[会装]Spark standalone 模式的安装
1. 简介
以standalone模式安装spark集群bin运行demo。
2.环境和介质准备
2.1 下载spark介质,根据现有hadoop的版本选择下载,我目前的环境中的hadoop版本是2.6,所以下载spark-2.0.0-bin-hadoop2.6.tgz
当然你也可以下载源码自行根据hadoop版本进行编译,这里不再赘述。
地址:http://ftp.cuhk.edu.hk/pub/packages/apache.org/spark/spark-2.0.0/

2.2 环境准备
| 主机名称 | 进程名称 |
| xufeng-1 | work |
| xufeng-2 | work |
| xufeng-3 | master |
3. 安装步骤:
【以下步骤不单独说明所有主机都需要执行】
步骤 1:将介质包拷贝到服务器上,并将配置文件和bin文件分开。

可以看到spark目录使用了软连接,配置文件被单独放在了spark-config中,这样做的目的是便于升级。
步骤 2:设定环境变量.
在~/.bash_profile文件中增加如下信息:
#spark
export SPARK_HOME=/opt/hadoop/spark
export SPARK_CONF_DIR=/opt/hadoop/spark-config PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
步骤 3:配置slaves:
打开spark-config目录下的slaves文件将work部署的主机名信息写入:
# A Spark Worker will be started on each of the machines listed below.
xufeng-
xufeng-
步骤 4:配置javahome
打开spark-config目录下的spark-env.sh文件,设定如下信息(根据自己的java路径信息):
# - SPARK_NICENESS The scheduling priority for daemons. (Default: )
export JAVA_HOME=/opt/hadoop/java/jdk1..0_79
4. 启动集群
4.1 登录上master节点,也就是xufeng-3节点,进入spark/sbin目录,执行
./start-all.sh ------- spark的脚本和hadoop的脚本是同名的,如果我们直接执行start-all.sh,那么很有可能执行的是hadoop的脚本,所以这里进入spark安装目录,具体调用他的脚本
4.2 检查Master 的 webUI
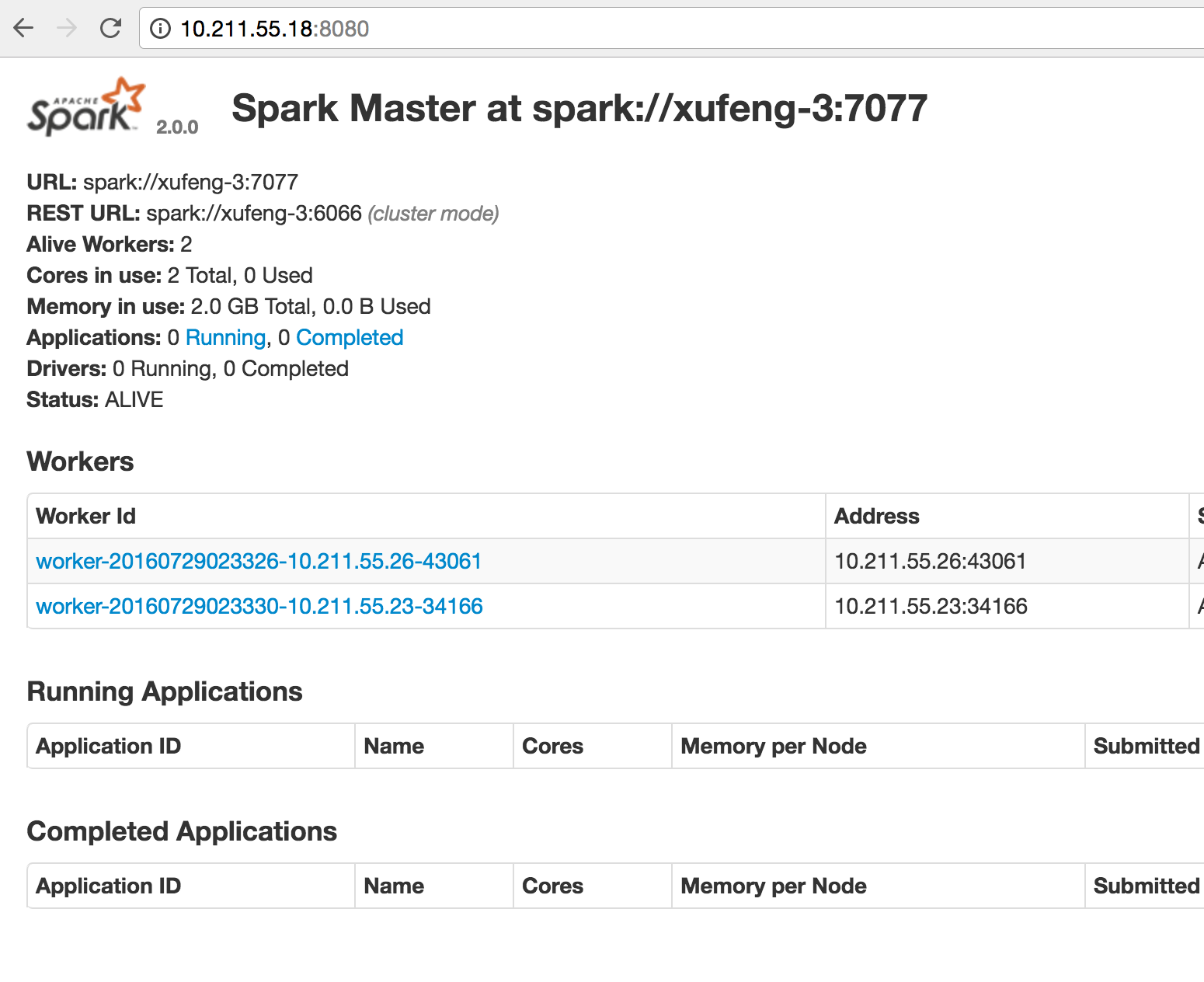
以上Mater和worker在standalone模式中就是一个资源管理器系统,分配app的资源使用或者我们可以直接说他是一个【Cluster Manager】。
在其他模式中,如在YARN模式中资源的分配就交给YARN去处理,YARN集群就是【Cluster Manager】角色了。
5. 验证
进入spark-shell 简单的去执行一个任务用于验证
如果不知道后续参数,那么这个shell将会在本地执行,在Mater页面上是看不到信息的。
spark-shell --master spark://xufeng-3:7077 --executor-memory 500M

1.创建一个rdd
scala> val rdd = sc.parallelize(List(,,,,,))
2.执行两次count和一次collect操作(action操作)
scala> rdd.count()
res0: Long = scala> rdd.count()
res1: Long = scala> rdd.collect
res2: Array[Int] = Array(, , , , , )
查看页面监控:

以上,standalone模式安装完毕。
[会装]Spark standalone 模式的安装的更多相关文章
- Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
前期博客 Spark运行模式概述 Spark standalone简介与运行wordcount(master.slave1和slave2) 开篇要明白 (1)spark-env.sh 是环境变量配 ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- 【原】Spark Standalone模式
Spark Standalone模式 安装Spark Standalone集群 手动启动集群 集群创建脚本 提交应用到集群 创建Spark应用 资源调度及分配 监控与日志 与Hadoop共存 配置网络 ...
- Spark Standalone模式应用程序开发
作者:过往记忆 | 新浪微博:左手牵右手TEL | 能够转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明博客地址:http://www.iteblog.com/文章标题:<Spar ...
- 关于spark standalone模式下的executor问题
1.spark standalone模式下,worker与executor是一一对应的. 2.如果想要多个worker,那么需要修改spark-env的SPARK_WORKER_INSTANCES为2 ...
- Spark Standalone模式HA环境搭建
Spark Standalone模式常见的HA部署方式有两种:基于文件系统的HA和基于ZK的HA 本篇只介绍基于ZK的HA环境搭建: $SPARK_HOME/conf/spark-env.sh 添加S ...
- spark standalone模式单节点启动多个executor
以前为了在一台机器上启动多个executor都是通过instance多个worker来实现的,因为standalone模式默认在一台worker上启动一个executor,造成了很大的不便利,并且会造 ...
- Spark Standalone模式伪分布式环境搭建
前提:安装好jdk1.7,hadoop 安装步骤: 1.安装scala 下载地址:http://www.scala-lang.org/download/ 配置环境变量: export SCALA_HO ...
- Spark Standalone模式 高可用部署
本文使用Spark的版本为:spark-2.4.0-bin-hadoop2.7.tgz. spark的集群采用3台机器进行搭建,机器分别是server01,server02,server03. 其 ...
随机推荐
- 深入理解Delete(JavaScript)
深入理解Delete(JavaScript) Delete 众所周知是删除对象中的属性. 但如果不深入了解delete的真正使用在项目中会出现非常严重的问题 (: Following 是翻译 ka ...
- CentOS 查看系统内核和版本
1.uname 命令用于查看系统内核与系统版本等信息,格式为“uname [-a]”. [root@bigdata-senior01 ~]# uname -a Linux bigdata-senior ...
- [洛谷P3975][TJOI2015]弦论
题目大意:求一个字符串的第$k$大字串,$t$表示长得一样位置不同的字串是否算多个 题解:$SAM$,先求出每个位置可以到达多少个字串($Right$数组),然后在转移图上$DP$,若$t=1$,初始 ...
- Spring-Boot基于配置按条件装Bean
背景 同一个接口有多种实现,项目启动时按某种规则来选择性的启用其中一种实现,再具体一点,比如Controller初始化的时候,根据配置文件的指定的实现类前缀,来记载具体Service,不同Servic ...
- BZOJ4144 [AMPPZ2014]Petrol 【最短路 + 最小生成树】
题目链接 BZOJ4144 题解 这题好妙啊,,orz 假设我们在一个非加油站点,那么我们一定是从加油站过来的,我们剩余的油至少要减去这段距离 如果我们在一个非加油站点,如果我们到达不了任意加油站点, ...
- [zhuan]java发送http的get、post请求
http://www.cnblogs.com/zhuawang/archive/2012/12/08/2809380.html Http请求类 package wzh.Http; import jav ...
- HDU 5656
CA Loves GCD Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)To ...
- [ethernet]ubuntu更换网卡驱动
问题: 网络不能ping通,dmesg显示很多 [::00.0: eth0: link up [::00.0: eth0: link up [::00.0: eth0: link up [::00.0 ...
- [Coding Practice] Maximum number of zeros in NxN matrix
Question: Input is a NxN matrix which contains only 0′s and 1′s. The condition is no 1 will occur in ...
- 可能是国内最火的开源项目 —— C/C++ 篇
程序员们,在北上广你还能买房吗? >>> 推荐阅读: 可能是最火的开源项目 -- Java 篇 可能是国内最火的开源项目 -- PHP 篇 可能是国内最火的开源项目 -- Pyt ...