PYTHON之爬虫学习(一)基础
关于python爬虫,大家都很熟悉,那么我就不多说,开始做了。
首先,python爬虫先安装python库,主要是requests库,在windows中cmd中输入,pip install requests ,之后会自动安装。
之后再python IDLE 中输入import requests 无报错说明安装正确。
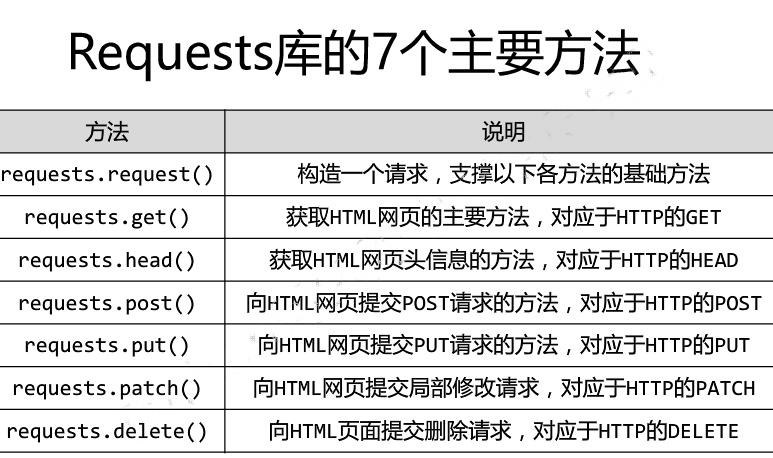
下面试试爬取百度页面:
最简单的方式
import requests
r=requests.get("http://www.baidu.com")
print(r.text)
返回的结果:
<!DOCTYPE html> <!--STATUS OK--><html> <head>
<meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge> <meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css>
<title>ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é</title></head> <body link=#0000cc>
<div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form>
<div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div>
<form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1>
<input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8>
<input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1>
<input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus>
</span><span class="bg s_btn_wr"><input type=submit id=su value=ç¾åº¦ä¸ä¸ class="bg s_btn"></span> </form>
</div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ°é»</a>
<a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a>
<a href=http://map.baidu.com name=tj_trmap class=mnav>å°å¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§é¢</a>
<a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a>
<noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç»å½</a>
</noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">ç»å½</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ´å¤äº§å</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å ³äºç¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç¨ç¾åº¦åå¿ è¯»</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æè§åé¦</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
返回页面的所有代码
PYTHON之爬虫学习(一)基础的更多相关文章
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
- Python网络爬虫学习手记(1)——爬虫基础
1.爬虫基本概念 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.--------百度百科 简单的说,爬 ...
- python之爬虫学习记录与心得
之前在寒假的时候,学习了python基础.在慕课网上看的python入门:http://www.imooc.com/learn/177 python进阶:http://www.imooc.com/le ...
- python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库.bs4库,它可用于解析HTML/XML,并将所有文件.字符串转换为'utf-8'编码.HTML/XML文档是与“标签树一一对应的.具体地说, ...
- python网络爬虫学习笔记(一)Request库
一.Requests库的基本说明 引入Rquests库的代码如下 import requests 库中支持REQUEST, GET, HEAD, POST, PUT, PATCH, DELETE共7个 ...
- Python scrapy爬虫学习笔记01
1.scrapy 新建项目 scrapy startproject 项目名称 2.spiders编写(以爬取163北京新闻为例) 此例中用到了scrapy的Itemloader机制,itemloade ...
- python网络爬虫学习
网络爬虫 Requests官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html Beautiful So ...
- python beautifulsoup爬虫学习
BeautifulSoup(page_html, "lxml").select(),这里可以通过浏览器开发者模式选择copy selector,并且并不需要完整路径. github ...
随机推荐
- LCD实验学习笔记(八):中断
s3c2440有60个中断源(其中15个为子中断源). 31个32位的通用寄存器,6个程序状态寄存器.有6种工作模式(系统/用户模式,快中断模式,管理模式,数据访问中止模式,中断模式,未定指令中止模式 ...
- python写一段脚本代码自动完成输入(目录下的所有)文件的数据替换(修改数据和替换数据都是输入的)【转】
转自:http://blog.csdn.net/lixiaojie1012/article/details/23628129 初次尝试python语言,感觉用着真舒服,简单明了,库函数一调用就OK了 ...
- 用intellj 建一个spring mvc 项目DEMO
spring的起初可能经常碰壁,因为网上的资料都是混乱的xml堆成的,混乱难以理解,我这个也是,阿哈哈哈哈! 新建一个Maven->create from archetype->org.j ...
- 动态计算文本的CGSize
// 计算文本的size -(CGSize)sizeWithText:(NSString *)text maxSize:(CGSize)maxSize fontSize:(CGFloat)fontSi ...
- 解决 :java -version出现错误:“could not open `C:\Program Files\Java\jre7\lib\amd64\jvm.cfg”
cmd 下java -version出现错误:“could not open `C:\Program Files\Java\jre7\lib\amd64\jvm.cfg”,出现这种错误可能是由于先前有 ...
- python初学-元组、集合
元组: 元组基本和列表一样,区别是 元组的值一旦创建 就不能改变了 tup1=(1,2,3,4,5) print(tup1[2]) ---------------------------------- ...
- C++智能指针: auto_ptr, shared_ptr, unique_ptr, weak_ptr
本文参考C++智能指针简单剖析 内存泄露 我们知道一个对象(变量)的生命周期结束的时候, 会自动释放掉其占用的内存(例如局部变量在包含它的第一个括号结束的时候自动释放掉内存) int main () ...
- 【python】日志系统
来源: http://blog.csdn.net/wykgf/article/details/11576721 http://www.jb51.net/article/42626.htm http:/ ...
- 《java并发编程实战》读书笔记5--任务执行, Executor框架
第6章 任务执行 6.1 在线程中执行任务 第一步要找出清晰的任务边界.大多数服务器应用程序都提供了一种自然的任务边界选择方式:以独立的请求为边界. -6.6.1 串行地执行任务 最简单的任务调度策略 ...
- SQl server 2008 附加数据库失败,错误:5120
通过附加功能添加现成的数据库是非常方便的,然而有时会出现附加数据库失败.那么,我们该如何解决此问题? 有两种解决方法 [第一种方法] 第一步:找到要添加数据库的.mdf文件,点击右键,选择属性. 第二 ...