caffe(3) 视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN)局部相应归一化, im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
type:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
2、Pooling层
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
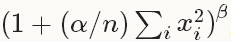 ,得到归一化后的输出
,得到归一化后的输出 layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
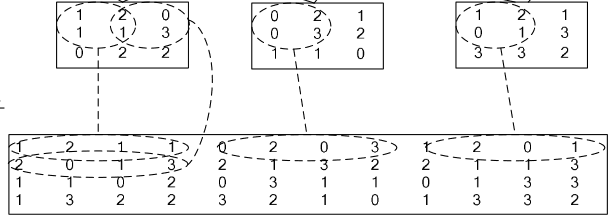
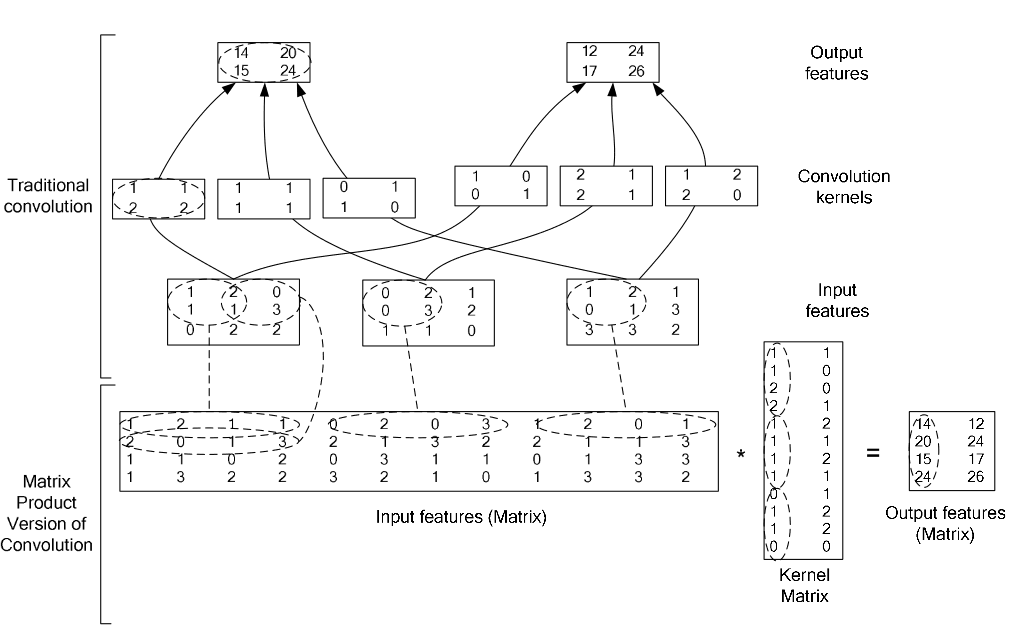
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
caffe(3) 视觉层及参数的更多相关文章
- 【转】Caffe初试(五)视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. ...
- 4、Caffe其它常用层及参数
借鉴自:http://www.cnblogs.com/denny402/p/5072746.html 本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accu ...
- caffe(2) 数据层及参数
要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个屋(layer)构成,每一屋又由许多参数组成.所有的参数都定义在caffe.proto这个文件 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- [caffe]网络各层参数设置
数据层 数据层是模型最底层,提供提供数据输入和数据从Blobs转换成别的格式进行保存输出,通常数据预处理(减去均值,放大缩小,裁剪和镜像等)也在这一层设置参数实现. 参数设置: name: 名称 ty ...
- caffe学习系列(4):视觉层介绍
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 这里介绍下conv层. layer { name: & ...
- Caffe学习系列(5):其它常用层及参数
本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accuracy层,reshape层和dropout层及其它们的参数配置. 1.softmax-loss so ...
随机推荐
- gson的安装和使用
gson的安装和使用 1.安装 2.布局 <?xml version="1.0" encoding="utf-8"?> <LinearLayo ...
- 如何使用scss/sass
SCSS 与 Sass 异同:http://sass.bootcss.com/docs/scss-for-sass-users/: 欢迎加入前端交流群来py: 转载请标明出处! 废话不多说,直接进入正 ...
- [雅礼NOIP2018集训 day3]
考试的时候刚了T1两个小时线段树写了三个子任务结果发现看错了题目,于是接下来一个半小时我自闭了 result=历史新低 这告诉我们,打暴力要端正态度,尤其是在发现自己之前出锅的情况下要保持心态的平和, ...
- Synergy 共享键盘和鼠标
直接安装Synergy 不行的话加配置文件 ➜ ~ cat synergy.conf section: screens lab712-PC: ckboss-HP: end section: links ...
- BZOJ 2190 欧拉函数
思路: 递推出来欧拉函数 搞个前缀和 sum[n-1]*2+3就是答案 假设仪仗队是从零开始的 视线能看见的地方就是gcd(x,y)=1的地方 倒过来一样 刨掉(1,1) 就是ans*2+1 再加一下 ...
- Windows版Redis如何使用?(单机)
使用Windows版Redis 1.下载Windows版本的Redis 2.在redis目录里创建redis.conf ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ...
- 新版Eclipse找不到Java EE Module Dependencies选项
在 Eclipse Galileo (3.5) 版本或Ganymede (3.4) 等更老的版本中, 你可以使用Java EE Module Dependencies 选项来组织你的项目结构,确保依赖 ...
- AOP为Aspect Oriented Programming的缩写,意为:面向切面编程
在软件业,AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是OOP的延续,是软件开发中的 ...
- MySQL本地密码过期处理及永不过期设置
今天在使用mysql的时候,提示“your password has expired”,看了一下问题是因为我本地mysql的密码已经过期了,然后搜罗了一下网上的解决办法.(我的mysql版本 5.7. ...
- ActiveMQ学习笔记(4)----JMS的API结构和开发步骤
1. JMS的API结构 其实上图中的五个API在第一节中我们都已经使用到了.本节将会讲非持久化和持久化topic的使用. 2. JMS的基本开发步骤 1. 创建一个JMS工厂, Connectio ...