Python2下载单张图片和爬取网页图片
一、需求分析
1、知道图片的url地址,将图片下载到本地。
2、知道网页地址,将图片列表中的图片全部下载到本地。
二、准备工作
1、开发系统:win7 64位。
2、开发环境:python2.7。
3、开发工具:PyCharm。
4、浏览器:Chrome。
三、操作步骤
A.知道图片的url地址,将图片下载到本地。
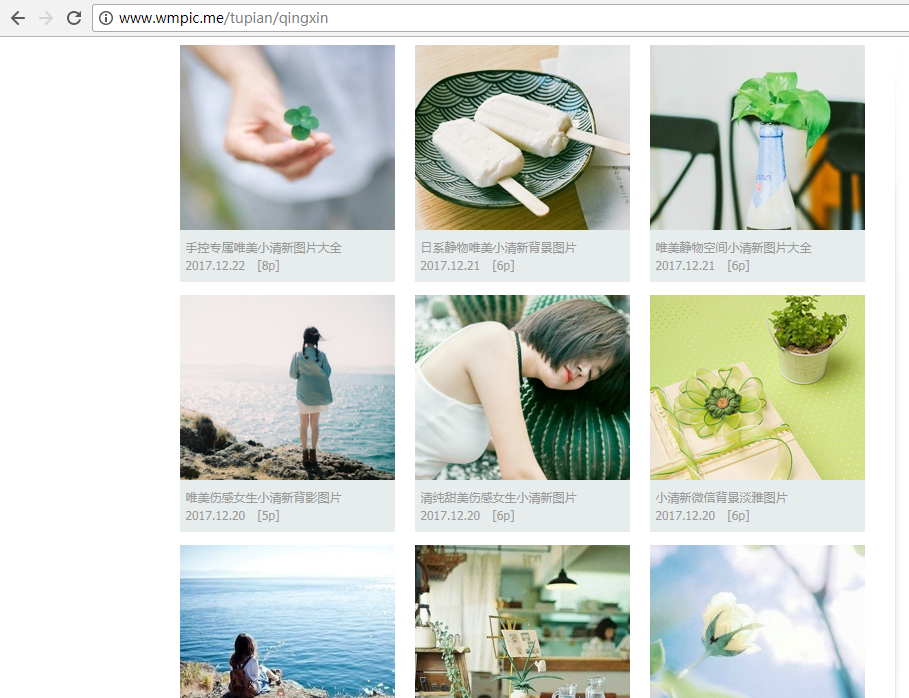
a1、打开Chrome,随意找到一个图片网站。
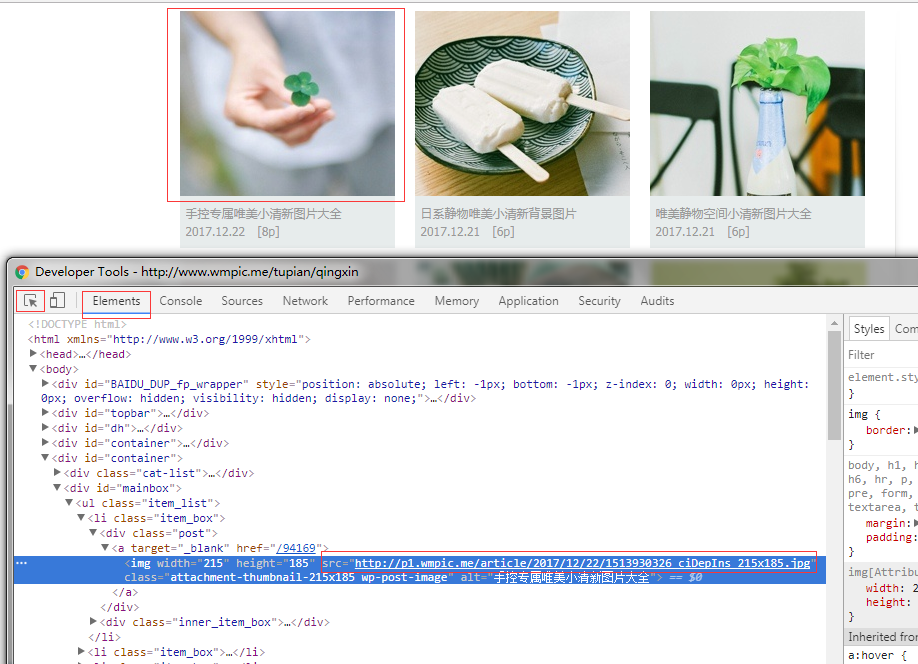
a2、打开开发者工具(f12键或者fn+f12键),选择第一张图片,可以看到它的src属性就是图片的地址,复制出来。
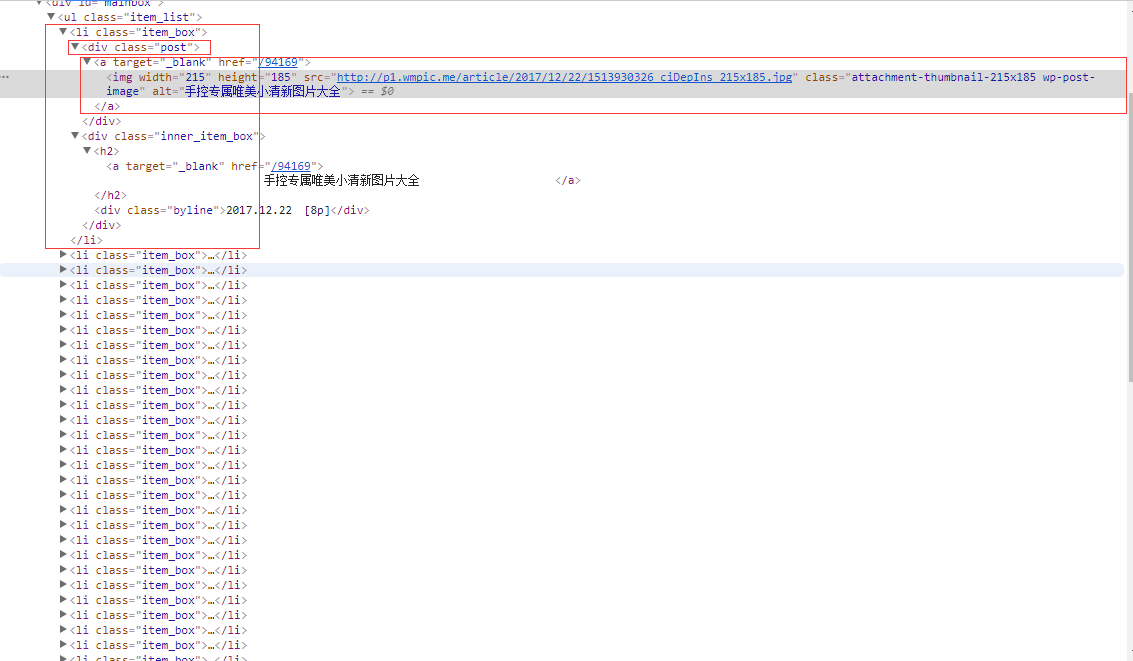
a3、编写代码。这里需要引用urllib库以及使用Python IO相关的知识。
# -*- coding:utf-8 -*
'''
知道图片地址,下载图片到本地
'''
import urllib #图片url地址
url = 'http://p1.wmpic.me/article/2017/12/22/1513930326_ciDepIns_215x185.jpg'
#方法一
#获取图片数据
res = urllib.urlopen(url).read()
#文件要保存的路径名和文件名
path = "e:\dlimg\pic2.jpg"
#使用io写入图片
f = open(path , "wb")
f.write(res)
f.close()
#方法二
res2 = urllib.urlretrieve(url , 'e:\dlimg\pic3.jpg')
B.知道网页地址,将图片列表中的图片全部下载到本地。
b1、还是以上面的网页为爬取对象,在该网页下,图片列表中有30张照片,获取每张图片的src属性值,再来下载即可。
b2、利用BeautifulSoup解析网页,利用标签选择器获取每张图片的src属性值。
b3、编写代码。
# -*- coding: utf-8 -*- import requests
import urllib
from bs4 import BeautifulSoup url = 'http://www.wmpic.me/tupian/qingxin'
res = requests.get(url)
#使用BeautifulSoup解析网页
soup = BeautifulSoup(res.text , 'html.parser')
#通过标签选择器定位到图片位置(与css选择器差不多)
pic_list = soup.select('.item_box .post a img')
i = 0
for img_url in pic_list:
#获取每个img标签的src属性
url_list = img_url['src']
#保存路径,后面是文件名
save_path = 'E:\dlimg\\'+'downloadpic_'+str(i)+'.jpg'
#解析图片,写入到本地
pic_file = urllib.urlopen(url_list).read()
f = open(save_path, "wb")
f.write(pic_file)
f.close()
i = i+1
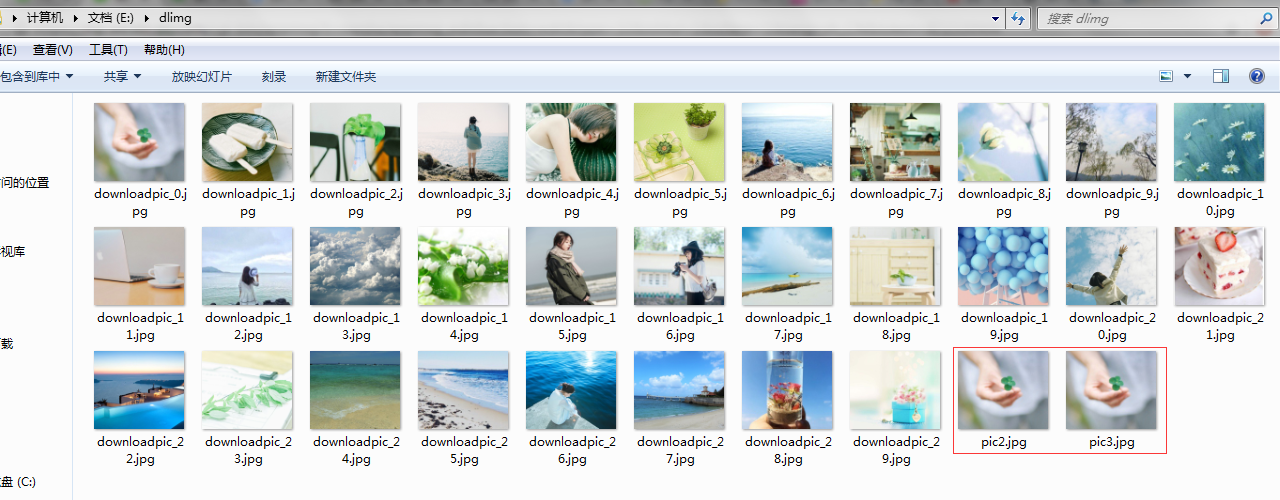
C.运行结果(红色框中pic2.jpg和pic3.jpg是A步骤运行结果,其余以downloadpic_*.jpg命名的图片是步骤B的运行结果)
文章首发于我的个人公众号:悦乐书。喜欢分享一路上听过的歌,看过的电影,读过的书,敲过的代码,深夜的沉思。期待你的关注!

Python2下载单张图片和爬取网页图片的更多相关文章
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- erlang 爬虫——爬取网页图片
说起爬虫,大家第一印象就是想到了python来做爬虫.其实,服务端语言好些都可以来实现这个东东. 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌 ...
- python爬取网页图片(二)
从一个网页爬取图片已经解决,现在想要把这个用户发的图片全部爬取. 首先:先找到这个用户的发帖页面: http://www.acfun.cn/u/1094623.aspx#page=1 然后从这个页面中 ...
- 利用Python爬取网页图片
最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片 ...
- Python3批量爬取网页图片
所谓爬取其实就是获取链接的内容保存到本地.所以爬之前需要先知道要爬的链接是什么. 要爬取的页面是这个:http://findicons.com/pack/2787/beautiful_flat_ico ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
- Python学习--两种方法爬取网页图片(requests/urllib)
实际上,简单的图片爬虫就三个步骤: 获取网页代码 使用正则表达式,寻找图片链接 下载图片链接资源到电脑 下面以博客园为例子,不同的网站可能需要更改正则表达式形式. requests版本: import ...
随机推荐
- ajax事件请求
首先,ajax是什么? ajax是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术. ajax是一种用于创建的快速动态网页的技术. 当async:true时,表示异步执行ajax代码:当as ...
- 在foreach的判断条件里执行方法会有效率问题吗?
楼猪平时一有空就有看别人代码的习惯,从许多优秀规范的代码中学习到了很多简约高效的写法和画龙点睛的思想精华.但是有的时候也会觉得某些写法很值得玩味.比如刚看到一段代码,在foreach的条件判断里加了一 ...
- Win10下Docker学习(1)安装
Docker简介 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制, ...
- Oracle数据库应用
Oracle数据库应用 一:.Oracle数据库应用知识 二:表空间和用户权限管理 表空间: 表空间是数据逻辑结构的一个重要组件,表空间可以存放各种应用对象,如表,索引.而每个表空间由一个或者多个数据 ...
- 机器学习(二)-kNN手写数字识别
一.kNN算法是机器学习的入门算法,其中不涉及训练,主要思想是计算待测点和参照点的距离,选取距离较近的参照点的类别作为待测点的的类别. 1,距离可以是欧式距离,夹角余弦距离等等. 2,k值不能选择太大 ...
- svg-写一个简单的进度条
html <div class="container"> <div class="line-wrap"> <svg version ...
- 《java.util.concurrent 包源码阅读》09 线程池系列之介绍篇
concurrent包中Executor接口的主要类的关系图如下: Executor接口非常单一,就是执行一个Runnable的命令. public interface Executor { void ...
- swaggerui在asp.net web api core 中的应用
Swaggerui 可以为我们的webapi提供美观的在线文档,如下图: 实现步骤: NuGet Packages Install-Package Swashbuckle.AspNetCore 在s ...
- JavaScript学习笔记(十三)——生成器(generator)
在学习廖雪峰前辈的JavaScript教程中,遇到了一些需要注意的点,因此作为学习笔记列出来,提醒自己注意! 如果大家有需要,欢迎访问前辈的博客https://www.liaoxuefeng.com/ ...
- Ipad弹出UIAlertControllerStyleActionSheet时发生崩溃
pad弹出UIAlertControllerStyleActionSheet时,在iphone上运行正常,但在ipad上崩溃,解决代码如下: UIAlertController *alertVc = ...