caffe(3) 视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN)局部相应归一化, im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
type:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
2、Pooling层
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
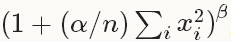 ,得到归一化后的输出
,得到归一化后的输出 layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
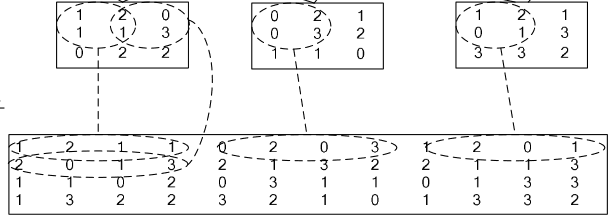
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
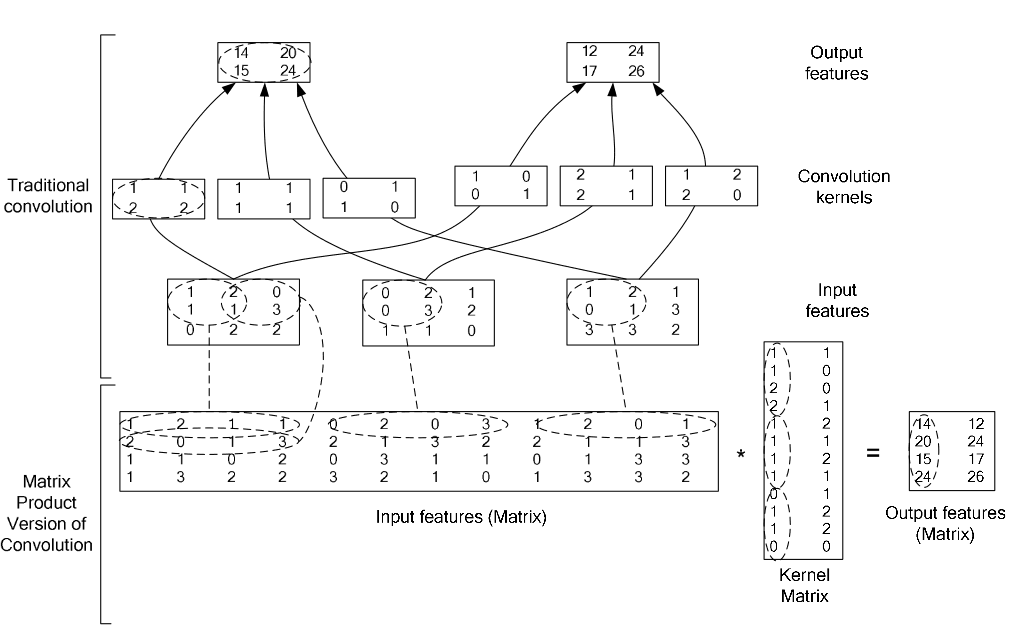
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
caffe(3) 视觉层及参数的更多相关文章
- 【转】Caffe初试(五)视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. ...
- 4、Caffe其它常用层及参数
借鉴自:http://www.cnblogs.com/denny402/p/5072746.html 本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accu ...
- caffe(2) 数据层及参数
要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个屋(layer)构成,每一屋又由许多参数组成.所有的参数都定义在caffe.proto这个文件 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- [caffe]网络各层参数设置
数据层 数据层是模型最底层,提供提供数据输入和数据从Blobs转换成别的格式进行保存输出,通常数据预处理(减去均值,放大缩小,裁剪和镜像等)也在这一层设置参数实现. 参数设置: name: 名称 ty ...
- caffe学习系列(4):视觉层介绍
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 这里介绍下conv层. layer { name: & ...
- Caffe学习系列(5):其它常用层及参数
本文讲解一些其它的常用层,包括:softmax_loss层,Inner Product层,accuracy层,reshape层和dropout层及其它们的参数配置. 1.softmax-loss so ...
随机推荐
- POJ 2502 Dijkstra OR spfa
思路: 建完了图就是模板水题了 -.. 但是建图很坑. 首先要把出发点向地铁站&终点 连一条边 地铁站之间要连无向边 地铁站向终点连一条边 以上的边权要*0.006 两个地铁站之间要连无向边 ...
- jqGrid添加删除功能(不和数据库交互)
jqGrid添加删除功能(不和数据库交互) 一.背景需求 项目中需要在前端页面动态的添加行,删除行,上下移动行等,同时还不和数据库交互.一直在用jqGrid展示表格的我们,从没有深入的研究过它,当然看 ...
- STM8S103之ADC
如何快速了解ADC,查看Reference manual中ADC registers章节,初步了解到ADC ADC buffer register和ADC data register Analog W ...
- 微信小程序------开发测试
一.注册小程序 注:微信小程序注册的邮箱不能被其他微信公众平台注册,未被微信开放平台注册,未被给人微信号绑定的微信号. 二.注册完小程序后,下载开发者工具 开发者工具的使用: 1.打开开发者工具:用已 ...
- seq去除重复数据
DELETE FROM temp_fjh_2 a WHERE a.rowid!=(SELECT MAX(b.rowid) FROM temp_fjh_2 b WHERE a.a=b.a); 表名和列名 ...
- Vue项目结合vux使用
引入vux 1.直接安装或者更新: npm install vux --save 或者使用 yarn yarn add vux // 安装 yarn upgrade vux // 更新 2.vux2必 ...
- VC++ 借助 Win32 API 绘图实现基本的细胞自动机演示
//本程序使用 Visual Studio 2015 生成的 Win32 窗口程序模板 开发//使用 Win32 API 绘图//实现基本的细胞自动机演示////目前已知问题://存在内存泄漏,但具体 ...
- HDU Integer's Power(容斥原理)
题意 求[l,r]的最大指数和(1<=l,r<=10^18) 最大指数和(如64=8^2=4^3=2^6,所以64的最大指数和是6) 题解 很明显我们可以先求出[1,n]的最大指数和,然后 ...
- HDU 1667 The Rotation Game (A*迭代搜索)
题目大意:略 每次选择一个最大深度K,跑IDA* 估价函数H=8-中间8个格里出现次数最多的数的个数x,即把它填满这个数最少需要8-x次操作,如果dep+H>K,就跳出.. 深搜的时候暴力修改, ...
- JavaScript函数写法整理
1.普通函数定义的两种写法 function hello(){ console.log("hello!"); } var hello = function(){ console.l ...