数据结构开发(14):KMP 子串查找算法
0.目录
1.KMP 子串查找算法
2.KMP 算法的应用
3.小结
1.KMP 子串查找算法
问题:
如何在目标字符串S中,查找是否存在子串P?
朴素解法:

朴素解法的一个优化线索:

示例:
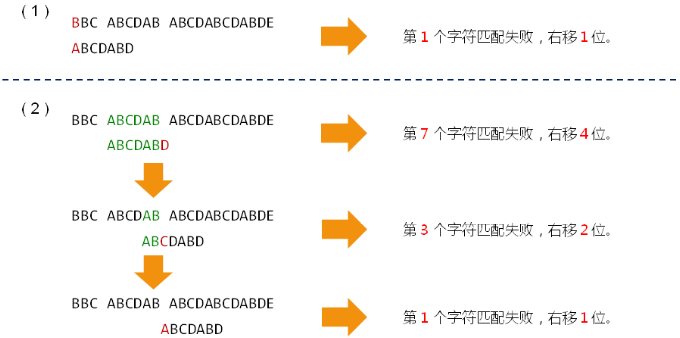
伟大的发现:
- 匹配失败时的右移位数与子串本身相关,与目标串无关
- 移动位数 = 已匹配的字符数 - 对应的部分匹配值
- 任意子串都存在一个唯一的部分匹配表
部分匹配表示例:
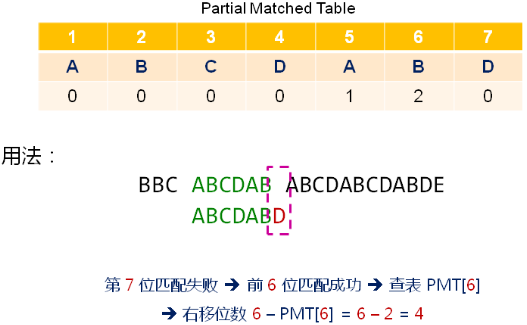
问题:
部分匹配表是怎么得到的?
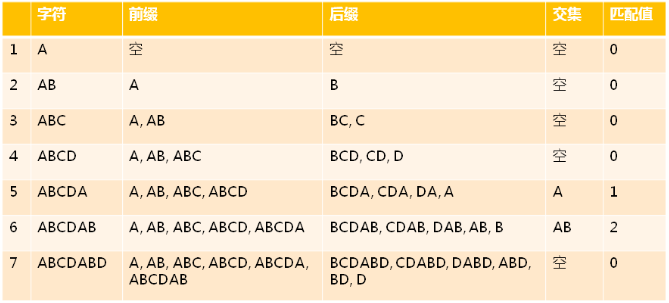
- 前缀
- 除了最后一个字符以外,一个字符串的全部头部组合
- 后缀
- 除了第一个字符以外,一个字符串的全部尾部组合
- 部分匹配值
- 前缀和后缀最长共有元素的长度
示例:ABCDABD
问题:
- 怎么编程产生部分匹配表?
实现关键:
- PMT[1] = 0 ( 下标为0的元素匹配值为0 )
- 从 2 个字符开始递推 ( 从下标为 1 的字符开始递推 )
- 假设 PMT[n] = PMT[n-1] + 1 ( 最长共有元素的长度 )
- 当假设不成立,PMT[n] 在 PMT[n-1] 的基础上减小
编程产生部分匹配表:
(ll代表longest length,即最长共有元素的长度。推导过程遵循下列原则:
(1). 当前欲求的ll值,通过历史ll值推导。
(2). 当可选ll值为0时,直接比对首尾元素。
在求ababax的最后一项ll值时,
前缀为aba b,
后缀为aba x。
重叠部分的长度就是当前的ll值,即:3;PMT(3)的含义是查找3个字符时的ll值,而3个字符时的ll值对应着下标为2的情形;编程实现时注意长度与下标的对应关系。)
#include <iostream>
#include <cstring>
using namespace std;
int* make_pmt(const char* p)
{
int len = strlen(p);
int* ret = static_cast<int*>(malloc(sizeof(int) * len));
if( ret != NULL )
{
int ll = 0;
ret[0] = 0;
for(int i=1; i<len; i++)
{
while( (ll > 0) && (p[ll] != p[i]) )
{
ll = ret[ll-1];
}
if( p[ll] == p[i] )
{
ll++;
}
ret[i] = ll;
}
}
return ret;
}
int main()
{
int* pmt_1 = make_pmt("ababax");
cout << "ababax:" << endl;
for(int i=0; i<strlen("ababax"); i++)
{
cout << i << " : " << pmt_1[i] << endl;
}
cout << endl;
int* pmt_2 = make_pmt("ABCDABD");
cout << "ABCDABD:" << endl;
for(int i=0; i<strlen("ABCDABD"); i++)
{
cout << i << " : " << pmt_2[i] << endl;
}
return 0;
}
运行结果为:
ababax:
0 : 0
1 : 0
2 : 1
3 : 2
4 : 3
5 : 0
ABCDABD:
0 : 0
1 : 0
2 : 0
3 : 0
4 : 1
5 : 2
6 : 0
部分匹配表的使用 ( KMP 算法 ):

实现KMP算法:
#include <iostream>
#include <cstring>
using namespace std;
int* make_pmt(const char* p)
{
int len = strlen(p);
int* ret = static_cast<int*>(malloc(sizeof(int) * len));
if( (ret != NULL) && (len > 0) )
{
int ll = 0;
ret[0] = 0;
for(int i=1; i<len; i++)
{
while( (ll > 0) && (p[ll] != p[i]) )
{
ll = ret[ll-1];
}
if( p[ll] == p[i] )
{
ll++;
}
ret[i] = ll;
}
}
return ret;
}
int kmp(const char* s, const char* p)
{
int ret = -1;
int sl = strlen(s);
int pl = strlen(p);
int* pmt = make_pmt(p);
if( (pmt != NULL) && (0 < pl) && (pl <= sl) )
{
for(int i=0, j=0; i<sl; i++)
{
while( (j > 0) && (s[i] != p[j]) )
{
j = pmt[j-1];
}
if( s[i] == p[j] )
{
j++;
}
if( j == pl )
{
ret = i + 1 - pl;
break;
}
}
}
free(pmt);
return ret;
}
int main()
{
cout << kmp("abcde", "cde") << endl;
cout << kmp("ababax", "ba") << endl;
cout << kmp("ababax", "ax") << endl;
cout << kmp("ababax", "") << endl;
cout << kmp("ababax", "ababaxy") << endl;
return 0;
}
运行结果为:
2
1
4
-1
-1
2.KMP 算法的应用
思考:
- 如何在目标字符串中查找是否存在指定的子串?
字符串类中的新功能:

将kmp算法的代码集成到自定义字符串类中去:
protected:
static int* make_pmt(const char* p);
static int kmp(const char* s, const char* p);
具体实现:
int* String::make_pmt(const char* p)
{
int len = strlen(p);
int* ret = static_cast<int*>(malloc(sizeof(int) * len));
if( (ret != NULL) && (len > 0) )
{
int ll = 0;
ret[0] = 0;
for(int i=1; i<len; i++)
{
while( (ll > 0) && (p[ll] != p[i]) )
{
ll = ret[ll-1];
}
if( p[ll] == p[i] )
{
ll++;
}
ret[i] = ll;
}
}
return ret;
}
int String::kmp(const char* s, const char* p)
{
int ret = -1;
int sl = strlen(s);
int pl = strlen(p);
int* pmt = make_pmt(p);
if( (pmt != NULL) && (0 < pl) && (pl <= sl) )
{
for(int i=0, j=0; i<sl; i++)
{
while( (j > 0) && (s[i] != p[j]) )
{
j = pmt[j-1];
}
if( s[i] == p[j] )
{
j++;
}
if( j == pl )
{
ret = i + 1 - pl;
break;
}
}
}
free(pmt);
return ret;
}
子串查找 ( KMP 算法的直接运用 ):
- int indexOf(const char* s) const
- int indexOf(const String& s) const
子串查找:
public:
int indexOf(const char* s) const;
int indexOf(const String& s) const;
具体实现:
int String::indexOf(const char* s) const
{
return kmp(m_str, s ? s : "");
}
int String::indexOf(const String& s) const
{
return kmp(m_str, s.m_str);
}
在字符串中将指定的子串删除:
- String& remove(const char* s)
- String& remove(const String& s)

在字符串中将指定的子串删除:
public:
String& remove(int i, int len);
String& remove(const char* s);
String& remove(const String& s);
具体实现:
String& String::remove(int i, int len)
{
if( (0 <= i) && (i < m_length) )
{
int n = i;
int m = i + len;
while( (n < m) && (m < m_length) )
{
m_str[n++] = m_str[m++];
}
m_str[n] = '\0';
m_length = n;
}
return *this;
}
String& String::remove(const char* s)
{
return remove(indexOf(s), s ? strlen(s) : 0);
}
String& String::remove(const String& s)
{
return remove(indexOf(s), s.length());
}
字符串的减法操作定义 ( operator - ):
- 使用 remove 实现字符串间的减法操作
- 字符串自身不被修改
- 返回产生的新串

字符串的减法操作定义:
public:
String operator - (const String& s) const;
String operator - (const char* s) const;
String& operator -= (const String& s);
String& operator -= (const char* s);
具体实现:
String String::operator - (const String& s) const
{
return String(*this).remove(s);
}
String String::operator - (const char* s) const
{
return String(*this).remove(s);
}
String& String::operator -= (const String& s)
{
return remove(s);
}
String& String::operator -= (const char* s)
{
return remove(s);
}
字符串中的子串替换:
- String& replace(const char* t, const char* s)
- String& replace(const String& t, const char* s)
- String& replace(const char* t, const String& s)
- String& replace(const String& t, const String& s)
字符串中的子串替换:
public:
String& replace(const char* t, const char* s);
String& replace(const String& t, const char* s);
String& replace(const char* t, const String& s);
String& replace(const String& t, const String& s);
具体实现:
String& String::replace(const char* t, const char* s)
{
int index = indexOf(t);
if( index >= 0 )
{
remove(t);
insert(index, s);
}
return *this;
}
String& String::replace(const String& t, const char* s)
{
return replace(t.m_str, s);
}
String& String::replace(const char* t, const String& s)
{
return replace(t, s.m_str);
}
String& String::replace(const String& t, const String& s)
{
return replace(t.m_str, s.m_str);
}
从字符串中创建子串:
- String sub(int i, int len) const
- 以 i 为起点提取长度为 len 的子串
- 子串提取不会改变字符串本身的状态

从字符串中创建子串:
public:
String sub(int i, int len) const;
具体实现:
String String::sub(int i, int len) const
{
String ret;
if( (0 <= i) && (i < m_length) )
{
if( len < 0 ) len = 0;
if( len + i > m_length ) len = m_length - i;
char* str = reinterpret_cast<char*>(malloc(len + 1));
strncpy(str, m_str + i, len);
str[len] = '\0';
ret = str;
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Parameter i is invalid ...");
}
return ret;
}
3.小结
- 部分匹配表是提高子串查找效率的关键
- 部分匹配值定义为前缀和后缀最长共有元素的长度
- 可以用递推的方法产生部分匹配表
- KMP 利用部分匹配值与子串移动位数的关系提高查找效率
- 字符串类是工程开发中必不可少的组件
- 字符串中应该包含常用字符串操作函数
- 增 : insert , operator + , ...
- 删 : remove , operator - , ...
- 查 : indexOf , ...
- 改 : replace , ...
最终的自定义字符串类代码:
StString.h
#ifndef STSTRING_H
#define STSTRING_H
#include "Object.h"
namespace StLib
{
class String : public Object
{
protected:
char* m_str;
int m_length;
void init(const char* s);
bool equal(const char* l, const char* r, int len) const;
static int* make_pmt(const char* p);
static int kmp(const char* s, const char* p);
public:
String();
String(char c);
String(const char* s);
String(const String& s);
int length() const;
const char* str() const;
bool startWith(const char* s) const;
bool startWith(const String& s) const;
bool endOf(const char* s) const;
bool endOf(const String& s) const;
String& insert(int i, const char* s);
String& insert(int i, const String& s);
String& trim();
int indexOf(const char* s) const;
int indexOf(const String& s) const;
String& remove(int i, int len);
String& remove(const char* s);
String& remove(const String& s);
String& replace(const char* t, const char* s);
String& replace(const String& t, const char* s);
String& replace(const char* t, const String& s);
String& replace(const String& t, const String& s);
String sub(int i, int len) const;
char& operator [] (int i);
char operator [] (int i) const;
bool operator == (const String& s) const;
bool operator == (const char* s) const;
bool operator != (const String& s) const;
bool operator != (const char* s) const;
bool operator > (const String& s) const;
bool operator > (const char* s) const;
bool operator < (const String& s) const;
bool operator < (const char* s) const;
bool operator >= (const String& s) const;
bool operator >= (const char* s) const;
bool operator <= (const String& s) const;
bool operator <= (const char* s) const;
String operator + (const String& s) const;
String operator + (const char* s) const;
String& operator += (const String& s);
String& operator += (const char* s);
String operator - (const String& s) const;
String operator - (const char* s) const;
String& operator -= (const String& s);
String& operator -= (const char* s);
String& operator = (const String& s);
String& operator = (const char* s);
String& operator = (char c);
~String();
};
}
#endif // STSTRING_H
StString.cpp
#include <cstring>
#include <cstdlib>
#include "StString.h"
#include "Exception.h"
using namespace std;
namespace StLib
{
int* String::make_pmt(const char* p)
{
int len = strlen(p);
int* ret = static_cast<int*>(malloc(sizeof(int) * len));
if( (ret != NULL) && (len > 0) )
{
int ll = 0;
ret[0] = 0;
for(int i=1; i<len; i++)
{
while( (ll > 0) && (p[ll] != p[i]) )
{
ll = ret[ll-1];
}
if( p[ll] == p[i] )
{
ll++;
}
ret[i] = ll;
}
}
return ret;
}
int String::kmp(const char* s, const char* p)
{
int ret = -1;
int sl = strlen(s);
int pl = strlen(p);
int* pmt = make_pmt(p);
if( (pmt != NULL) && (0 < pl) && (pl <= sl) )
{
for(int i=0, j=0; i<sl; i++)
{
while( (j > 0) && (s[i] != p[j]) )
{
j = pmt[j-1];
}
if( s[i] == p[j] )
{
j++;
}
if( j == pl )
{
ret = i + 1 - pl;
break;
}
}
}
free(pmt);
return ret;
}
void String::init(const char *s)
{
m_str = strdup(s);
if( m_str )
{
m_length = strlen(m_str);
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No memory to create String object ...");
}
}
String::String()
{
init("");
}
String::String(char c)
{
char s[] = {c, '\0'};
init(s);
}
String::String(const char *s)
{
init(s ? s : "");
}
String::String(const String &s)
{
init(s.m_str);
}
int String::length() const
{
return m_length;
}
const char* String::str() const
{
return m_str;
}
bool String::equal(const char* l, const char* r, int len) const
{
bool ret = true;
for(int i=0; i<len && ret; i++)
{
ret = ret && (l[i] == r[i]);
}
return ret;
}
bool String::startWith(const char* s) const
{
bool ret = (s != NULL);
if( ret )
{
int len = strlen(s);
ret = (len < m_length) && equal(m_str, s, len);
}
return ret;
}
bool String::startWith(const String& s) const
{
return startWith(s.m_str);
}
bool String::endOf(const char* s) const
{
bool ret = (s != NULL);
if( ret )
{
int len = strlen(s);
char* str = m_str + (m_length - len);
ret = (len < m_length) && equal(str, s, len);
}
return ret;
}
bool String::endOf(const String& s) const
{
return endOf(s.m_str);
}
String& String::insert(int i, const char* s)
{
if( (0 <= i) && (i <= m_length) )
{
if( (s != NULL) && (s[0] != '\0') )
{
int len = strlen(s);
char* str = reinterpret_cast<char*>(malloc(m_length + len + 1));
if( str != NULL )
{
strncpy(str, m_str, i);
strncpy(str + i, s, len);
strncpy(str + i + len, m_str + i, m_length - i);
str[m_length + len] = '\0';
free(m_str);
m_str = str;
m_length = m_length + len;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No memory to insert string value ...");
}
}
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Parameter i is invalid ...");
}
return *this;
}
String& String::insert(int i, const String& s)
{
return insert(i, s.m_str);
}
String& String::trim()
{
int b = 0;
int e = m_length - 1;
while( m_str[b] == ' ' ) b++;
while( m_str[e] == ' ' ) e--;
if( b == 0 )
{
m_str[e + 1] = '\0';
m_length = e + 1;
}
else
{
for(int i=0, j=b; j<=e; i++, j++)
{
m_str[i] = m_str[j];
}
m_str[e - b + 1] = '\0';
m_length = e - b + 1;
}
return *this;
}
int String::indexOf(const char* s) const
{
return kmp(m_str, s ? s : "");
}
int String::indexOf(const String& s) const
{
return kmp(m_str, s.m_str);
}
String& String::remove(int i, int len)
{
if( (0 <= i) && (i < m_length) )
{
int n = i;
int m = i + len;
while( (n < m) && (m < m_length) )
{
m_str[n++] = m_str[m++];
}
m_str[n] = '\0';
m_length = n;
}
return *this;
}
String& String::remove(const char* s)
{
return remove(indexOf(s), s ? strlen(s) : 0);
}
String& String::remove(const String& s)
{
return remove(indexOf(s), s.length());
}
String& String::replace(const char* t, const char* s)
{
int index = indexOf(t);
if( index >= 0 )
{
remove(t);
insert(index, s);
}
return *this;
}
String& String::replace(const String& t, const char* s)
{
return replace(t.m_str, s);
}
String& String::replace(const char* t, const String& s)
{
return replace(t, s.m_str);
}
String& String::replace(const String& t, const String& s)
{
return replace(t.m_str, s.m_str);
}
String String::sub(int i, int len) const
{
String ret;
if( (0 <= i) && (i < m_length) )
{
if( len < 0 ) len = 0;
if( len + i > m_length ) len = m_length - i;
char* str = reinterpret_cast<char*>(malloc(len + 1));
strncpy(str, m_str + i, len);
str[len] = '\0';
ret = str;
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Parameter i is invalid ...");
}
return ret;
}
char& String::operator [] (int i)
{
if( (0 <= i) && (i < m_length) )
{
return m_str[i];
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Parameter i is invalid ...");
}
}
char String::operator [] (int i) const
{
return (const_cast<String&>(*this))[i];
}
bool String::operator == (const String& s) const
{
return (strcmp(m_str, s.m_str) == 0);
}
bool String::operator == (const char* s) const
{
return (strcmp(m_str, s ? s : "") == 0);
}
bool String::operator != (const String& s) const
{
return !(*this == s);
}
bool String::operator != (const char* s) const
{
return !(*this == s);
}
bool String::operator > (const String& s) const
{
return (strcmp(m_str, s.m_str) > 0);
}
bool String::operator > (const char* s) const
{
return (strcmp(m_str, s ? s : "") > 0);
}
bool String::operator < (const String& s) const
{
return (strcmp(m_str, s.m_str) < 0);
}
bool String::operator < (const char* s) const
{
return (strcmp(m_str, s ? s : "") < 0);
}
bool String::operator >= (const String& s) const
{
return (strcmp(m_str, s.m_str) >= 0);
}
bool String::operator >= (const char* s) const
{
return (strcmp(m_str, s ? s : "") >= 0);
}
bool String::operator <= (const String& s) const
{
return (strcmp(m_str, s.m_str) <= 0);
}
bool String::operator <= (const char* s) const
{
return (strcmp(m_str, s ? s : "") <= 0);
}
String String::operator + (const String& s) const
{
return (*this + s.m_str);
}
String String::operator + (const char* s) const
{
String ret;
int len = m_length + strlen(s ? s : "");
char* str = reinterpret_cast<char*>(malloc(len + 1));
if( str )
{
strcpy(str, m_str);
strcat(str, s ? s : "");
free(ret.m_str);
ret.m_str = str;
ret.m_length = len;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No memory to add String values ...");
}
return ret;
}
String& String::operator += (const String& s)
{
return (*this = *this + s.m_str);
}
String& String::operator += (const char* s)
{
return (*this = *this + s);
}
String String::operator - (const String& s) const
{
return String(*this).remove(s);
}
String String::operator - (const char* s) const
{
return String(*this).remove(s);
}
String& String::operator -= (const String& s)
{
return remove(s);
}
String& String::operator -= (const char* s)
{
return remove(s);
}
String& String::operator = (const String& s)
{
return (*this = s.m_str);
}
String& String::operator = (const char* s)
{
if( m_str != s )
{
char* str = strdup(s ? s : "");
if( str )
{
free(m_str);
m_str = str;
m_length = strlen(m_str);
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No memory to assign new String value ...");
}
}
return *this;
}
String& String::operator = (char c)
{
char s[] = {c, '\0'};
return (*this = s);
}
String::~String()
{
free(m_str);
}
}
数据结构开发(14):KMP 子串查找算法的更多相关文章
- 第四十一课 KMP子串查找算法
问题: 右移的位数和目标串没有多大的关系,和子串有关系. 已匹配的字符数现在已经有了,部分匹配值还没有. 前六位匹配成功就去查找PMT中的第六位. 现在的任务就是求得部分匹配表. 问题:怎么得到部分匹 ...
- 字符串类——KMP子串查找算法
1, 如何在目标字符串 s 中,查找是否存在子串 p(本文代码已集成到字符串类——字符串类的创建(上)中,这里讲述KMP实现原理) ? 1,朴素算法: 2,朴素解法的问题: 1,问题:有时候右移一位是 ...
- 第41课 kmp子串查找算法
1. 朴素算法的改进 (1)朴素算法的优化线索 ①因为 Pa != Pb 且Pb==Sb:所以Pa != Sb:因此在Sd处失配时,子串P右移1位比较没有意义,因为前面的比较己经知道了Pa != Sb ...
- 【数据结构】 字符串&KMP子串匹配算法
字符串 作为人机交互的途径,程序或多或少地肯定要需要处理文字信息.如何在计算机中抽象人类语言的信息就成为一个问题.字符串便是这个问题的答案.虽然从形式上来说,字符串可以算是线性表的一种,其数据储存区存 ...
- KMP字符串查找算法
#include <iostream> #include <windows.h> using namespace std; void get_next(char *str,in ...
- 串、串的模式匹配算法(子串查找)BF算法、KMP算法
串的定长顺序存储#define MAXSTRLEN 255,//超出这个长度则超出部分被舍去,称为截断 串的模式匹配: 串的定义:0个或多个字符组成的有限序列S = 'a1a2a3…….an ' n ...
- 数据结构与算法之PHP查找算法(哈希查找)
一.哈希查找的定义 提起哈希,我第一印象就是PHP里的关联数组,它是由一组key/value的键值对组成的集合,应用了散列技术. 哈希表的定义如下: 哈希表(Hash table,也叫散列表),是根据 ...
- 数据结构和算法(Golang实现)(26)查找算法-哈希表
哈希表:散列查找 一.线性查找 我们要通过一个键key来查找相应的值value.有一种最简单的方式,就是将键值对存放在链表里,然后遍历链表来查找是否存在key,存在则更新键对应的值,不存在则将键值对链 ...
- 数据结构和算法(Golang实现)(27)查找算法-二叉查找树
二叉查找树 二叉查找树,又叫二叉排序树,二叉搜索树,是一种有特定规则的二叉树,定义如下: 它是一颗二叉树,或者是空树. 左子树所有节点的值都小于它的根节点,右子树所有节点的值都大于它的根节点. 左右子 ...
随机推荐
- python 利用urllib 获取办公区公网Ip
import json,reimport urllib.requestdef GetLocalIP(): IPInfo = urllib.request.urlopen("http://ip ...
- linux 查询管道过滤,带上标题字段
linux查询过滤, 带上标题字段例: 一个简单的查询 ps -e | grep httpd 上面经过grep 过滤后, 标题没了, 但是为了看上去更方便,有标题字段看起来更方便一些, 那么可以按下面 ...
- AssetBundle一些问题
AssetBundle划分过细的问题,比如每个资源都是AssetBundle. 加载IO次数过多,从而增大了硬件设备耗能和发热的压力: Unity 5.3 ~ 5.5 版本中,Android平台上在不 ...
- alibaba/canal 阿里巴巴 mysql 数据库 binlog 增量订阅&消费组件
基于日志增量订阅&消费支持的业务: 数据库镜像 数据库实时备份 多级索引 (卖家和买家各自分库索引) search build 业务cache刷新 价格变化等重要业务消息 项目介绍 名称:ca ...
- 编码 解码 python
之前一直对python文件中编码解码糊里糊涂,今天看到一篇文章,觉得把我讲的有点明白了.写个心得吧. 1.编码解码是怎么一回事? Python 里面的编码和解码也就是 unicode 和 str 这两 ...
- jar包冲突常用的解决方法
jar包冲突常见的异常为找不到类(java.lang.ClassNotFoundException).找不到具体方法(java.lang.NoSuchMethodError).字段错误( java.l ...
- Oracle中的SQL分页查询原理和方法详解
Oracle中的SQL分页查询原理和方法详解 分析得不错! http://blog.csdn.net/anxpp/article/details/51534006
- TeamWork#3,Week5,Scrum Meeting 11.13
最近我们根据之前发现的问题, 补充了相关知识,正在努力修复出现的问题,调整程序结构. 成员 已完成 待完成 彭林江 之前没有考虑到网站信息更新导致的程序可变性,正在调整爬虫程序结构 更换爬虫结构 郝倩 ...
- android学习-2 (AVD 创建)
在Android studio的tools下选择AVD manager 按照指示选择相应的硬件和系统映像. 在模拟器中运行应用 选择RUN APP 选择RUN时,并不只运行应用,还会处理运行应用所需要 ...
- NABCD模型分析
1.N——need需求 目前,学习英语是所有学生会面临的问题.提高词汇量对学习英语是十分必要的,尤其是对大学生来说对手机的使用特别频繁,我们提高英语词汇量也应该把手机更好的利用起来,利用自己对手机的使 ...