Scrapy项目.通过如下命令即可创建 Scrapy 项目: scrapy startproject ZhipinSpider 在上面命令中,scrapy ...
- pycharm创建scrapy项目教程及遇到的坑
最近学习scrapy爬虫框架,在使用pycharm安装scrapy类库及创建scrapy项目时花费了好长的时间,遇到各种坑,根据网上的各种教程,花费了一晚上的时间,终于成功,其中也踩了一些坑,现在整理 ...
- 【Python3爬虫】第一个Scrapy项目
Python版本:3.5 IDE:Pycharm 今天跟着网上的教程做了第一个Scrapy项目,遇到了很多问题,花了很多时间终于解决了== 一.Scrapy终端(scrapy shell) Sc ...
- eclipse创建scrapy项目
1. 您必须创建一个新的Scrapy项目. 进入您打算存储代码的目录中(比如否F:/demo),运行下列命令: scrapy startproject tutorial 2.在eclipse中创建一个 ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- Scrapy项目创建以及目录详情
Scrapy项目创建已经目录详情 一.新建项目(scrapy startproject) 在开始爬取之前,必须创建一个新的Scrapy项目.进入自定义的项目目录中,运行下列命令: PS C:\scra ...
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- 爬虫系列2:scrapy项目入门案例分析
本文从一个基础案例入手,较为详细的分析了scrapy项目的建设过程(在官方文档的基础上做了调整).主要内容如下: 0.准备工作 1.scrapy项目结构 2.编写spider 3.编写item.py ...
随机推荐
- linux 用户、用户组及相关命令(useradd 、passwd、userdel 、groupadd 、groupdel、usermod 、gpasswd 、 id、su)
linux是一个多用户系统,用于权限管理(权限最小化); 相关命令: 7 8 9 10 11 12 13 14 15 useradd passwd userdel groupadd groupdel ...
- Object类的常见方法总结
♧ Object类是比较特殊的类,它是所有类的父类.主要提供了11个方法(JDK 1.8为例): /** * native方法,用于返回当前运行时对象的Class对象,使用final关键字修饰,子类不 ...
- Flink 在又拍云日志批处理中的实践
日前,由又拍云举办的大数据与 AI 技术实践|Open Talk 杭州站沙龙在杭州西溪科创园顺利举办.本次活动邀请了有赞.个推.方得智能.又拍云等公司核心技术开发者,现场分享各自领域的大数据技术经验和 ...
- linux(3) 处理目录的常用命令
目录命令总览 ls(英文全拼:list files): 列出目录及文件名 cd(英文全拼:change directory):切换目录 pwd(英文全拼:print work directory):显 ...
- 手把手教你从Git上导入项目
Git上导入项目 进入Gitlab账户中的项目,点击Clone按钮,复制HTTPS路径.如果配置了SSH,则可以通过SSH导入项目. 在IDEA中,点击VCS-Checkout from Versio ...
- AcWing 241 楼兰图腾 (树状数组)
在完成了分配任务之后,西部314来到了楼兰古城的西部. 相传很久以前这片土地上(比楼兰古城还早)生活着两个部落,一个部落崇拜尖刀('V'),一个部落崇拜铁锹('∧'),他们分别用V和∧的形状来代表各自 ...
- 静态链表 Static Link List
Static Link List 静态链表 其中上图来自http://www.cnblogs.com/rookiefly/p/3447982.html 参考: http://www.cnblogs. ...
- C语言实现--静态链表的操作
1,我们研究数据结构的操作,第一要弄懂它的结构体表示(也就是结构体特点).第二要清楚它的初始化和撤销过程.对于静态链表首先分析它的特点:一是采用静态存储方式,二是没有指针.静态链表就是不用指针来表示链 ...
- Kubernets二进制安装(11)之部署Node节点服务的kubelet
集群规划 主机名 角色 IP地址 mfyxw30.mfyxw.com kubelet 192.168.80.30 mfyxw40.mfyxw.com kubelet 192.168.80.40 注意: ...
- ajax全局
$.ajaxSetup({ complete: function (xhr) { xhr.promise().done(function (json) { if (json.errorNo == &q ...