(六) 6.3 Neurons Networks Gradient Checking
BP算法很难调试,一般情况下会隐隐存在一些小问题,比如(off-by-one error),即只有部分层的权重得到训练,或者忘记计算bais unit,这虽然会得到一个正确的结果,但效果差于准确BP得到的结果。
有了cost function,目标是求出一组参数W,b,这里以 表示,cost function 暂且记做
表示,cost function 暂且记做 。假设
。假设 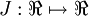 ,则
,则 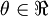 ,即一维情况下的Gradient Descent:
,即一维情况下的Gradient Descent:
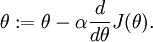
根据6.2中对单个参数单个样本的求导公式:
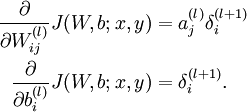
可以得到每个参数的偏导数,对所有样本累计求和,可以得到所有训练数据对参数 的偏导数记做 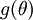 , 是靠BP算法求得的,为了验证其正确性,看下图回忆导数公式:
, 是靠BP算法求得的,为了验证其正确性,看下图回忆导数公式:
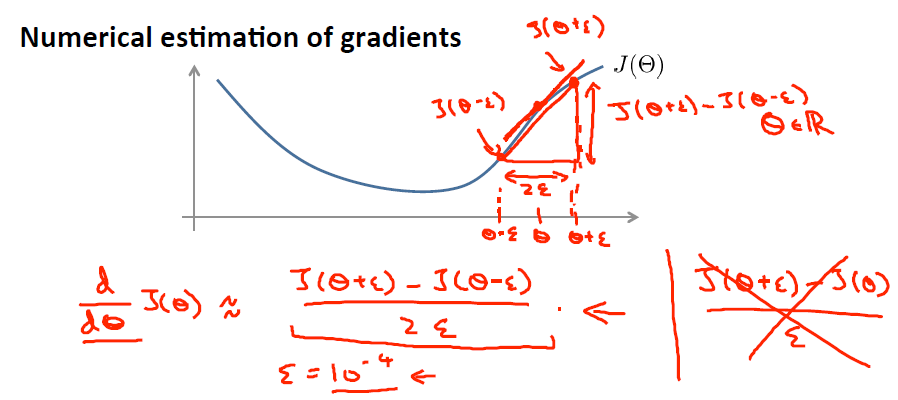
可见有: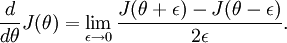 那么对于任意 值,我们都可以对等式左边的导数用:
那么对于任意 值,我们都可以对等式左边的导数用:
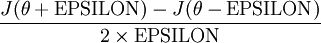 来近似。
来近似。
给定一个被认为能计算 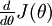 的函数,可以用下面的数值检验公式
的函数,可以用下面的数值检验公式
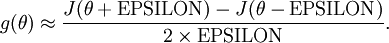
应用时,通常把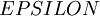 设置为一个很小的常量,比如在
设置为一个很小的常量,比如在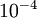 数量级,最好不要太小了,会造成数值的舍入误差。上式两端值的接近程度取决于
数量级,最好不要太小了,会造成数值的舍入误差。上式两端值的接近程度取决于 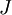 的具体形式。假定
的具体形式。假定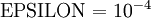 的情况下,上式左右两端至少有4位有效数字是一样的(通常会更多)。
的情况下,上式左右两端至少有4位有效数字是一样的(通常会更多)。
当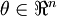 是一个n维向量而不是实数时,且
是一个n维向量而不是实数时,且 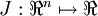 ,在 Neorons Network 中,J(W,b)可以想象为 W,b 组合扩展而成的一个长向量 ,现在又一个计算
,在 Neorons Network 中,J(W,b)可以想象为 W,b 组合扩展而成的一个长向量 ,现在又一个计算 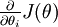 的函数
的函数 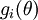 ,如何检验能否输出到正确结果呢,用的取值来检验,对于向量的偏导数:
,如何检验能否输出到正确结果呢,用的取值来检验,对于向量的偏导数:

根据上图,对 i 求导时,只需要在向量的第i维上进行加减操作,然后求值即可,定义 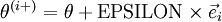 ,其中
,其中
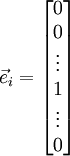
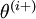 和 几乎相同,除了第
和 几乎相同,除了第  行元素增加了 ,类似地,
行元素增加了 ,类似地,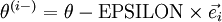 得到的第 行减小了 ,然后求导并与比较:
得到的第 行减小了 ,然后求导并与比较:
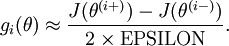
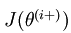 中的参数对应的是参数向量中一个分量的细微变化,损失函数J 在不同情况下会有不同的值(比如三层NN 或者 三层autoencoder(需加上稀疏项)),上式中左边为BP算法的结果,右边为真正的梯度,只要两者很接近,说明BP算法是在正确工作,对于梯度下降中的参数是按照如下方式进行更新的:
中的参数对应的是参数向量中一个分量的细微变化,损失函数J 在不同情况下会有不同的值(比如三层NN 或者 三层autoencoder(需加上稀疏项)),上式中左边为BP算法的结果,右边为真正的梯度,只要两者很接近,说明BP算法是在正确工作,对于梯度下降中的参数是按照如下方式进行更新的:
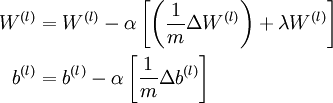
即有 分别为:
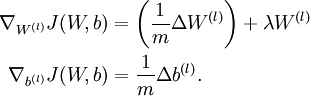
最后只需总体损失函数J(W,b)的偏导数与上述 的值比较即可。
除了梯度下降外,其他的常见的优化算法:1) 自适应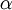 的步长,2) BFGS L-BFGS,3) SGD,4) 共轭梯度算法,以后涉及到再看。
的步长,2) BFGS L-BFGS,3) SGD,4) 共轭梯度算法,以后涉及到再看。
(六) 6.3 Neurons Networks Gradient Checking的更多相关文章
- CS229 6.3 Neurons Networks Gradient Checking
BP算法很难调试,一般情况下会隐隐存在一些小问题,比如(off-by-one error),即只有部分层的权重得到训练,或者忘记计算bais unit,这虽然会得到一个正确的结果,但效果差于准确BP得 ...
- (六) 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
- (六) 6.2 Neurons Networks Backpropagation Algorithm
今天得主题是BP算法.大规模的神经网络可以使用batch gradient descent算法求解,也可以使用 stochastic gradient descent 算法,求解的关键问题在于求得每层 ...
- (六)6.10 Neurons Networks implements of softmax regression
softmax可以看做只有输入和输出的Neurons Networks,如下图: 其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵. 对损失函数J(θ)的形式有: 算法 ...
- (六)6.5 Neurons Networks Implements of Sparse Autoencoder
一大波matlab代码正在靠近.- -! sparse autoencoder的一个实例练习,这个例子所要实现的内容大概如下:从给定的很多张自然图片中截取出大小为8*8的小patches图片共1000 ...
- (六)6.16 Neurons Networks linear decoders and its implements
Sparse AutoEncoder是一个三层结构的网络,分别为输入输出与隐层,前边自编码器的描述可知,神经网络中的神经元都采用相同的激励函数,Linear Decoders 修改了自编码器的定义,对 ...
- (六)6.13 Neurons Networks Implements of stack autoencoder
对于加深网络层数带来的问题,(gradient diffuse 局部最优等)可以使用逐层预训练(pre-training)的方法来避免 Stack-Autoencoder是一种逐层贪婪(Greedy ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Gradient Checking)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Gradient Checking Welcome to the final assignment for this week! In ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第一周(Practical aspects of Deep Learning) —— 4.Programming assignments:Gradient Checking
Gradient Checking Welcome to this week's third programming assignment! You will be implementing grad ...
随机推荐
- Android屏幕适应详解(二)
android应用自适应多分辨率的解决方法 1. 首先是建立多个layout文件夹(drawable也一样). 在res目录下建立多个layout文件夹,文件夹名称为layout-800x480等. ...
- iOS多线程的初步研究(五)-- 如何让NSURLConnection在子线程中运行
可以有两个办法让NSURLConnection在子线程中运行,即将NSURLConnection加入到run loop或者NSOperationQueue中去运行. 前面提到可以将NSTimer手动加 ...
- Ajax的进阶学习(一)
在Ajax课程中,我们了解了最基本的异步处理方式.本章,我们将了解一下Ajax的一些全局请求事件.跨域处理和其他一些问题. 加载请求 在Ajax异步发送请求时,遇到网速较慢的情况,就会出现请求时间较长 ...
- ActiveMQ和Tomcat的整合应用(转)
转自:http://topmanopensource.iteye.com/blog/1111321 ActiveMQ和Tomcat的整合应用 博客分类: ActiveMQ学习和研究 在Active ...
- Java:集合框架的工具类
集合框架的工具类 Arrays:里面都是静态方法,直接用来对各种集合进行操作的公有方法. Collections:里面都是静态方法,直接用来对各种集合进行操作的公有方法. 包括: 1.asList将数 ...
- jboss内存查看管理 .
jboss内存查看管理 标签: jbossjavagenerationjvmclassjar 2009-04-09 14:47 4248人阅读 评论(2) 收藏 举报 本文章已收录于: // ' ...
- centos 安装jdk
不要使用yum 安装openjdk,他妈的就是一坑货 首先到官网下载jdk,http://www.oracle.com/technetwork/java/javase/downloads/jdk7-d ...
- Deeplearning原文作者Hinton代码注解
[z]Deeplearning原文作者Hinton代码注解 跑Hinton最初代码时看到这篇注释文章,很少细心,待研究... 原文地址:>http://www.cnblogs.com/BeDPS ...
- slot signal机制
有一个比较 经典的实现:http://sigslot.sourceforge.net/很精简的 signal slot的实现,跨平台.webrtc项目在用,我在自己项目里也用了.这个源码有2000多行 ...
- Grunt :任务自动管理工具
来自<JavaScript 标准参考教程(alpha)>,by 阮一峰 在Javascript的开发过程中,经常会遇到一些重复性的任务,比如合并文件.压缩代码.检查语法错误.将Sass代码 ...