包,logging日志模块,copy深浅拷贝
一 包 package
包就是一个包含了 __init__.py文件的文件夹
包是模块的一种表现形式,包即模块
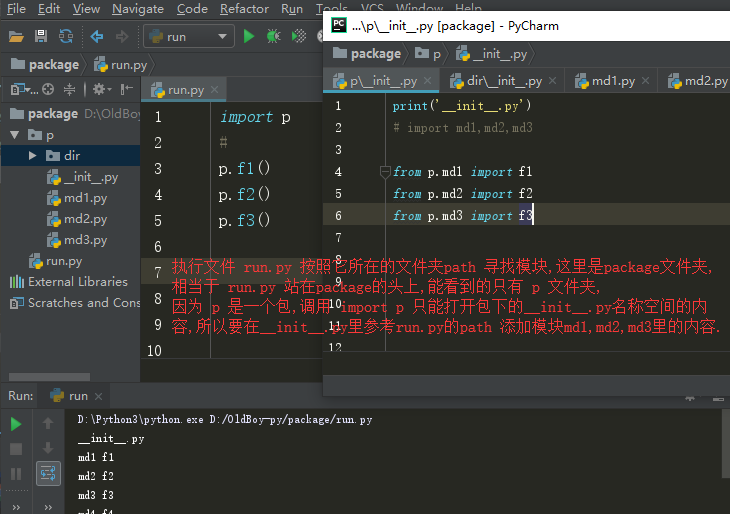
首次导入包:
先创建一个执行文件的名称空间
1.创建包下面的__init__.py文件的名称空间
2.运行包下面的__init__,py文件中的代码,将产生的名字放入放入包下面的__init__.py文件的名称空间
3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间
执行文件在 ' import 包名 ' 的时候拿到的是包下面 __init__.py 文件的名称空间的内容
在导入语句中,点号的左边都是文件夹
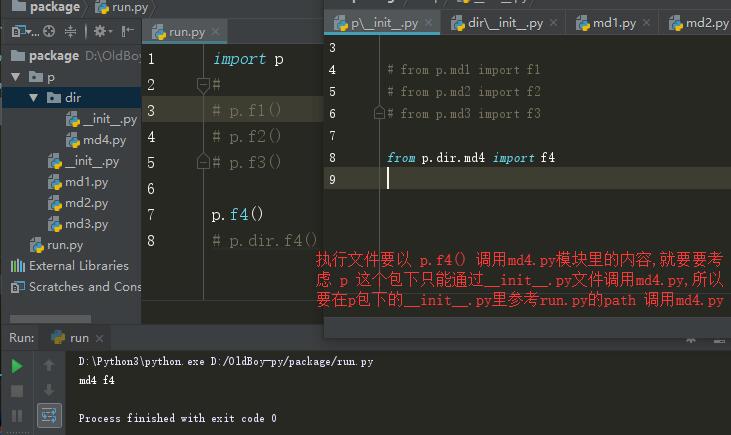
相对导入:
包下的py文件都是用来被导入的模块,所以可以在__init__.py里可以使用相对路径
绝对导入:
缺点:当包的名字改动时,所有的导入语句都需要改动
当你作为包的设计者来说
1.当模块的功能特别多的情况下 应该分文件管理
2.每个模块之间为了避免后期模块改名的问题 你可以使用相对导入(包里面的文件都应该是被导入的模块) 站在包的开发者 如果使用绝对路径来管理的自己的模块 那么它只需要永远以包的路径为基准依次导入模块
站在包的使用者 你必须得将包所在的那个文件夹路径添加到system path中(******) python2如果要导入包 包下面必须要有__init__.py文件
python3如果要导入包 包下面没有__init__.py文件也不会报错
当你在删程序不必要的文件的时候 千万不要随意删除__init__.py文件
二.logging日志模块
日志分五个等级 默认打印到终端
logging.debug('调试日志debug') #
logging.info('消息info') #
logging.warning('警告warn') #
logging.error('错误error') #
logging.critical('严重critical') #
filename='日志文件的名字'
formatter='日志信息的格式'
datefmt='日志时间的格式'
leve=10 # 日志级别 比10大的都执行,一般默认30
stream 是否打印到终端
ps :
1.日志文件默认以 a 模式写入
logging.basicConfig(filename='access.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10,
# stream=True
)
'''日志使用流程步骤'''
1.logger 对象:负责生产日志
logger = logging.getLogger('日志名字')
2.filter 对象:过滤日志(了解)
3.handler 对象:控制日志输入出的位置(文件/终端)
hd1 = logging.FileHandler('文件名字',encoding='utf-8') # 输出到文件中
hd2 = logging.StreamHandler() # 输出到终端
4.format 对象:规定日志内容的格式
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p'
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d'
5.给logging对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
6.给handler绑定formatter对象
hd1.setFormatter(fm1)
hd1.setFormatter(fm2)
7.设置日志等级
logger.setLevel(10)
8.记录日志
logger.debug('logging日志模块')
log配置字典(模板)
import os
import logging # 格式 standard : standard_format
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
# 格式 simple : simple_format
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 定义日志输出格式 结束
"""
下面的两个变量对应的值 需要你手动修改
"""
logfile_dir = os.path.dirname(__file__) # log文件的目录
logfile_name = 'a3.log' # log文件名 # 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir) # log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name) LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 默认都会使用该k:v配置
},
}
三.hashlib加密模块
应用场景:
1.密码的密文存储
2.校验文件内容是否一致
密文算法越复杂,生成的密文越长
消耗的时间越长,占空间越大
通常用md5 就够了
明文转密文的顺序
md = hashlib.md5() # 生成一个造密文的对象,算法是md5
# md.update('hello'.encode('utf-8')) # 往对象里传明文数据 update 只能接受 bytes 类型的数据
md.update(b'hello') # 往对象里传明文数据 update 只能接受 bytes 类型的数据
print(md.hexdigest()) # 获取明文数据对应的密文
传入的内容 可以分多次传入 只要传入的内容相同 那么生成的密文肯定相同
md = hashlib.md5()
md.update(b'areyouok?')
md.update(b'are')
md.update(b'you')
md.update(b'ok?')
print(md.hexdigest()) # 408ac8c66b1e988ee8e2862edea06cc7
# 408ac8c66b1e988ee8e286
加盐处理
import hashlib def get_md5(data):
md = hashlib.md5()
md.update('加盐'.encode('utf-8'))
md.update(data.encode('utf-8'))
return md.hexdigest() password = input('password>>>:')
res = get_md5(password)
print(res)
四.copy深拷贝浅拷贝模块
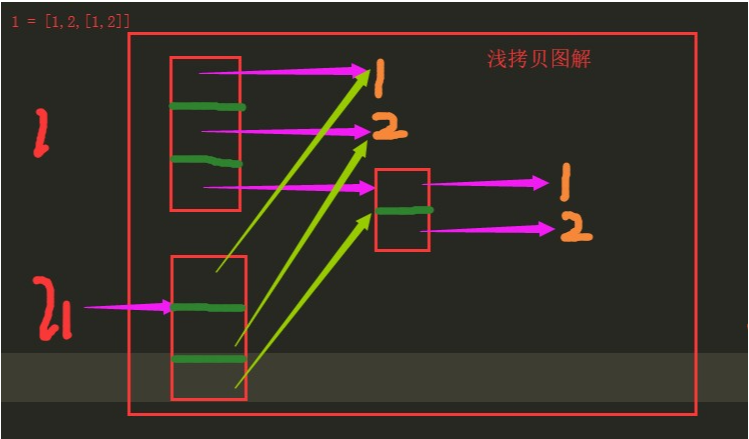
import copy l = [1,2,[1,2]]
# l1 = l
# print(id(l),id(l1)) # 浅拷贝
l1 = copy.copy(l) # 拷贝一份 ....... 浅拷贝
print(id(l),id(l1)) # 相同
l[0] = 222
print(l) # [222, 2, [1, 2]]
print(l1) # [1, 2, [1, 2]]
l[2].append(666)
print(l) # [1, 2, [1, 2, 666]]
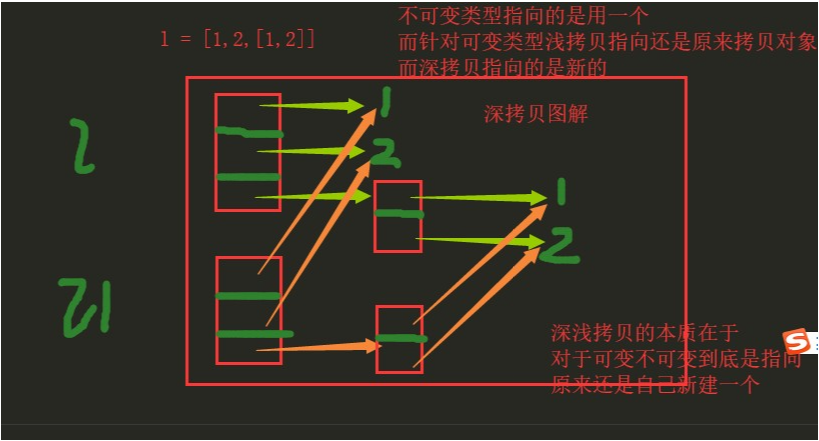
print(l1) # [1, 2, [1, 2, 666]] # 深拷贝
l1 = copy.deepcopy(l)
print(id(l),id(l1)) # 不同
l[2].append(666)
print(l) # [1, 2, [1, 2, 666]]
print(l1) # [1, 2, [1, 2]]
包,logging日志模块,copy深浅拷贝的更多相关文章
- 包、logging模块、hashlib模块、openpyxl模块、深浅拷贝
包.logging模块.hashlib模块.openpyxl模块.深浅拷贝 一.包 1.模块与包 模块的三种来源: 1.内置的 2.第三方的 3.自定义的 模块的四种表现形式: 1.py文件 2.共享 ...
- Python模块04/包/logging日志
Python模块04/包/logging日志 目录 Python模块04/包/logging日志 内容大纲 1.包 2.logging日志 3.今日总结 内容大纲 1.包 2.logging日志 1. ...
- hashlib加密模块、logging日志模块
hashlib模块 加密:将明文数据通过一系列算法变成密文数据 目的: 就是为了数据的安全 基本使用 基本使用 import hashlib # 1.先确定算法类型(md5普遍使用) md5 = ha ...
- logging 日志模块学习
logging 日志模块,用于记录系统在运行过程中的一些关键信息,以便于对系统的运行状况进行跟踪,所以还是灰常重要滴,下面我就来从入门到放弃的系统学习一下日志既可以在屏幕上显示,又可以在文件中体现. ...
- logging日志模块
为什么要做日志: 审计跟踪:但错误发生时,你需要清除知道该如何处理,通过对日志跟踪,你可以获取该错误发生的具体环境,你需要确切知道什么是什么引起该错误,什么对该错误不会造成影响. 跟踪应用的警告和错误 ...
- python 自动化之路 logging日志模块
logging 日志模块 http://python.usyiyi.cn/python_278/library/logging.html 中文官方http://blog.csdn.net/zyz511 ...
- day31 logging 日志模块
# logging 日志模块 ****** # 记录用户行为或者代码执行过程 # print 来回注释比较麻烦的 # logging # 我能够“一键”控制 # 排错的时候需要打印很多细节来帮助我排错 ...
- logging日志模块的使用
logging日志模块的使用 logging模块中有5个日志级别: debug 10 info 20 warning 30 error 40 critical 50 通常使用日志模块,是用字典进行配置 ...
- Python入门之logging日志模块以及多进程日志
本篇文章主要对 python logging 的介绍加深理解.更主要是 讨论在多进程环境下如何使用logging 来输出日志, 如何安全地切分日志文件. 1. logging日志模块介绍 python ...
随机推荐
- poj3630||hdoj1671(字典树)
题目链接:https://vjudge.net/problem/HDU-1671 题意:给定n个字符串,判断是否存在一些字符串是另一些字符串的前缀. 思路: 套模板,存在前缀可能是两种情况: 当前字符 ...
- 【转帖】kubernetes 部署ingress
kubernetes 部署ingress https://www.cnblogs.com/dingbin/p/9754993.html 明天尝试一下 之前的文档里面一直没有提 需要改host文件 我有 ...
- STM32之中断函数
本文做中断函数的索引,帮助我们找到中断函数名.中断函数参数以及中断服务函数他们的来源,以便我们编程. 1)如果一个工程只有一个中断,则我们可以进行两个步骤就可以了: 使能中断通道 编写中断服务函数 2 ...
- Markdown 语法 (转载)
Markdown 语法整理大集合2017 1.标题 代码 注:# 后面保持空格 # h1 ## h2 ### h3 #### h4 ##### h5 ###### h6 ####### h7 // ...
- WUSTOJ的“讨论”和“私聊”功能如何使用
反正我是过了1年多才知道有讨论这个功能,2年多才知道有私聊功能. 不知道大家都是什么时候发现的... 讨论还好,在FAQ界面的下边有提示,但是私聊我真没看到哪儿有提示...是我不小心点进去的. 讨论功 ...
- nmap使用帮助翻译
Nmap 7.60 ( https://nmap.org )Usage: nmap [扫描类型] [操作] {目标说明}目标说明: 可以识别主机名.IP地址.网络,等等. 例如: scanme.n ...
- Istio技术与实践6:Istio如何为服务提供安全防护能力
凡是产生连接关系,就必定带来安全问题,人类社会如此,服务网格世界,亦是如此. 今天,我们就来谈谈Istio第二主打功能---保护服务. 那么,便引出3个问题: l Istio凭什么保护服务? l ...
- Codeforces Round #563 Div. 2
A:显然排序即可. #include<bits/stdc++.h> using namespace std; #define ll long long #define inf 100000 ...
- dapper 参数不定时用这种方法动态参数
string where = null; var p = new DynamicParameters(); if (classId != null) { where = " and clas ...
- Bootstrap4 入门
http://www.runoob.com/bootstrap4/bootstrap4-navs.html 共五个部分 1 <!DOCTYPE html> <html lang=&q ...