【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell
主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践。






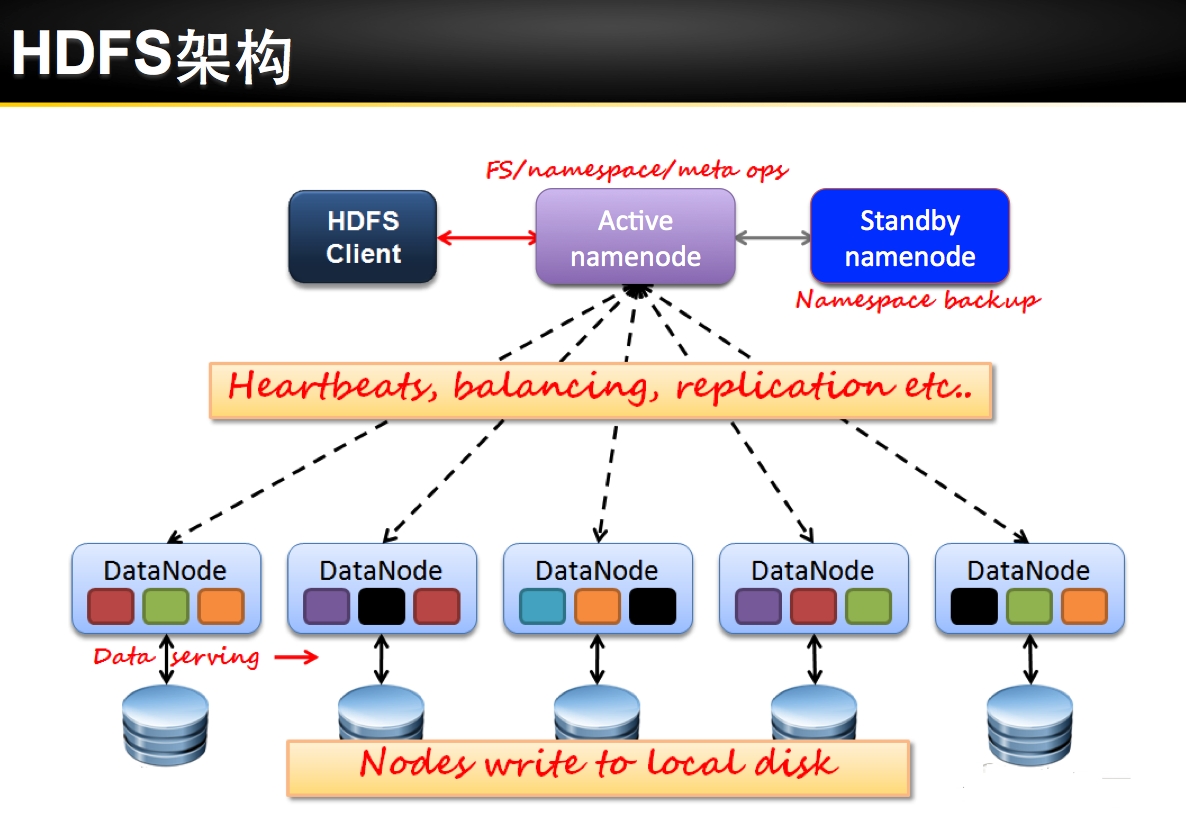

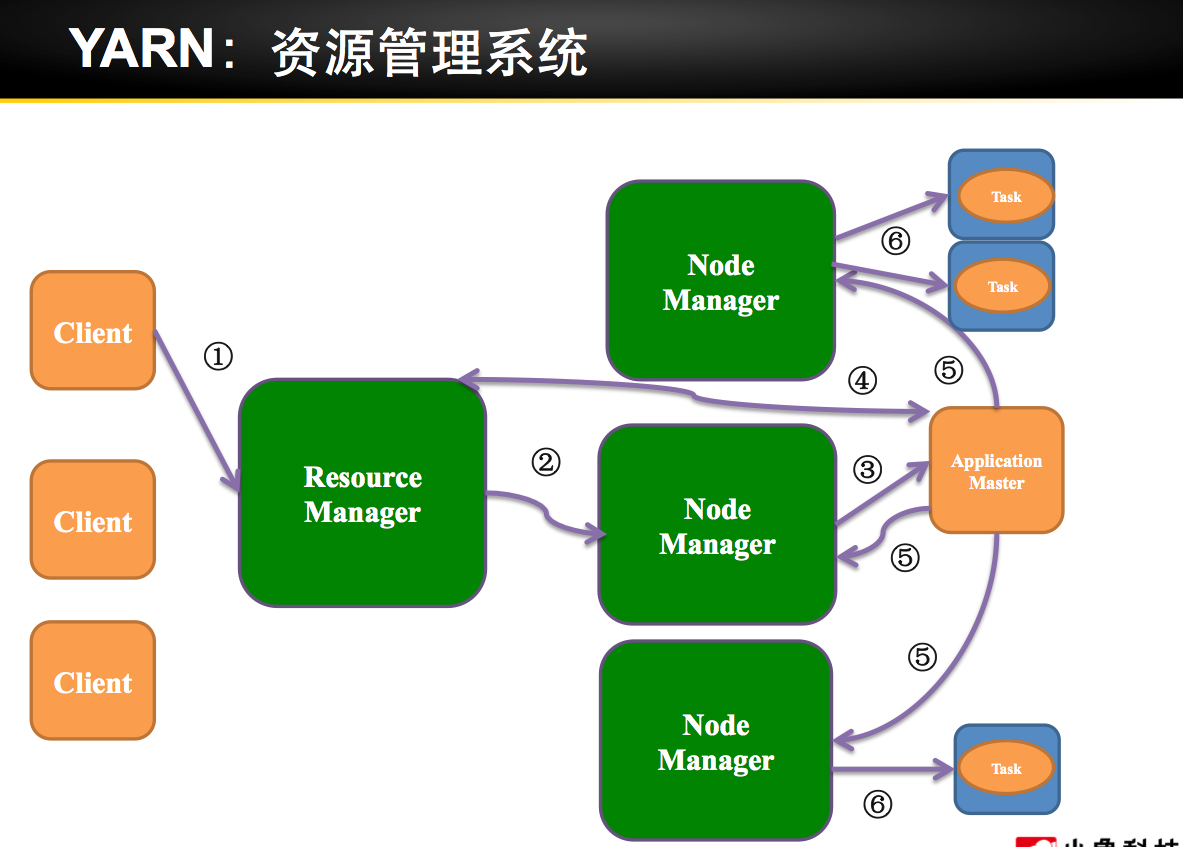




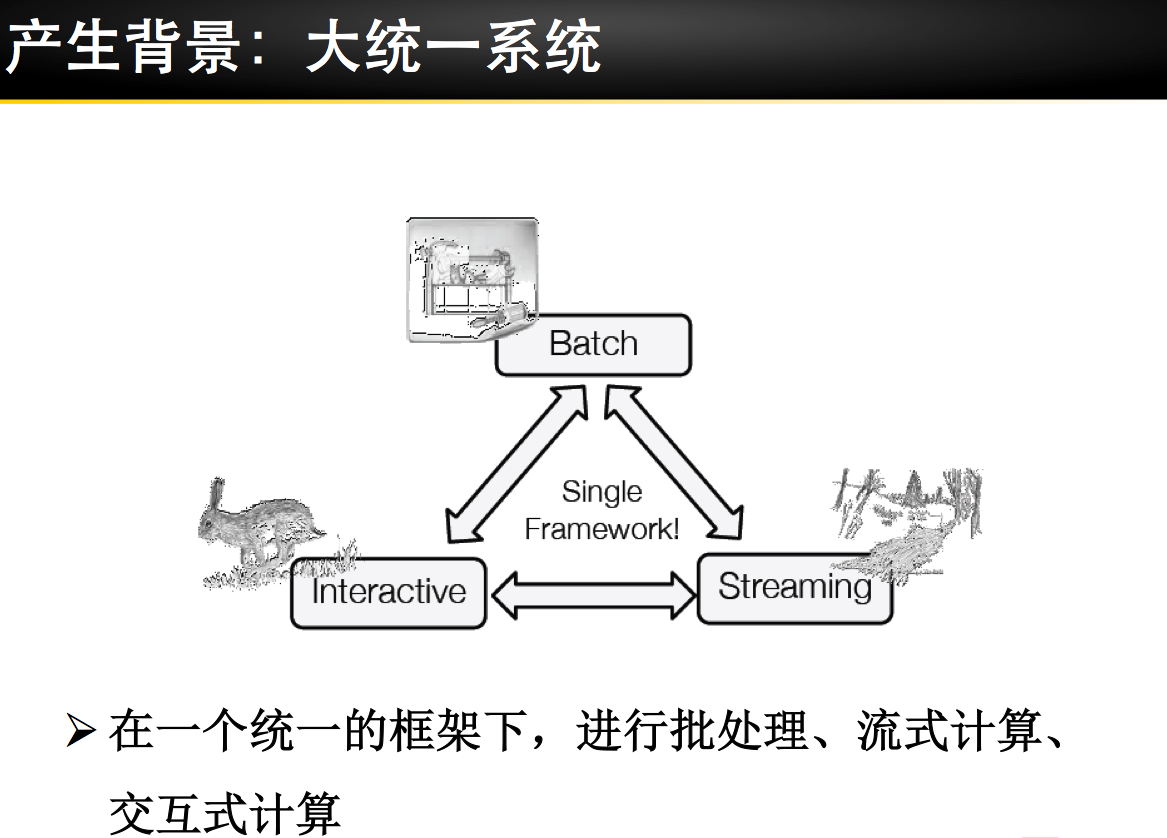



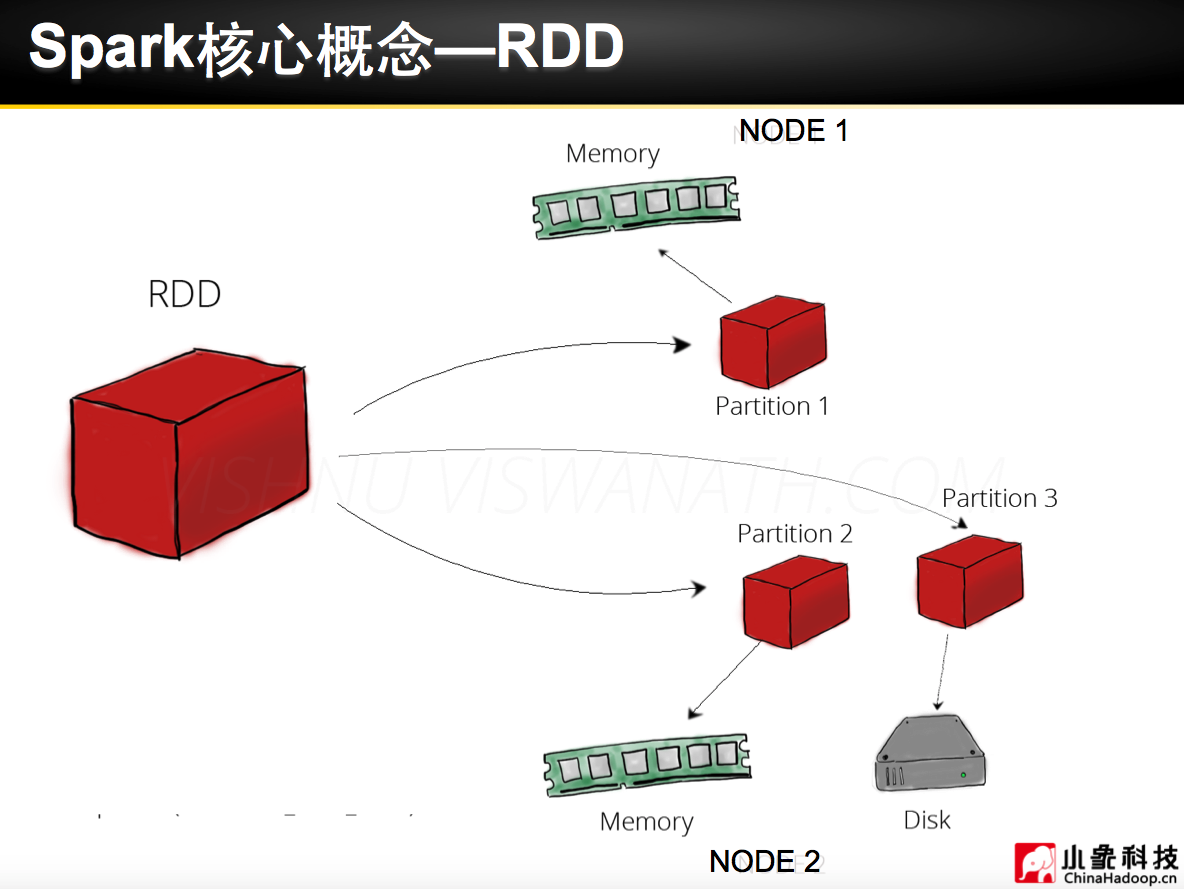

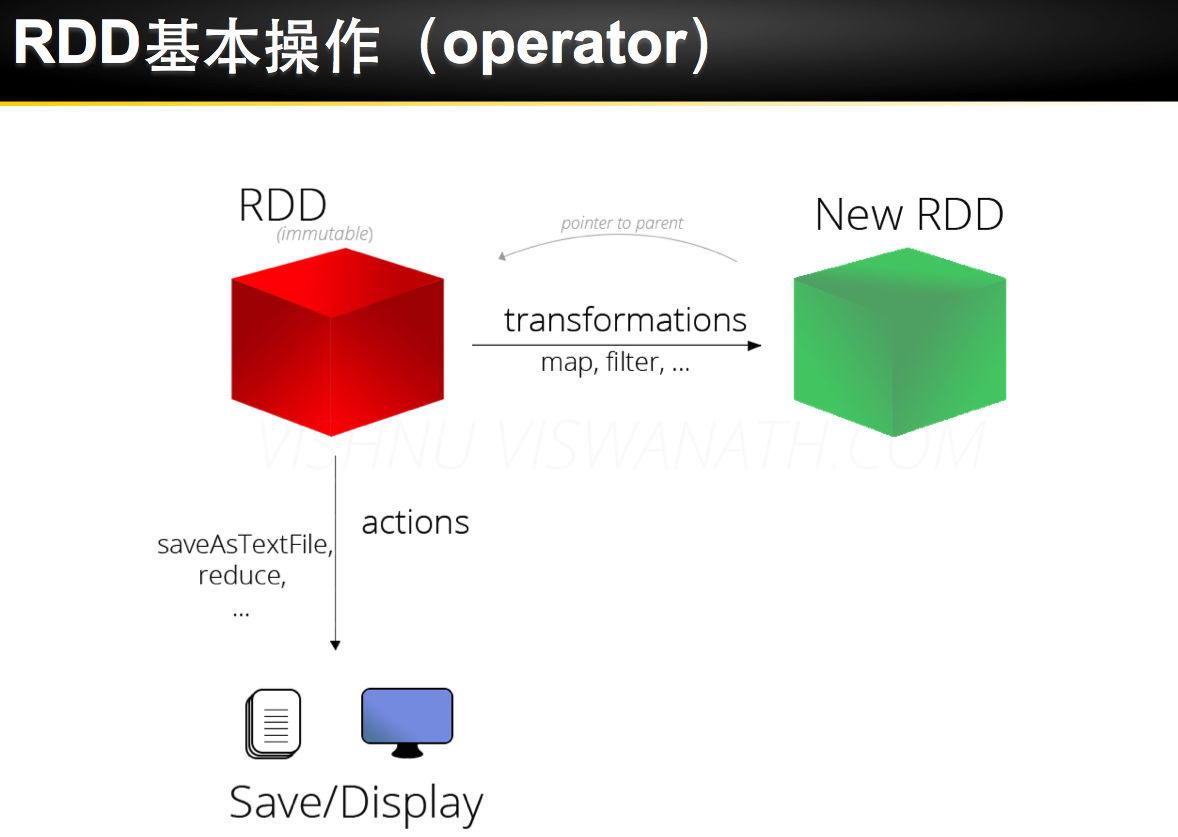

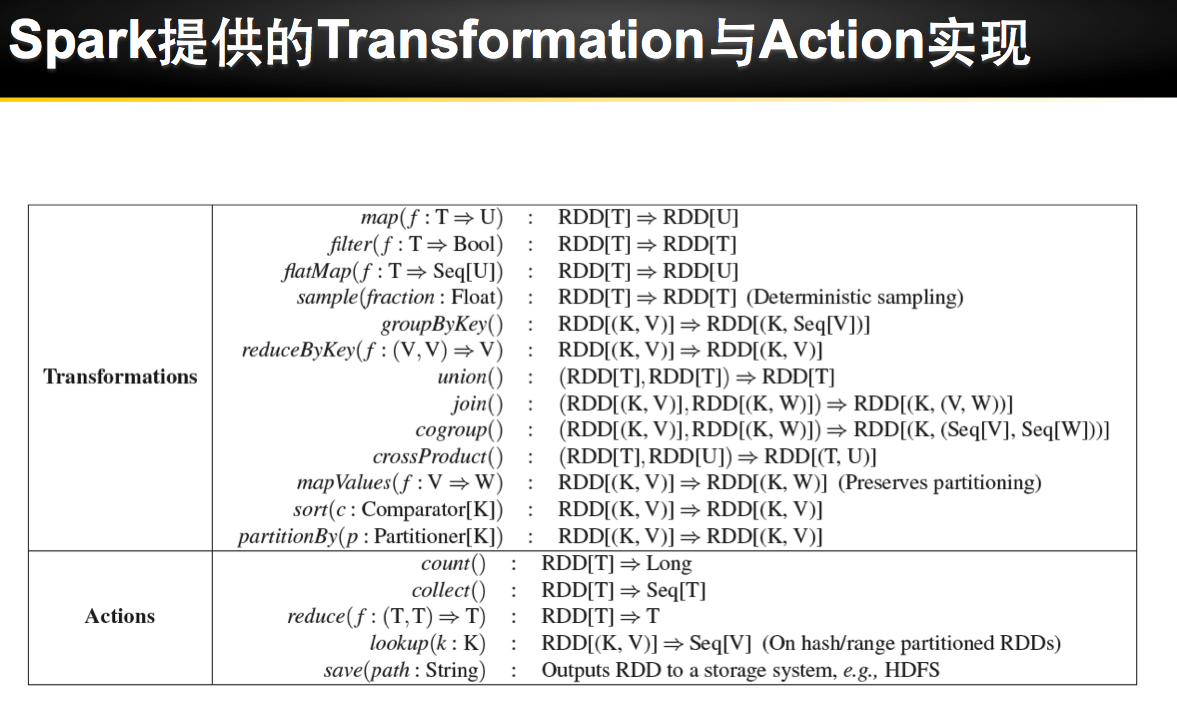






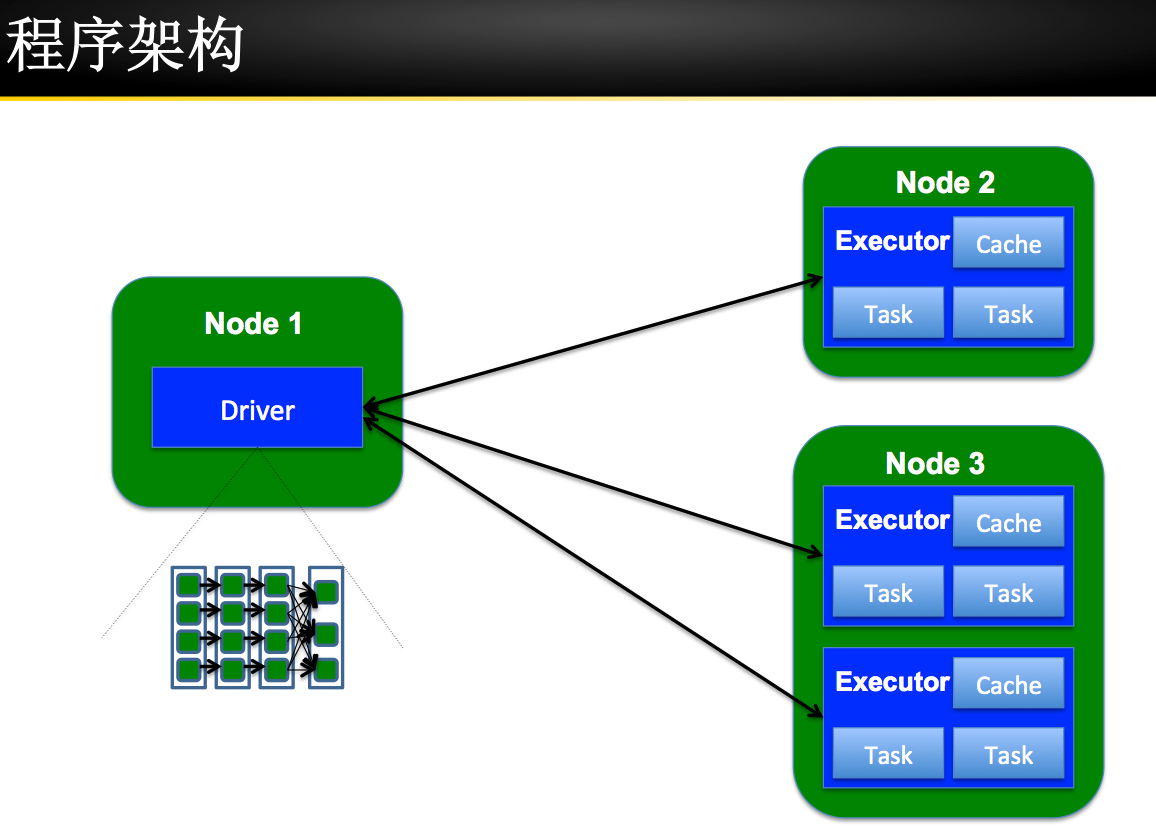


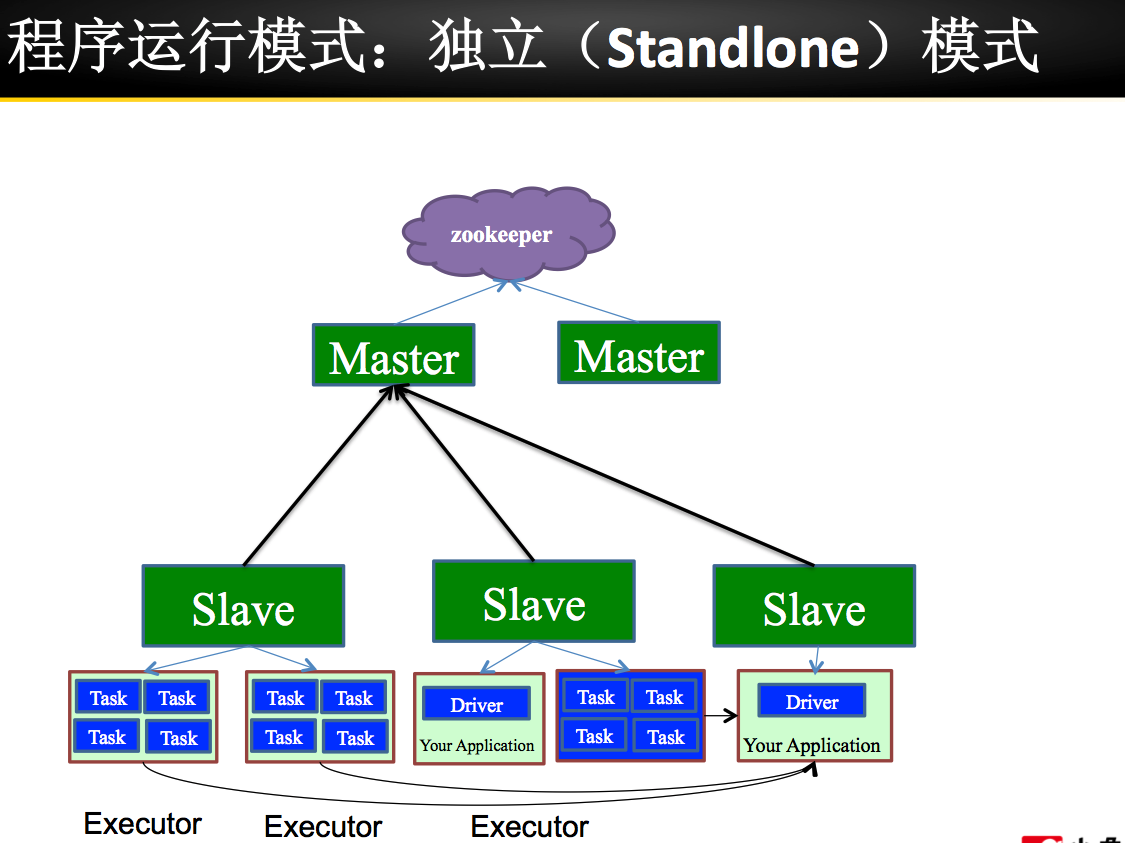
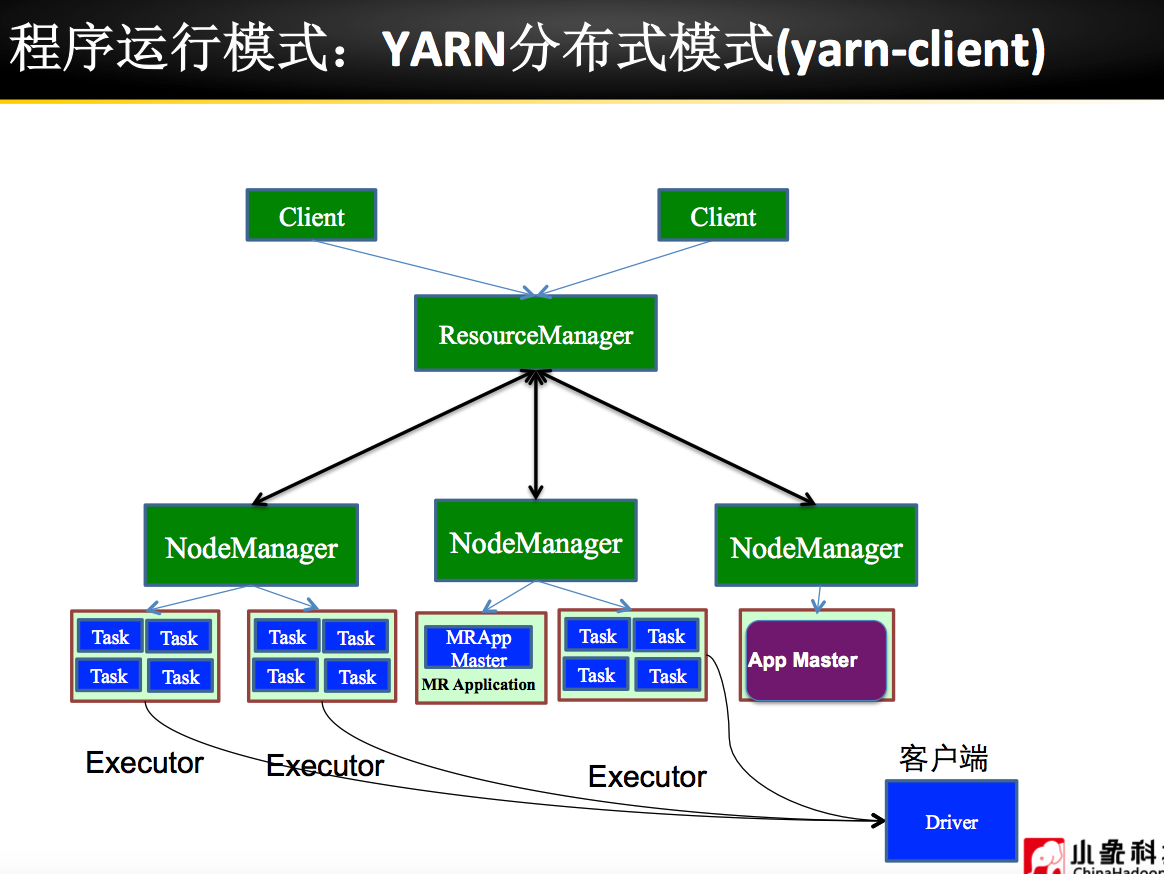
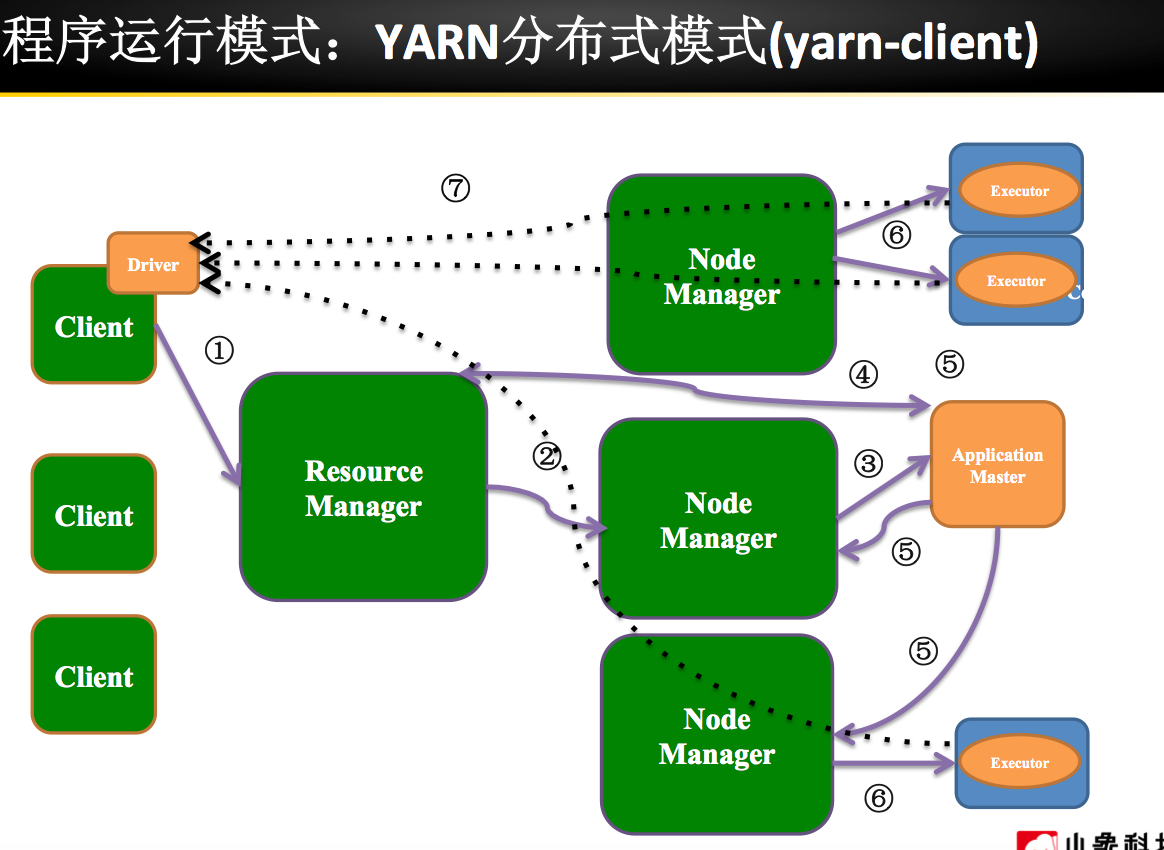





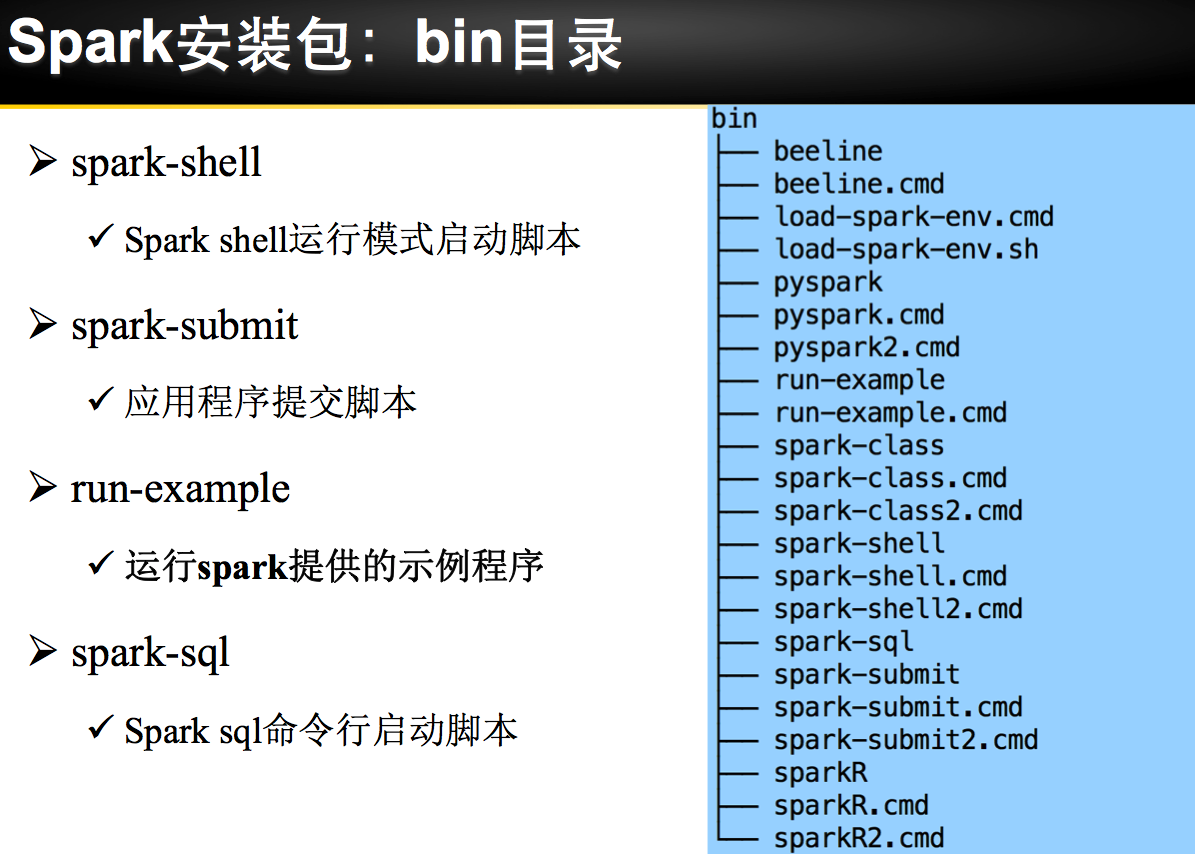
Spark 安装部署














理论已经了解的差不多了,接下来是实际动手实验:
练习1 利用Spark Shell(本机模式) 完成WordCount
spark-shell 进行Spark-shell本机模式

第一步:通过文件方式导入数据
scala> val rdd1 = sc.textFile("file:///tmp/wordcount.txt")
rdd1: org.apache.spark.rdd.RDD[String] = file:///tmp/wordcount.txt MapPartitionsRDD[3] at textFile at <console>:24
scala> rdd1.count
res1: Long = 3

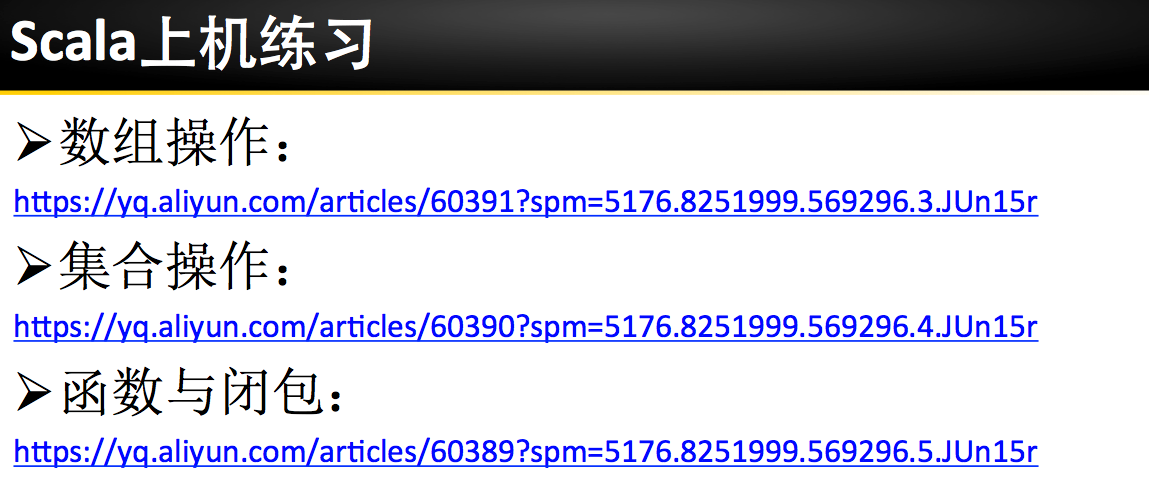
第二步:利用flatmap(_.split(" ")) 进行分词操作
scala> val rdd2 = rdd1.flatMap(_.split(" "))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at flatMap at <console>:26
scala> rdd2.count
res2: Long = 8
scala> rdd2.take
take takeAsync takeOrdered takeSample
scala> rdd2.take(8)
res3: Array[String] = Array(hello, world, spark, world, hello, spark, hadoop, great)
第三步:利用map 转化为KV的形式
scala> val kvrdd1 = rdd2.map(x => (x,1))
kvrdd1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at map at <console>:28
scala> kvrdd1.count
res4: Long = 8
scala> kvrdd1.take(8)
res5: Array[(String, Int)] = Array((hello,1), (world,1), (spark,1), (world,1), (hello,1), (spark,1), (hadoop,1), (great,1))

第四步:把KV的map进行ReduceByKey操作
scala> val resultRdd1 = kvrdd1.reduceByKey(_+_)
resultRdd1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[6] at reduceByKey at <console>:30
scala> resultRdd1.count
res6: Long = 5
scala> resultRdd1.take(5)
res7: Array[(String, Int)] = Array((hello,2), (world,2), (spark,2), (hadoop,1), (great,1))

第五步:将结果保持到文件之中
scala> resultRdd1.saveAsTextFile("file:///tmp/output1")

练习2 利用Spark Shell(Yarn Client模式) 完成WordCount
spark-shell --master yarn-client 启动Spark-shell Yarn Client模式

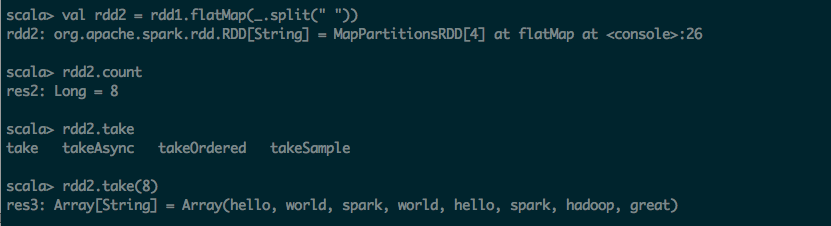
第一步:通过文件方式导入数据
scala> val rdd1 = sc.textFile("hdfs:///input/wordcount.txt")
rdd1: org.apache.spark.rdd.RDD[String] = hdfs:///input/wordcount.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> rdd1.count
res0: Long = 260
scala> rdd1.take(100)
res1: Array[String] = Array(HDFS Users Guide, "", HDFS Users Guide, Purpose, Overview, Prerequisites, Web Interface, Shell Commands, DFSAdmin Command, Secondary NameNode, Checkpoint Node, Backup Node, Import Checkpoint, Balancer, Rack Awareness, Safemode, fsck, fetchdt, Recovery Mode, Upgrade and Rollback, DataNode Hot Swap Drive, File Permissions and Security, Scalability, Related Documentation, Purpose, "", This document is a starting point for users working with Hadoop Distributed File System (HDFS) either as a part of a Hadoop cluster or as a stand-alone general purpose distributed file system. While HDFS is designed to “just work” in many environments, a working knowledge of HDFS helps greatly with configuration improvements and diagnostics on a specific cluster., "", Overview, "",...
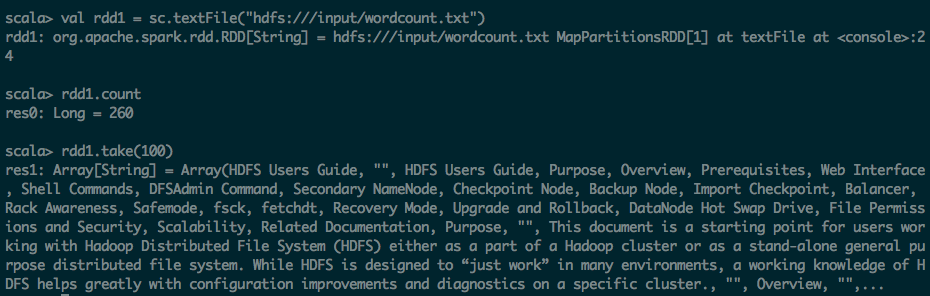
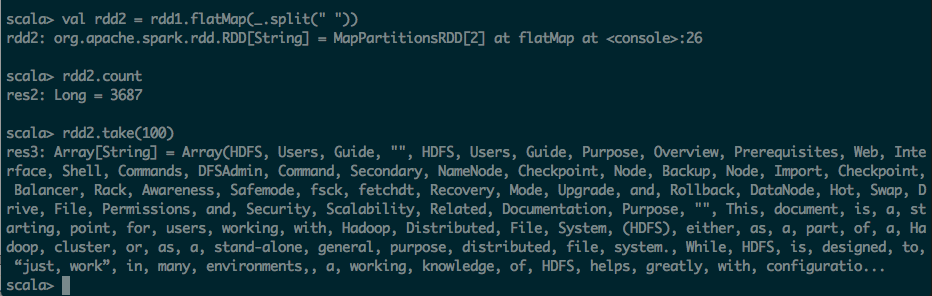
第二步:利用flatmap(_.split(" ")) 进行分词操作
scala> val rdd2 = rdd1.flatMap(_.split(" "))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:26
scala> rdd2.count
res2: Long = 3687
scala> rdd2.take(100)
res3: Array[String] = Array(HDFS, Users, Guide, "", HDFS, Users, Guide, Purpose, Overview, Prerequisites, Web, Interface, Shell, Commands, DFSAdmin, Command, Secondary, NameNode, Checkpoint, Node, Backup, Node, Import, Checkpoint, Balancer, Rack, Awareness, Safemode, fsck, fetchdt, Recovery, Mode, Upgrade, and, Rollback, DataNode, Hot, Swap, Drive, File, Permissions, and, Security, Scalability, Related, Documentation, Purpose, "", This, document, is, a, starting, point, for, users, working, with, Hadoop, Distributed, File, System, (HDFS), either, as, a, part, of, a, Hadoop, cluster, or, as, a, stand-alone, general, purpose, distributed, file, system., While, HDFS, is, designed, to, “just, work”, in, many, environments,, a, working, knowledge, of, HDFS, helps, greatly, with, configuratio...
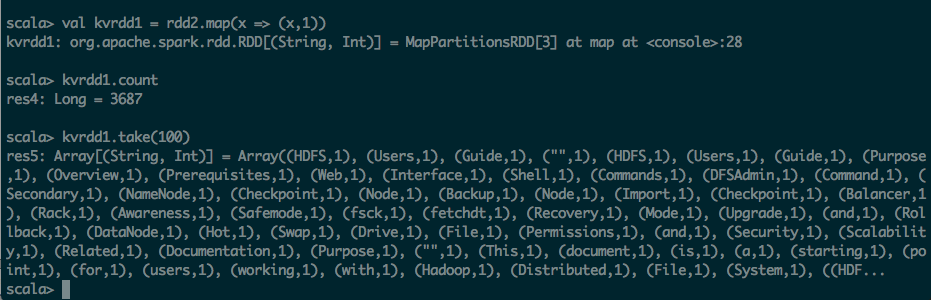
第三步:利用map 转化为KV的形式
scala> val kvrdd1 = rdd2.map(x => (x,1))
kvrdd1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:28
scala> kvrdd1.count
res4: Long = 3687
scala> kvrdd1.take(100)
res5: Array[(String, Int)] = Array((HDFS,1), (Users,1), (Guide,1), ("",1), (HDFS,1), (Users,1), (Guide,1), (Purpose,1), (Overview,1), (Prerequisites,1), (Web,1), (Interface,1), (Shell,1), (Commands,1), (DFSAdmin,1), (Command,1), (Secondary,1), (NameNode,1), (Checkpoint,1), (Node,1), (Backup,1), (Node,1), (Import,1), (Checkpoint,1), (Balancer,1), (Rack,1), (Awareness,1), (Safemode,1), (fsck,1), (fetchdt,1), (Recovery,1), (Mode,1), (Upgrade,1), (and,1), (Rollback,1), (DataNode,1), (Hot,1), (Swap,1), (Drive,1), (File,1), (Permissions,1), (and,1), (Security,1), (Scalability,1), (Related,1), (Documentation,1), (Purpose,1), ("",1), (This,1), (document,1), (is,1), (a,1), (starting,1), (point,1), (for,1), (users,1), (working,1), (with,1), (Hadoop,1), (Distributed,1), (File,1), (System,1), ((HDF...
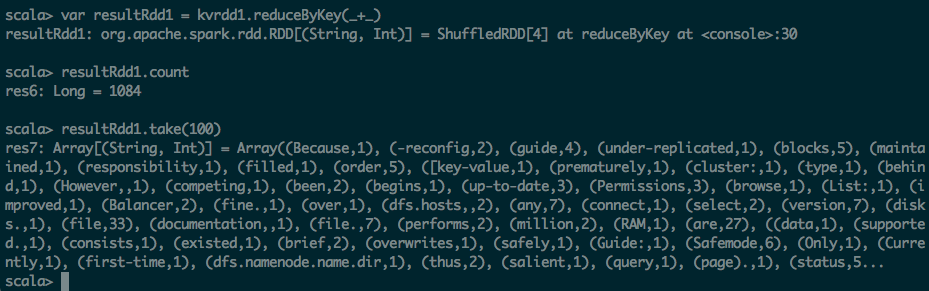
第四步:把KV的map进行ReduceByKey操作
scala> var resultRdd1 = kvrdd1.reduce
reduce reduceByKey reduceByKeyLocally
scala> var resultRdd1 = kvrdd1.reduceByKey
reduceByKey reduceByKeyLocally
scala> var resultRdd1 = kvrdd1.reduceByKey(_+_)
resultRdd1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:30
scala> resultRdd1.count
res6: Long = 1084
scala> resultRdd1.take(100)
res7: Array[(String, Int)] = Array((Because,1), (-reconfig,2), (guide,4), (under-replicated,1), (blocks,5), (maintained,1), (responsibility,1), (filled,1), (order,5), ([key-value,1), (prematurely,1), (cluster:,1), (type,1), (behind,1), (However,,1), (competing,1), (been,2), (begins,1), (up-to-date,3), (Permissions,3), (browse,1), (List:,1), (improved,1), (Balancer,2), (fine.,1), (over,1), (dfs.hosts,,2), (any,7), (connect,1), (select,2), (version,7), (disks.,1), (file,33), (documentation,,1), (file.,7), (performs,2), (million,2), (RAM,1), (are,27), ((data,1), (supported.,1), (consists,1), (existed,1), (brief,2), (overwrites,1), (safely,1), (Guide:,1), (Safemode,6), (Only,1), (Currently,1), (first-time,1), (dfs.namenode.name.dir,1), (thus,2), (salient,1), (query,1), (page).,1), (status,5...
第五步:将结果保持到HDFS文件之中
scala> resultRdd1.saveAsTextFile("hdfs:///output/wordcount1")

localhost:tmp jonsonli$ hadoop fs -ls /output/wordcount1
17/05/13 17:49:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
-rw-r--r-- 1 jonsonli supergroup 0 2017-05-13 17:47 /output/wordcount1/_SUCCESS
-rw-r--r-- 1 jonsonli supergroup 6562 2017-05-13 17:47 /output/wordcount1/part-00000
-rw-r--r-- 1 jonsonli supergroup 6946 2017-05-13 17:47 /output/wordcount1/part-00001


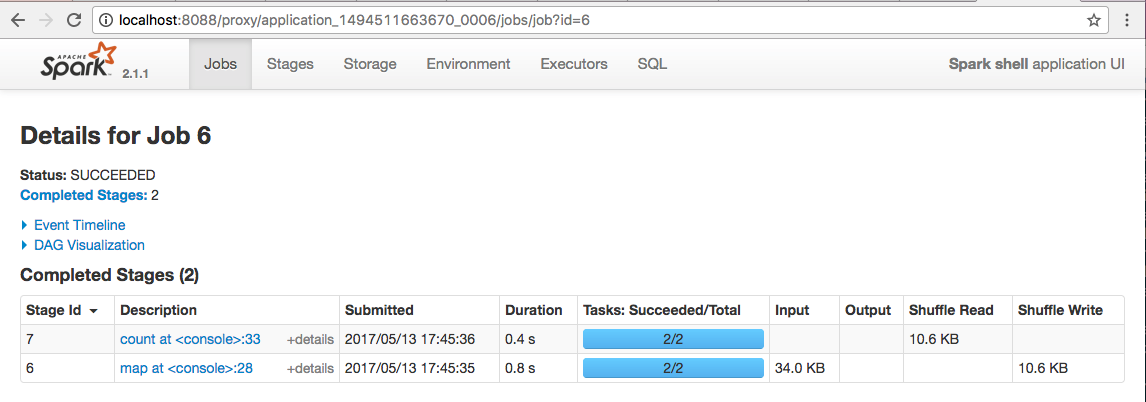

【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell的更多相关文章
- Spark集群搭建【Spark+Hadoop+Scala+Zookeeper】
1.安装Linux 需要:3台CentOS7虚拟机 IP:192.168.245.130,192.168.245.131,192.168.245.132(类似,尽量保持连续,方便记忆) 注意: 3台虚 ...
- Standalone集群搭建和Spark应用监控
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6815920501530034696/ 承接上一篇文档<Spark词频前十的统计练习> Spark on ...
- hadoop 集群搭建 配置 spark yarn 对效率的提升永无止境
[手动验证:任意2个节点间是否实现 双向 ssh免密登录] 弄懂通信原理和集群的容错性 任意2个节点间实现双向 ssh免密登录,默认在~目录下 [实现上步后,在其中任一节点安装\配置hadoop后,可 ...
- hadoop 集群搭建 配置 spark yarn 对效率的提升永无止境 Hadoop Volume 配置
[手动验证:任意2个节点间是否实现 双向 ssh免密登录] 弄懂通信原理和集群的容错性 任意2个节点间实现双向 ssh免密登录,默认在~目录下 [实现上步后,在其中任一节点安装\配置hadoop后,可 ...
- Hadoop框架:单服务下伪分布式集群搭建
本文源码:GitHub·点这里 || GitEE·点这里 一.基础环境 1.环境版本 环境:centos7 hadoop版本:2.7.2 jdk版本:1.8 2.Hadoop目录结构 bin目录:存放 ...
- ELK 之一:ElasticSearch 基础和集群搭建
一:需求及基础: 场景: 1.开发人员不能登录线上服务器查看详细日志 2.各个系统都有日志,日志数据分散难以查找 3.日志数据量大,查询速度慢,或者数据不够实时 4.一个调用会涉及到多个系统,难以在这 ...
- 集群搭建之Spark配置要点解析
注意点: 安装Spark前先要配置好Scala运行环境. Spark和Scala需要在各个机器上配置. 环境变量配置 在~/.bashrc中添加如下的配置信息. #scala conf export ...
- spark学习(1)--ubuntu14.04集群搭建、配置(jdk)
环境:ubuntu14.04 jdk-8u161-linux-x64.tar.gz 1.文本模式桌面模式切换 ctrl+alt+F6 切换到文本模式 ctrl + alt +F7 /输入命令start ...
- 【实践】Matlab2016a的mdce集群搭建
Matlab R2016a的mdce集群搭建 1.解压文件Matlab_R2016b_win64.iso. 文件下载地址:链接:https://pan.baidu.com/s/1mjJOaHa 密码: ...
随机推荐
- How to use the Custom Material node and create Metaballs 官方视频学习笔记
这个视频Youtube没有字幕着实蛋疼,本人英语很渣,几乎听不懂,里面有很多文档没讲的重要信息(文档讲的东西太少了). 不过学习过后你可以解锁好几个姿势.这个视频主要是教你做DistanceField ...
- 【整理】Java 9新特性总结
距Java 8正式发布三年多时间,Java 9 于2017年9月21日正式发布, 你可能已经听说过 Java 9 的模块系统(讨论的最多的),但是这个新版本还有许多其它的更新. 这里我整理了Java ...
- 流畅的Python读书笔记(二)
2.1 可变序列与不可变序列 可变序列 list. bytearray. array.array. collections.deque 和 memoryview. 不可变序列 tuple. str 和 ...
- 通过Obfuscated ssh避免时不时ssh连接不畅的问题【转】
众所周知的原因,为了能流畅的使用google.使用某些“不存在”的网站,我们一般都是需要通过某些不方便光明正大说明使用用途的技术.比如通过ssh tunnel,这是最简单的,也是用得最多的. 不过,这 ...
- (转)JavaWeb学习之Servlet(三)----Servlet的映射匹配问题、线程安全问题
[声明] 欢迎转载,但请保留文章原始出处→_→ 文章来源:http://www.cnblogs.com/smyhvae/p/4140529.html 一.Servlet映射匹配问题: 在第一篇文章中的 ...
- BZOJ4855 : [Jsoi2016]轻重路径
首先用树状数组维护dfs序来快速支持一个点子树大小的询问. 每次删掉一个叶子时,从根开始往叶子走,显然只有$2size[x]\leq size[father]$的点的父亲才有可能换重儿子. 从根开始往 ...
- win7生成ssh key配置到gitlab
测试服务上使用ip访问gitlab,比如http://192.168.0.2/,创建用户并登陆后创建一个项目,比如git@gitlab.demo.com:demo/helloworld.git 如果想 ...
- MySQL(四)
分组 按照字段分组,表示此字段相同的数据会被放到一个组中 分组后,只能查询出相同的数据列,对于有差异的数据列无法出现在结果集中 可以对分组后的数据进行统计,做聚合运算 语法: select 列1,列2 ...
- python网络编程(三)
udp网络通信过程 udp应用:echo服务器 参考代码 #coding=utf-8 from socket import * #1. 创建套接字 udpSocket = socket(AF_INET ...
- python网络编程(一)
socket简介 1.本地的进程间通信(IPC)有很多种方式,例如 队列 同步(互斥锁.条件变量等) 以上通信方式都是在一台机器上不同进程之间的通信方式,那么问题来了 网络中进程之间如何通信? 2. ...