Python Map 并行
Map是一个酷酷的小东西,也是在Python代码轻松引入并行的关键。对此不熟悉的人会认为map是从函数式语言(如Lisp)借鉴来的东西。map是一个函数 - 将另一个函数映射到一个序列上。例如:
urls = ['http://www.yahoo.com', 'http://www.reddit.com']
results = map(urllib2.urlopen, urls)
这段代码在传入序列的每个元素上应用方法urlopen,并将所有结果存入一个列表中。大致与下面这段代码的逻辑相当:
results = []
for url in urls:
results.append(urllib2.urlopen(url))
Map会为我们处理在序列上的迭代,应用函数,最后将结果存入一个方便使用的列表。
这为什么重要呢?因为利用恰当的库,map让并行处理成为小事一桩!
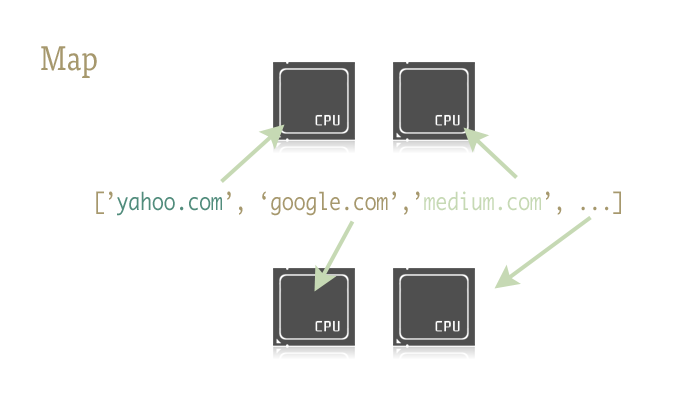
Python标准库中multiprocessing模块,以及极少人知但同样出色的子模块multiprocessing.dummy,提供了map函数的并行版本。
题外话:这是啥?你从未听说过这名为dummy的mulprocessing模块的线程克隆版本?我也是最近才知道的。在multiprocessing文档页中仅有一句提到这个子模块,而这句话基本可以归结为“哦,是的,存在这样一个东西”。完全低估了这个模块的价值!
Dummy是multiprocessing模块的精确克隆,唯一的区别是:multiprocessing基于进程工作,而dummy模块使用线程(也就带来了常见的Python限制)。因此,任何东西可套用到一个模块,也就可以套用到另一个模块。在两个模块之间来回切换也就相当容易,当你不太确定一些框架调用是IO密集型还是CPU密集型时,想做探索性质的编程,这一点会让你觉得非常赞!
开始
为了访问map函数的并行版本,首先需要导入包含它的模块:
# 以下两行引入其一即可
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
并实例化池对象:
# 译注:这里其实是以dummy模块为例
pool = ThreadPool()
这一句代码处理了example2.py中7行的build_worker_pool函数完成的所有事情。如名所示,这句代码会创建一组可用的工作者,启动它们来准备工作,并将它们存入变量中,方便访问。
pool对象可以有若干参数,但目前,只需关注第一个:进程/线程数量。这个参数用于设置池中的工作者数目。如果留空,默认为机器的CPU核数。
一般来说,如果为CPU密集型任务使用进程池(multiprocessing pool),更多的核等于更快的速度(但有一些注意事项)。然而,当使用线程池(threading)处理网络密集型任务时,情况就很不一样了,因此最好试验一下池的最佳大小。
pool = ThreadPool(4) # 将池的大小设置为4
如果运行了过多的线程,就会浪费时间在线程切换上,而不是做有用的事情,所以可以把玩把玩直到找到最适合任务的线程数量。
现在池对象创建好了,简单的并行也是弹指之间的事情了,那来重写example2.py吧。
import urllib2
from multiprocessing.dummy import Pool as ThreadPool urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
# 等等...
] # 创建一个工作者线程池
pool = ThreadPool(4)
# 在各个线程中打开url,并返回结果
results = pool.map(urllib2.urlopen, urls)
#close the pool and wait for the work to finish
# 关闭线程池,等待工作结束
pool.close()
pool.join()
看看!真正做事情的代码仅有4行,其中3行只是简单的辅助功能。map调用轻松搞定了之前示例40行代码做的事情!觉得好玩,我对两种方式进行了时间测量,并使用了不同的池大小。
# 译注:我觉得与串行处理方式对比意义不大,应该和队列的方式进行性能对比
results = []
for url in urls:
result = urllib2.urlopen(url)
results.append(result) # # ------- 对比 ------- # # # ------- 池的大小为4 ------- #
pool = ThreadPool(4)
results = pool.map(urllib2.urlopen, urls) # # ------- 池的大小为8 ------- # pool = ThreadPool(8)
results = pool.map(urllib2.urlopen, urls) # # ------- 池的大小为13 ------- # pool = ThreadPool(13)
results = pool.map(urllib2.urlopen, urls)
结果:
单线程: 14.4 秒
池大小为4时:3.1 秒
池大小为8时:1.4 秒
池大小为13时:1.3秒
真是呱呱叫啊!也说明了试验不同的池大小是有必要的。在我的机器上,池的大小大于9后会导致性能退化(译注:咦,结果不是显示13比8的性能要好么?)。
现实中的Example 2
为千张图片创建缩略图。
来做点CPU密集型的事情!对于我,在工作中常见的任务是操作大量的图片目录。其中一种图片转换是创建缩略图。这项工作适于并行处理。
基本的单进程设置
from multiprocessing import Pool
from PIL import Image SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs' def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f) def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path) if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY)) images = get_image_paths(folder) for image in images:
create_thumbnail(image)
示例代码中用了一些技巧,但大体上是:向程序传入一个目录,从目录中获取所有图片,然后创建缩略图,并将缩略图存放到各自的目录中。
在我的机器上,这个程序处理大约6000张图片,花费27.9秒。
如果使用一个并行的map调用来替换for循环:
from multiprocessing import Pool
from PIL import Image SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs' def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f) def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path) if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY)) images = get_image_paths(folder) pool = Pool()
pool.map(create_thumbnail, images)
pool.close()
pool.join()
5.6秒!
仅修改几行代码就能得到巨大的速度提升。这个程序的生产环境版本通过切分CPU密集型工作和IO密集型工作并分配到各自的进程和线程(通常是死锁代码的一个因素),获得更快的速度。然而,由于map性质清晰明确,无需手动管理线程,以干净、可靠、易于调试的方式混合匹配两者(译注:这里的“两者”是指什么?CPU密集型工作和IO密集型工作?),也是相当容易的。
就是这样了。(几乎)一行式并行解决方案。
转自:http://blog.xiayf.cn/2015/09/11/parallelism-in-one-line/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
Python Map 并行的更多相关文章
- 快速掌握用python写并行程序
目录 一.大数据时代的现状 二.面对挑战的方法 2.1 并行计算 2.2 改用GPU处理计算密集型程序 3.3 分布式计算 三.用python写并行程序 3.1 进程与线程 3.2 全局解释器锁GIL ...
- Python map,reduce,filter,apply
map(function, iterable, ...) map()函数接收两个参数,一个是函数,一个是可迭代的对象,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回. 基本等 ...
- python实现并行爬虫
问题背景:指定爬虫depth.线程数, python实现并行爬虫 思路: 单线程 实现爬虫类Fetcher 多线程 threading.Thread去调Fet ...
- Python map,filter,reduce函数
# -*- coding:utf-8 -*- #定义一个自己的map函数list_list = [1,2,4,8,16] def my_map(func,iterable): my_list = [] ...
- python map 常见用法
python map 常见用法2017年02月01日 19:32:41 淇怪君 阅读数:548版权声明:欢迎转载,转载请注明出处 https://blog.csdn.net/Tifficial/art ...
- python map函数(23)
截至到目前为止,其实我们已经接触了不少的python内置函数,而map函数也是其中之一,map函数是根据指定函数对指定序列做映射,在开发中使用map函数也是有效提高程序运行效率的办法之一. 一.语法定 ...
- python中并行遍历:zip和map-转
http://blog.sina.com.cn/s/blog_70e50f090101lat2.html 1.并行遍历:zip和map 内置的zip函数可以让我们使用for循环来并行使用多个序列.在基 ...
- python map 详解
python中的map函数应用于每一个可迭代的项,返回的是一个结果list.如果有其他的可迭代参数传进来,map函数则会把每一个参数都以相应的处理函数进行迭代处理.map()函数接收两个参数,一个是函 ...
- python map函数
map()函数 map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回. 例如,对于li ...
随机推荐
- CSS 优先级和特指度
1.ID 选择符 > 类选择符 > 元素选择符.特指度高的优先级高 2.行内样式 > 内嵌样式 > 链接样式 3.设定的样式 > 继承的样式 特指度的计算: 特指度能够用 ...
- C/C++心得-结构体
先说句题外话,个人认为,基本上所有的高级语言被设计出来的最终目的是降低软件开发难度,提升软件开发人员素质和团队协作能力,降低软件维护的难度.在学习语言的时候,可以从这么方面来推测各种语言语法设计的原因 ...
- Kali-linux枚举服务
枚举是一类程序,它允许用户从一个网络中收集某一类的所有相关信息.本节将介绍DNS枚举和SNMP枚举技术.DNS枚举可以收集本地所有DNS服务和相关条目.DNS枚举可以帮助用户收集目标组织的关键信息,如 ...
- 制作二维码java
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- UDP and TCP
UDP unreliable, just add de-multiplexing and error checking on data than IP. Best effort datagram(数据 ...
- Knowledge Point 20180308 拔下forEach的外衣
剖析加强for 很长一段时间对于foreach都有一种误解,那就是foreach只是普通for的包装,底层还是普通for循环,直到深入了解迭代器的时候,才发现自己错了,本节就来探讨一下foreach, ...
- Servlet Struts2 SpringMVC 获取参数与导出数据 方法比较
servlet中通过request.getParameter()从网页获取参数 通过request session servletContext几个域对象的setAttribute(String ,O ...
- iOS:动画(18-10-15更)
目录 1.UIView Animation 1-1.UIView Animation(基本使用) 1-2.UIView Animation(转场动画) 2.CATransaction(Layer版的U ...
- 团体队列 UVA540 Team Queue
题目描述 有t个团队的人正在排一个长队.每次新来一个人时,如果他有队友在排队,那么新人会插队到最后一个队友的身后.如果没有任何一个队友排队,则他会被排到长队的队尾. 输入每个团队中所有队员的编号,要求 ...
- Git单人本地仓库操作
本地仓库是个.git隐藏文件 以下为演示Git单人本地仓库操作 1.安装git sudo apt-get install git 密码:skylark 2.查看git安装结果 git 3.创建项目 在 ...