简述MapReduce计算框架原理
1. MapReduce基本编程模型和框架
1.1 MapReduce抽象模型
大数据计算的核心思想是:分而治之。如下图所示。把大量的数据划分开来,分配给各个子任务来完成。再将结果合并到一起输出。注:如果数据的耦合性很高,不能分离,那么这种并行计算就不合适了。
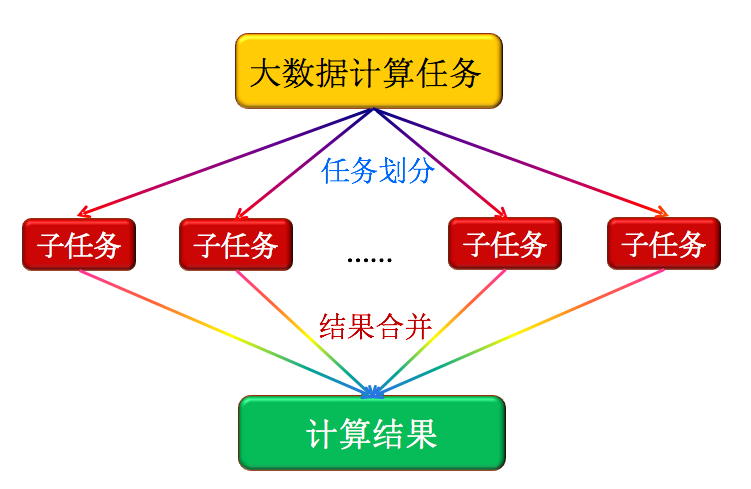
图1: MapReduce抽象模型
1.2 Hadoop的MapReduce的并行编程模型
如下图2所示,Hadoop的MapReduce先将数据划分为多个key/value键值对。然后输入Map框架来得到新的key/value对,这时候只是中间结果,这个时候的value值是个集合。再通过同步屏障(为了等待所有的Map处理完),这个阶段会把相同key的值收集整理(Aggregation&Shuffle)在一起,再交给Reduce框架做输出组合,如图2中每个Map输出的结果,有K1,K2,K3,通过同步屏障后,K2收集到一起,K2收集到一起,K3收集到一起,再分别交给Reduce,通过Reduce组合结果。
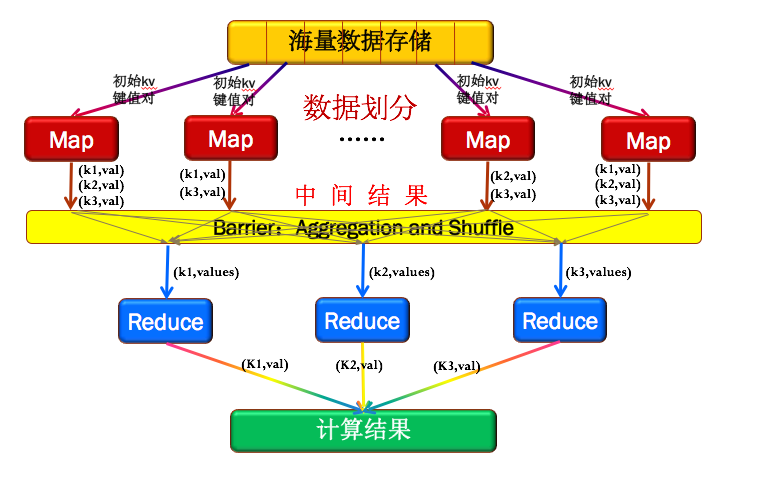
图2:Hadoop的MapReduce的框架
1.3 Hadoop的MapReduce的完整编程模和框架
图3是MapReduce的完整编程模型和框架,比模型上多加入了Combiner和Partitioner。
Combiner
Combiner可以理解为一个小的Reduce,就是把每个Map结果,先做一次整合。例如图3中第三列的Map结果中有2个good,通过Combiner之后,先将本地的2个goods组合到了一起(红色的(good,2))。好处是大大减少需要传输的中间结果数量,达到网络数据传输优化,这也是Combiner的主要作用。Partitioner
为了保证所有的主键相同的key值对能传输给同一个Reduce节点,如图3中所有的good传给第一个Reduce前,所有的is和has传给第二个Reduce前,所有的weather,the和today传到第三个Reduce前。MapReduce专门提供了一个Partitioner类来完成这个工作,主要目的就是消除数据传入的Reduce节点后带来不必要的相关性。
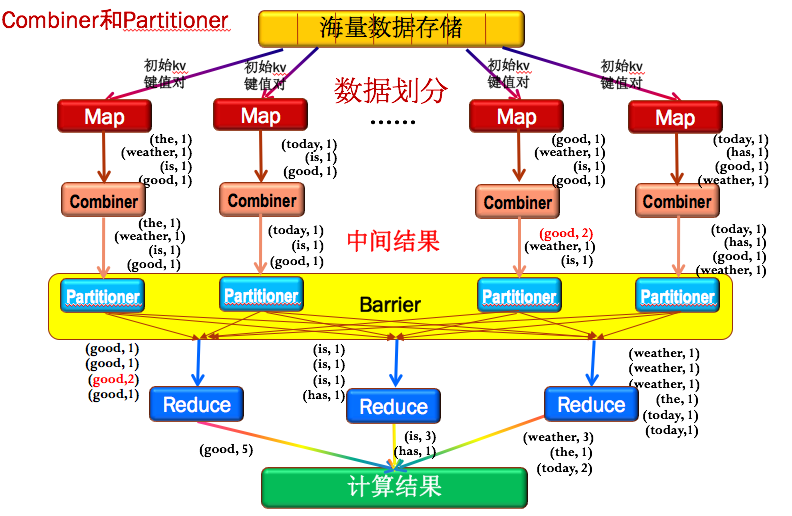
图3:Hadoop的MapReduce的完整编程模型和框架
简述MapReduce计算框架原理的更多相关文章
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
- MapReduce——计算温度最大值 (基于全新2.2.0API)
MapReduce——计算温度最大值 (基于全新2.2.0API) deprecated: Job类的所有Constructors, 新的API用静态方法getInstance(conf)来去的Job ...
- MapReduce计算模型的优化
MapReduce 计算模型的优化涉及了方方面面的内容,但是主要集中在两个方面:一是计算性能方面的优化:二是I/O操作方面的优化.这其中,又包含六个方面的内容. 1.任务调度 任务调度是Hadoop中 ...
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- 组合式MapReduce计算作业
1)迭代MapReduce计算任务,就是在一个循环内多次执行一个MapReduce. 2)顺序组合式MapReduce作业的执行 MapReduce1—>MapReduce2—>MapRe ...
- MapReduce计算每年最大值测试样例生成程序
Demo.java package com.java; import java.io.BufferedWriter; import java.io.File; import java.io.FileW ...
- Hadoop—MapReduce计算气象温度
Hadoop-MapReduce计算气象温度 1 运行环境说明 1.1 硬软件环境 主机操作系统:Mac OS 64 bit ,8G内存 虚拟软件:Parallers Desktop12 虚拟机操作系 ...
- MapReduce计算模型二
之前写过关于Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop应用(一) 介绍了MapReduce的模型和Hadoop下的MapReduce框架,此文章将进一步介绍map ...
随机推荐
- 洛谷3805:【模板】manacher算法——题解
https://www.luogu.org/problemnew/show/P3805 给出一个只由小写英文字符a,b,c...y,z组成的字符串S,求S中最长回文串的长度. 字符串长度为n 板子题, ...
- 史上最全Linux提权后获取敏感信息方法
http://www.freebuf.com/articles/system/23993.html 在本文开始之前,我想指出我不是专家.据我所知,在这个庞大的区域,没有一个“神奇”的答案.分享,共享( ...
- python 多线程实现
多线程和多进程是什么自行google补脑 对于python 多线程的理解,我花了很长时间,搜索的大部份文章都不够通俗易懂.所以,这里力图用简单的例子,让你对多线程有个初步的认识. 单线程 在好些年前的 ...
- 如何设置Eclipse使用JDK
1.打开Eclipse,选择Windows->Preferences,如图所示: 2.配置本地安装的jdk,如图所示: 注意:首先要先安装JDK. 木头大哥所发的文章均基于自身实践, ...
- Codeforces Round #514 (Div. 2):D. Nature Reserve(二分+数学)
D. Nature Reserve 题目链接:https://codeforces.com/contest/1059/problem/D 题意: 在二维坐标平面上给出n个数的点,现在要求一个圆,能够容 ...
- Android Studio中进行单元测试
写单元测试类 1.创建单元测试文件夹,即新建一个用于单元测试的包,存放单元测试的类. 2.创建一个类如 ExampleTest,注意要继承自InstrumentationTestCase类. 3.创建 ...
- bzoj 4414 数量积 结论题
数量积 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 389 Solved: 147[Submit][Status][Discuss] Descri ...
- HDU 1044 BFS
Collect More Jewels Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Othe ...
- mac之os x系统下搭建nodejs+express4.x+mongodb+gruntjs整套前端工程
第一次在Mac OS X上搭建前端开发环境,做一个小小记录,包括一些与windows系统的区别和常用快捷键 首先,在进行环境搭建之前先来看一下苹果系统的“cmd”,也就是Terminal(终端). 打 ...
- Strand Sort
Strand sort是思路是这样的,它首先需要一个空的数组用来存放最终的输出结果,给它取个名字叫"有序数组" 然后每次遍历待排数组,得到一个"子有序数组",然 ...