Hadoop2.0之YARN组件
官方文档:https://hadoop.apache.org/docs/stable/,目前官方已经是3.x,但yarn机制没有太大变化
一、简介
在Hadoop1.0中,没有yarn,所有的任务调度和资源管理都是MapReduce自己来做,所以在Hadoop1.0中,最核心的节点是JobTracker。在整个MapReduce集群中,JobTracker的性能基本决定了整个集群的性能。经过试验,发现在Hadoop1.0中,JobTracker所能管理的节点数量最多不要超过4000,一旦超过4000个节点,则整个集群的性能会成倍下降。
在Hadoop2.0中,为了解决性能下降的问题,引入了yarn来进行管理,从Hadoop2.0开始,MapReduce变成了一个纯粹的计算框架,不再负责管理
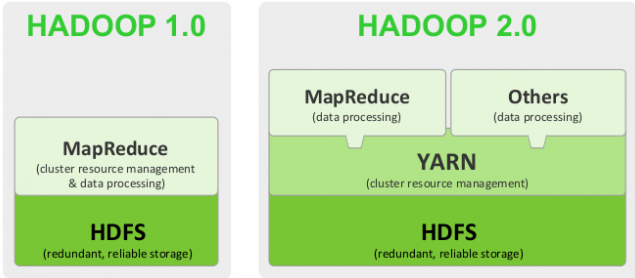
Yarn组件包括:
1)ResourceManager-资源管理:负责资源的监控和分配
①ApplicationsManager:负责为任务分配资源
②Schedular:负责将任务以及资源发给ApplicationMaster
2)ApplicationMaster:负责任务调度和监控,并不是一个主进程,在启动Yarn的时候,不会单独占用一个节点
3)NodeManager:任务执行:功能和原来的TaskTracker一致
二、MR V1.0与V2.0比较
1、v1.0 MR图解说明
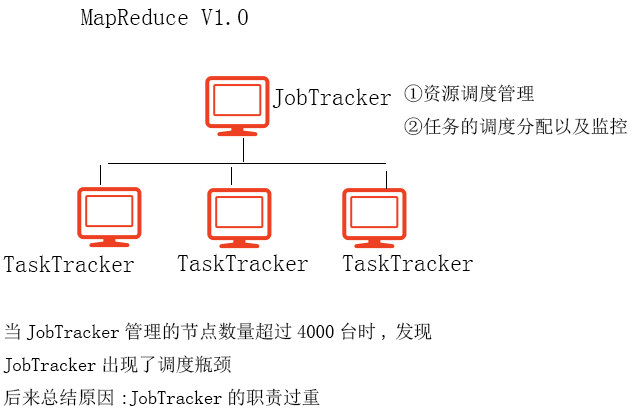
2、v2.0 MR图解说明

三、Yarn体系架构图
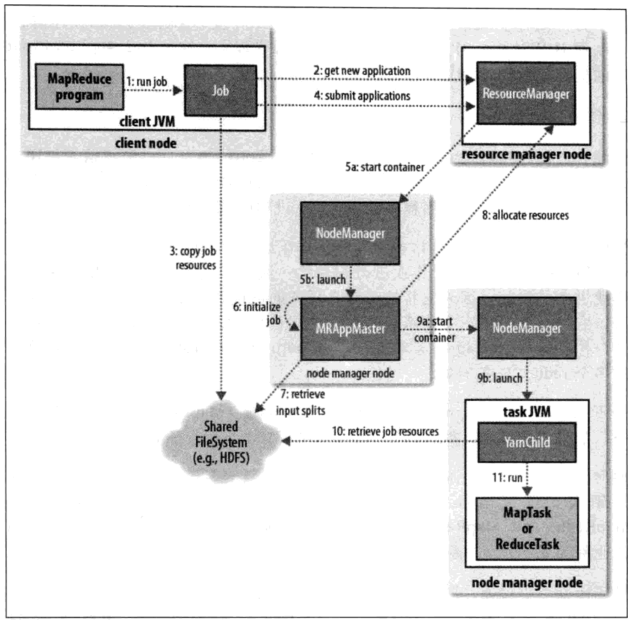
执行流程:
① JobClient执行run job阶段,检测各种job运行环境参数
② 向ResourceManager申请job id
③ 将Job的运算资源,上传到HDFS
④ submit job
⑤
a:start container,启动容器,这一步的容器的资源封装,限定的是AppMaster进程
b:根据容器的资源描述情况,启动AppMaster进程(用于负责对应Job的任务分配和监控)
⑥~⑦:初始化job,统计出当前job的MapTask数量和ReduceTask数量
⑧:AppMaster向RM申请资源,RM收到请求后,会为对应的Job创建一个资源队列
⑨
a:在具体的NM上启动容器
b:根据容器启动对应的工作进程
⑩ 获取job的运算资源
⑪ 在进程中运行MapTask或ReduceTask
四、Yarn执行流程

①将Job任务提交到RM
②在RM中,子组件ResourceManager会为提交的job任务分配执行所需要的资源,资源主要包含这个任务执行所需要的内存、cpu核数,将分配的资源封装到一个Container对象中。如果不指定,则默认每一个任务分配1G内存及1核CPU
③ApplicationsManager将Container及Job任务交给Schedular,然后Schedular负责将Container和Job交给ApplicationMaster
④ApplicationMaster接收到任务后,将Job拆分成多个MapTask以及ReduceTask,将MapTask以及Reduce Task分发到NodeManager上执行。
⑤NodeManager会启动JVM子进程执行对应的任务,会为每一个MapTask或ReduceTask都启动一个JVM子进程
⑥NodeManager会向ApplicationMaster汇报任务的执行情况,并且向ApplicationsManager汇报资源使用情况
⑦如果执行成功,则NodeManager向ApplicationMaster返回任务成功的信号,并且向ApplicationsManager发送信号回收资源
⑧如果执行失败,则NodeManager向ApplicationMaster返回任务失败的信号,并且依然会向ApplicationManager发送信号回收资源;ApplicationMaster收到失败信号,会重新给这个任务来申请资源,然后试图重新分配这个任务
Hadoop2.0之YARN组件的更多相关文章
- Hadoop2.0之YARN
YARN(Yet Another Resource Negotiator)是Hadoop2.0集群中负责资源管理和调度以及监控运行在它上面的各种应用,是hadoop2.0中的核心,它类似于一个分布式操 ...
- 基于Hadoop2.0、YARN技术的大数据高阶应用实战(Hadoop2.0\YARN\Ma
Hadoop的前景 随着云计算.大数据迅速发展,亟需用hadoop解决大数据量高并发访问的瓶颈.谷歌.淘宝.百度.京东等底层都应用hadoop.越来越多的企 业急需引入hadoop技术人才.由于掌握H ...
- Cloudera Hadoop 5& Hadoop高阶管理及调优课程(CDH5,Hadoop2.0,HA,安全,管理,调优)
1.课程环境 本课程涉及的技术产品及相关版本: 技术 版本 Linux CentOS 6.5 Java 1.7 Hadoop2.0 2.6.0 Hadoop1.0 1.2.1 Zookeeper 3. ...
- Hadoop2.0(HDFS2)以及YARN设计的亮点
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResouceManager负责对各个Node ...
- Hadoop2.0构成之YARN
YARN产生背景 Hadoop1.x中的MapReduce构成图如下: 在Hadoop1.x中MapReduce是Master/Slave结构,在集群中的表现形式为:1个JobTracker带多个Ta ...
- hadoop2.0 和1.0的区别
1. Hadoop 1.0中的资源管理方案Hadoop 1.0指的是版本为Apache Hadoop 0.20.x.1.x或者CDH3系列的Hadoop,内核主要由HDFS和MapReduce两个系统 ...
- 【原创 Hadoop&Spark 动手实践 4】Hadoop2.7.3 YARN原理与动手实践
简介 Apache Hadoop 2.0 包含 YARN,它将资源管理和处理组件分开.基于 YARN 的架构不受 MapReduce 约束.本文将介绍 YARN,以及它相对于 Hadoop 中以前的分 ...
- Hadoop2.0.0+CDH4.5.0集群配置
Hadoop 2.0.0-cdh4.5.0安装:http://blog.csdn.net/u010967382/article/details/18402217 CDH版本下载:http://arch ...
- Hadoop1.0 与Hadoop2.0
Hadoop1.0的局限-MapReduce •扩展性 –集群最大节点数–4000 –最大并发任务数–40000 (当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增 ...
随机推荐
- Docker最全教程——从理论到实战(十五)
前言 Java是一门面向对象的优秀编程语言,市场占有率极高,但是在容器化实践过程中,发现官方支持并不友好,同时与其他编程语言的基础镜像相比(具体见各语言镜像比较),确实是非常臃肿. 本篇仅作探索,希望 ...
- linux--nginx学习
nginx 1.nginx安装编译 1.yum install nginx(自动解决依赖) 2.源代码编译安装(优秀,自由选择软件版本,自定义第三方功能比如开启https) 3.rpm手动安装(垃圾) ...
- yarn 不要一起用 npm
yarn 不要一起用 npm 如果一起用,看下lock 的版本一样不,不一样可能会出现问题
- 假期学习【五】RDD编程实验四
今天完成了实验四的第二问和第三问 第二题 对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C.下面是输入文件和输出文件的一个样 ...
- Codeforces 540A - Combination Lock
Scrooge McDuck keeps his most treasured savings in a home safe with a combination lock. Each time he ...
- django Warning: (3135, "'NO_ZERO_DATE', 'NO_ZERO_IN_DATE' and 'ERROR_FOR_DIVISION_BY_ZERO' sql modes
django连接数据库配置设置如下 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'test2', ...
- rm -rf
inux反选删除文件 最简单的方法是 # shopt -s extglob (打开extglob模式) # rm -fr !(file1) 如果是多个要排除的,可以这样: # rm -rf ...
- 【vue】 vue跳转页面:router-link/this.$router.push()
1.通过标签<router-link> <router-link to='A'>跳转到A页面</router-link> 2.通过方法 this.$router.p ...
- 4817 [Sdoi2017]树点涂色
题目描述 Bob 有一棵 n 个点的有根树,其中 1 号点是根节点.Bob 在每个点上涂了颜色,并且每个点上的颜色不同. 定义一条路径的权值是:这条路径上的点(包括起点和终点)共有多少种不同的颜色. ...
- python pymysql 基本使用
from pymysql import * # 1.创建连接数据库 conn = connect(host="localhost", port=3306, user="r ...