Hadoop 新生报道(二) hadoop2.6.0 集群系统版本安装和启动配置
本次基于Hadoop2.6版本进行分布式配置,Linux系统是基于CentOS6.5 64位的版本。在此设置一个主节点和两个从节点。
准备3台虚拟机,分别为:
|
主机名 |
IP地址 |
|
master |
192.168.80.10 |
|
slave1 |
192.168.80.11 |
|
slave2 |
192.168.80.12 |
1.修改主机名称,把三个节点分别修改下面的文件,修改主机名为master,slave1,slave2(root用户操作),重启生效
vi /etc/sysconfig/network
2.把三个节点的防火墙关闭,在三个节点分别执行(root用户操作)
/etc/init.d/iptables stop

3.在三个节点修改配置hosts文件,在hosts文件中分别配置三个节点的主机名 ip地址映射(root用户操作)

4.在master和slave之间配置SSH互信(hadoop用户操作)
分别在master和slave1,master和slave2,master和master之间配置互信
a) 分别在master、slave1、slave2执行下面的命令生成公钥和私钥
ssh-keygen
在hadoop用户根目录下,有一个.ssh目录
id_rsa 私钥
id_rsa.pub 公钥
known_hosts 通过SSH链接到本主机,都会在这里有记录
b) 在master输入下面的命令,和master,slave1,slave2创建互信
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2

注意:复制的过程中需要输入信任主机的密码
!!!!每次ssh完都会进入其他的主机,千万在ssh完了以后退出对配置机器的远程控制,ctrl+d
5.把JDK和Hadoop安装包(资料包目录下的文件)上传到master节点系统(hadoop用户的根目录),用XFtp
6.在三个节点下面配置jdk。在hadoop用户的根目录,Jdk解压,(hadoop用户操作)
tar -zxvf jdk-8u65-linux-x64.tar.gz

7.三个节点配置环境变量,需要修改/etc/profile文件(root用户操作)
切到root用户,输入su命令
su
vi /etc/profile
进去编辑器后,输入i,进入vi编辑器的插入模式,在profile文件最后添加
|
JAVA_HOME=/home/hadoop/jdk1.8.0_65 export PATH=$PATH:$JAVA_HOME/bin |
编辑完成后,按下esc退出插入模式
输入:,这时在左下角有一个冒号的标识
q 退出不保存
wq 保存退出
q! 强制退出
8.在三个节点把修改的环境变量生效(hadoop用户操作),jdk配置完成
source /etc/profile
9.下面配置hadoop,在hadoop用户的根目录,解压(hadoop用户操作)
tar -zxvf hadoop-2.6.0.tar.gz

10.修改配置文件hadoop-2.6.0/etc/hadoop/slaves,输入下面内容,每一行是一个从节点主机名称(hadoop用户操作)
slave1
slave2
12.修改配置文件hadoop-2.6.0/etc/hadoop/hadoop-env.sh(hadoop用户操作)
export JAVA_HOME=/home/hadoop/jdk1.8.0_65
13.修改配置文件hadoop-2.6.0/etc/hadoop/core-site.xml,添加(hadoop用户操作)
|
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hadoop/tmp</value> <description>Abasefor other temporary directories.</description> </property> |
13.修改配置文件hadoop-2.6.0/etc/hadoop/hdfs-site.xml,添加(hadoop用户操作)
|
<property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> |
14.修改修改配置文件hadoop-2.6.0/etc/hadoop/mapred-site.xml (hadoop用户操作),这个文件没有,需要复制一份
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
添加
|
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> |
15.修改配置文件hadoop-2.6.0/etc/hadoop/yarn-site.xml,添加(hadoop用户操作)
|
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> |
16.将配置好的hadoop文件copy到另外slave机器上(hadoop用户操作)
scp -r hadoop-2.6.0/ hadoop@slave1:~/hadoop
scp -r hadoop-2.6.0/ hadoop@slave2:~/hadoop
17.格式化HDFS,在hadoop解压目录下,执行如下命令:(hadoop用户操作)
bin/hdfs namenode -format
注意:格式化只能操作一次,如果因为某种原因,集群不能用, 需要再次格式化,需要把上一次格式化的信息删除,在三个节点用户根目录里执行 rm -rf /home/hadoop/hadoop/dfs
18.启动集群,在hadoop解压目录下,执行如下命令:(hadoop用户操作)
sbin/start-all.sh
19.查看hadoop的web接口,在浏览器输入:主机名:50070。如:http://master:50070
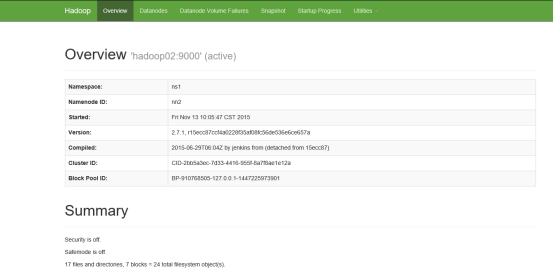
启动以后jps查看,master有4个线程,slave1和slave2都有3个线程,其中都有一个是jps
Hadoop 新生报道(二) hadoop2.6.0 集群系统版本安装和启动配置的更多相关文章
- 国内最全最详细的hadoop2.2.0集群的MapReduce的最简单配置
简介 hadoop2的中的MapReduce不再是hadoop1中的结构已经没有了JobTracker,而是分解成ResourceManager和ApplicationMaster.这次大变革被称为M ...
- 分布式Hbase-0.98.4在Hadoop-2.2.0集群上的部署
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3898991.html Hbase 是Apache Hadoop的数据库,能够对大数据提 ...
- CentOS6.4上搭建hadoop-2.4.0集群
公司Commerce Cloud平台上提供申请主机的服务.昨天试了下,申请了3台机器,搭了个hadoop环境.以下是机器的一些配置: emi-centos-6.4-x86_64medium | 6GB ...
- hadoop-2.6.0集群开发环境配置
hadoop-2.6.0集群开发环境配置 一.环境说明 1.1安装环境说明 本例中,操作系统为CentOS 6.6, JDK版本号为JDK 1.7,Hadoop版本号为Apache Hadoop 2. ...
- Ubuntu12.04-x64编译Hadoop2.2.0和安装Hadoop2.2.0集群
本文Blog地址:http://www.cnblogs.com/fesh/p/3766656.html 本文对Hadoop-2.2.0源码进行重新编译(64位操作系统下不重新编译会有版本问题) ...
- 在Hadoop-2.2.0集群上安装 Hive-0.13.1 with MySQL
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3872872.html 软件环境 操作系统:Ubuntu14.04 JDK版本:jdk1 ...
- Hadoop-2.6.0 集群的 安装与配置
1. 配置节点bonnie1 hadoop环境 (1) 下载hadoop- 2.6.0 并解压缩 [root@bonnie1 ~]# wget http://apache.fayea.com/had ...
- Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作
前言 安装Apache Hive前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可,安装前需保证Hadoop已启(动文中用到了hadoop的hdfs命 ...
- hadoop2.2.0集群搭建与部署
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3818908.html 一.安装环境 1.系统环境 CentOS 6.4 2.集群机器节点ip 节点一i ...
随机推荐
- Redis 数据类型介绍
http://qifuguang.me/2015/09/29/Redis%E4%BA%94%E7%A7%8D%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B%E4%BB%8B% ...
- java 动态代理的实现
http://www.cnblogs.com/jqyp/archive/2010/08/20/1805041.html
- jeecg关闭当前iframe
关闭当前iframe function closeDialog(){ frameElement.api.close();//本方法也行 //或者下面的方式 var win = frameElement ...
- Python Click 学习笔记(转)
原文链接:Python Click 学习笔记 Click 是 Flask 的团队 pallets 开发的优秀开源项目,它为命令行工具的开发封装了大量方法,使开发者只需要专注于功能实现.恰好我最近在开发 ...
- python中的字符串编码
获取字符串的编码类型: encodingdate = chardet.detect(str) chardet用于实现字符串的编码类型检测 chardet的下载地址:https://pypi.pytho ...
- 【Android Developers Training】 41. 向另一台设备发送文件
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- kbengine_js_plugins 在Cocos Creator中适配
kbengine_js_plugins 改动(2017/7/6) 由于Cocos Creator使用严格模式的js,而原本的kbengine_js_plugins是非严格模式的,因此为了兼容和方 便C ...
- 在使用<script>嵌入JavaScript代码时,不要在代码中的任何地方出现"</script>"字符串
在使用<script>嵌入JavaScript代码时,记住不要在代码中的任何地方出现"</script>"字符串.例如浏览器执行下面代码会报错: <s ...
- centos7使用cobbler(2.8)批量部署操作系统之一
一. 批量部署操作系统的前提 要想批量部署操作系统,得具备以下条件: 客户机支持pxe网络引导 服务器端和客户端建立网络通信(DHCP) 服务器端要有可供客户机开机引导的引导文件 服务器端的可引 ...
- Spring Data JPA 复杂/多条件组合查询
1: 编写DAO类或接口 dao类/接口 需继承 public interface JpaSpecificationExecutor<T> 接口: 如果需要分页,还可继承 public ...