字符串类——KMP子串查找算法
1, 如何在目标字符串 s 中,查找是否存在子串 p(本文代码已集成到字符串类——字符串类的创建(上)中,这里讲述KMP实现原理) ?
1,朴素算法:

2,朴素解法的问题:
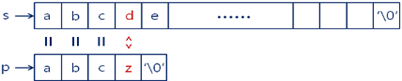

1,问题:有时候右移一位是没有意义的;
2,KMP 算法可以右移一定的位数,提高效率;
3,朴素算法和 KMP 算法对比示例图:
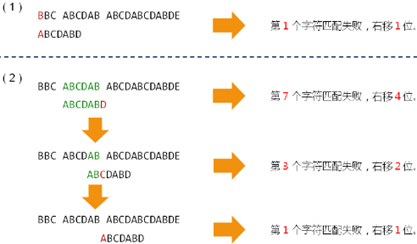
2,伟大的发现(KMP):
1,匹配失败时的右移位数与子串本身相关,与目标无关;
2,移动位数 = 已匹配的字符数 - 对应的部分匹配值;
1,“已匹配的字符数”已知,“对应的部分匹配值”未知;
(2),部分匹配值就是对应元素和从开始元素开始连续相同的个数;
3,任意子串都存在一个唯一的部分匹配值;
3,部分匹配表示例:

4,部分匹配表如何获得 ?
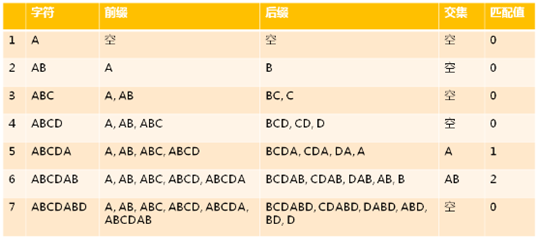
1,前缀集:
1,除了最后一个字符外,一个字符串的全部头部组合;
2,后缀集:
1,除了第一个字符以外,一个字符串的全部尾部组合;
3,部分匹配值:
1,前缀集和后缀集最长共有元素的长度;
(2),得到共有长度是为了得到对应各个位置前面不相同的元素个数,这样如果前面不同元素匹配了,那么就可以直接移动的了;
4,ABCDABD 部分匹配表示例:
5,怎么编程产生部分匹配表(Partial Matched Table)(递推完成)?
1,实现关键:
1,PMT[1] = 0(下标为 0 的元素匹配值为 0);
2,从 2 个字符开始递推(从下标为 1 的字符开始递推);
3,假设 PMT[n] = PMT[n-1] + 1(最长共有元素的长度)(这是一个贪心假设);
4,当假设不成立,PMT[n] 在 PMT[n-1](这里是指的第 PMT[n-1] 个元素)个元素的 ll 值上用种子作为扩展的基础上继续比对;
1,当当前前子集“前后集最长共有元素数”为 0 时,说明其元素都不相等,可以直接比较当前子集延长一字母序列的首尾字母,且此子集“前后集最长共有元素数”最大为 1;
2,将 “前后集最长共有元素数”对应的前后缀最为种子扩展;
3,假设不成立时,把已经匹配的前 PMT[n-1] 个元素的“前后集最长共有元素数”(因为必须在相同的位置上扩展才有意义)作为种子来扩展;
6,部分匹配表的递推与实现:
1,部分匹配表的递推:

2,在 String 中实现部分匹配表:
/* 建立指定字符串的 pmt(部分匹配表)表 */
int* String::make_pmt(const char* p) // O(m),只有一个 for 循环
{
int len = strlen(p);
int* ret = static_cast<int*>(malloc(sizeof(int) * len)); if ( ret != NULL )
{
int ll = ; //定义 ll,前缀和后缀交集的最大长度数,largest length;第一步
ret[] = ; // 长度为 1 的字符串前后集都为空,对应 ll 为 0; for(int i=; i<len; i++) // 从第一个下标,也就是第二个字符开始计算,因为第 0 个字符前面已经计算过了; 第二步
{
/* 算法第四步 */
while( (ll > ) && (p[ll] != p[i]) ) // 当 ll 值为零时,转到下面 if() 函数继续判断,最后赋值与匹配表,所以顺序不要错;
{
ll = ret[ll - ]; // 从之前匹配的部分匹配值表中,继续和最后扩展的那个字符匹配
} /* 算法的第三步,这是成功的情况 */
if( p[ll] == p[i] ) // 根据 ll 来确定扩展的种子个数为 ll,而数组 ll 处就处对应的扩展元素,然后和最新扩展的元素比较;
{
ll++; // 若相同(与假设符合)则加一
} ret[i] = ll; // 部分匹配表里存储部分匹配值 ll
}
} return ret;
}
7,部分匹配表的使用(KMP 算法):
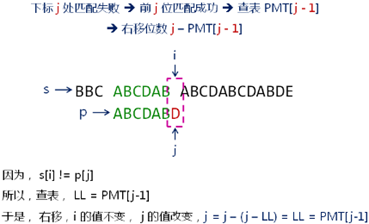
1,不匹配时,移动位置,之后直接从/字符串的/不匹配前字符/的部分匹配值下标处/开始匹配;
8,KMP 子串查找算法在 String 中的实现 :
/* 在字符串 s 中查找子串 p */
int String::kmp(const char* s, const char* p) // O(m) + O(n) ==> O(m+n), 只有一个 for 循环
{
int ret = -;
int sl = strlen(s);
int pl = strlen(p);
int* pmt = make_pmt(p); if( (pmt != NULL) && ( < pl) && (pl <= sl) ) // 判断查找条件
{
for(int i=, j=; i<sl; i++) // i 的值要小于目标窜长度才可以查找
{
while( (j > ) && (s[i] != p[j]) ) // 比对不上的时候,持续比对,
{
j = pmt[j-];//移动后应该继续匹配的位置,j =j-(j -LL)=LL = PMT[j-1]
} if( s[i] == p[j] ) // 比对字符成功
{
j++; // 加然后比对下一个字符
} if( j == pl ) // 这个时候是查找到了,因为 j 增加到了 pl 的长度;
{
ret = i + - pl; // 匹配成功后,i 的值停在最后一个匹配成功的字符上,这样就返回匹配成功的位置 break;
}
}
} free(pmt); return ret;
}
9,小结:
1,部分匹配表是提高子串查找效率的关键;
2,部分匹配值定义为前缀和后缀最长共有元素的长度;
3,可以用递推的方法产生部分匹配表;
4,KMP 利用部分匹配值与子串移动位数的关系提高查找效率;
1,每次匹配失败的时候,子串不会简单的右移一位,而是查询部分匹配表中的值,查到后则右移一定位数,使算法效率由平方变成线性时间;
字符串类——KMP子串查找算法的更多相关文章
- 数据结构开发(14):KMP 子串查找算法
0.目录 1.KMP 子串查找算法 2.KMP 算法的应用 3.小结 1.KMP 子串查找算法 问题: 如何在目标字符串S中,查找是否存在子串P? 朴素解法: 朴素解法的一个优化线索: 示例: 伟大的 ...
- 第四十一课 KMP子串查找算法
问题: 右移的位数和目标串没有多大的关系,和子串有关系. 已匹配的字符数现在已经有了,部分匹配值还没有. 前六位匹配成功就去查找PMT中的第六位. 现在的任务就是求得部分匹配表. 问题:怎么得到部分匹 ...
- 第41课 kmp子串查找算法
1. 朴素算法的改进 (1)朴素算法的优化线索 ①因为 Pa != Pb 且Pb==Sb:所以Pa != Sb:因此在Sd处失配时,子串P右移1位比较没有意义,因为前面的比较己经知道了Pa != Sb ...
- 字符串类——KMP算法的应用
1,字符串类中的新功能(本文代码已集成到字符串类——字符串类的创建(上)中,这里讲述函数实现原理): 2,子串查找(KMP 算法直接运用): 1,int indexOf(const char* s) ...
- C++自定义String字符串类,支持子串搜索
C++自定义String字符串类 实现了各种基本操作,包括重载+号实现String的拼接 findSubStr函数,也就是寻找目标串在String中的位置,用到了KMP字符串搜索算法. #includ ...
- 常见查找算法之php, js,python版
常用算法 >>>1. 顺序查找, 也叫线性查找, 它从第一个记录开始, 挨个进行对比, 是最基本的查找技术 javaScript 版顺序查找算法: // 顺序查找(线性查找) 只做找 ...
- 串、串的模式匹配算法(子串查找)BF算法、KMP算法
串的定长顺序存储#define MAXSTRLEN 255,//超出这个长度则超出部分被舍去,称为截断 串的模式匹配: 串的定义:0个或多个字符组成的有限序列S = 'a1a2a3…….an ' n ...
- KMP 算法 & 字符串查找算法
KMP算法 Knuth–Morris–Pratt algorithm 克努斯-莫里斯-普拉特 算法 algorithm kmp_search: input: an array of character ...
- 【数据结构】 字符串&KMP子串匹配算法
字符串 作为人机交互的途径,程序或多或少地肯定要需要处理文字信息.如何在计算机中抽象人类语言的信息就成为一个问题.字符串便是这个问题的答案.虽然从形式上来说,字符串可以算是线性表的一种,其数据储存区存 ...
随机推荐
- Spring之使用注解实例化Bean并注入属性
1.准备工作 (1)导入jar包 除了上篇文章使用到的基本jar包外,还得加入aop的jar包,所有jar包如下 所需jar包 (2)配置xml <?xml version="1.0& ...
- python学习第四十三天生成器和next()关联
我们在用列表生成式的时候,如果有一百万的数据,内存显然不够用,这是python想要什么数据,就生产什么数据给你,就产生了生成器,下面简单讲述生成器用法 1,生成器的用法 a=([a*a for a i ...
- arcgis server地图服务切片(10.4.1)
首先要发布地图服务,过程略 首先,熟悉arcgis server的人应该知道,最直接的切片方式操作方法是在“服务属性”中设置切片,但这种方式可操作性太差,很多设置无法实现,因此不推荐 下面正式开始,打 ...
- 攻防世界--The_Maya_Society
测试文件:https://adworld.xctf.org.cn/media/task/attachments/17574fc423474b93a0e6e6a6e583e003.zip 我们直接将Li ...
- http请求报文格式(请求行、请求头、空行 和 请求包体)和响应报文格式(状态行、响应头部、空行 和 响应包体)
转载 出处 超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求 ...
- Spark2.0集成Hive操作的相关配置与注意事项
前言 已完成安装Apache Hive,具体安装步骤请参照,Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作 补充说明 Hive中metastore(元数据存储)的三种方式 ...
- 关于print的一点秀操作
我们在玩 Python 的时候 常常会使用到 print 这个函数 主要用它来打印一些输出 这样我们可以更加方便的知道 程序的运行情况 我们常常这样操作 不过不是很骚 有时候我们想更加直观的看到我 ...
- 2018-2-13-win10-uwp-读写csv-
title author date CreateTime categories win10 uwp 读写csv lindexi 2018-2-13 17:23:3 +0800 2018-2-13 17 ...
- 搭建Keepalived+LNMP架构web动态博客 实现高可用与负载均衡
环境准备: 192.168.193.80 node1 192.168.193.81 node2 关闭防火墙 [root@node1 ~]# systemctl stop firewalld #两台都 ...
- 【学习】010 Netty异步通信框架
Netty快速入门 什么是Netty Netty 是一个基于 JAVA NIO 类库的异步通信框架,它的架构特点是:异步非阻塞.基于事件驱动.高性能.高可靠性和高可定制性. Netty应用场景 1.分 ...