Word Count作业
Word Count作业
一.个人Gitee地址:https://gitee.com/Changyu-Guo
二.项目简介
该项目主要是模拟Linux上面的wc命令,基本要求如下:
命令格式:
wc.exe [para] <filename> [para] <filename> ... -o <filename>
功能:
wc.exe -c file.c:返回文件file.c的字符数
wc.exe -w file.c:返回文件file.c的单词总数
wc.exe -l file.c:返回文件file.c的总行数
wc.exe -o outputFile.txt:将结果输出到指定文件
要求:
-o后面必须跟一个文件
-c -w -l可以同时出现
-c -w -l可以合并成-wcl,即命令可以连写如果不指定输出文件,则将结果默认保存在result.txt里面
三.PSP2.1表格
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 340 | 635 |
| · Analysis | · 需求分析(包括学习新技术) | 20 | 30 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审(和同事审核设计文档) | 10 | 15 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 15 | 20 |
| · Coding | · 具体编码 | 200 | 400 |
| · Code Review | · 代码复审 | 40 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 60 | 50 |
| · Test Report | · 测试报告 | 20 | 15 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process improvement Plan | · 事后总结,并提出过程改进计划 | 30 | 30 |
| 合计 | 405 | 690 |
四.解题思路
由于自己对C语言比较熟悉(主要是C语言编译过后就是exe,其他语言还要打包,就直接用C语言写了),因此选择用C语言来实现这个项目。刚拿到题的时候仔细分析了一下,发现在功能上的要求不高,甚至不用校验单词的有效性,凡是以空格和逗号隔开的都算是单词,因此第一次作业的难点应该在于命令行参数的解析上面。
接下来我用C语言写了一个简单的demo,尝试着梳理一下程序构建思路,应该如何设计,模块怎样划分。demo中所有的功能都在main函数里面,没有上传到码云。
写好demo后,大致整理了一下解题思路:
1.程序执行流程分析
根据项目的要求,该程序执行的大体流程为:首先用户执行程序并附带各种参数,程序首先要分析处理各种选项,校验选项的有效性,并将各种参数和对应的文件联系在一起,然后对不同的文件执行该文件对用的各种操作,然后将最终的结果一并保存在输出文件中。
2.数据结构设计
根据对程序执行流程的分析,由于不同的文件对应着不同的操作,因此需要将文件名和其对应的操作绑定在一起,由此想到了用结构体保存一个文件的相关信息,然后使用链表将各个文件连起来。待命令处理完毕后,只需遍历链表,即可对各个文件执行相应的操作。文件的结构体如下:
// 命令结构体
// 解析命令时存储相关信息
struct Node
{
bool _c;
bool _w;
bool _l;
bool _hasFile;
char inFile[];
int row;
int character;
int words;
struct Node *next;
};
3.模块划分
根据程序的执行流程,可以将程序划分为以下几个模块:
(1).主函数
主函数中主要是一些基本的处理和一些简单的逻辑的处理,负责调用其他函数
(2).命令处理模块
对于用户输入的命令的处理,有很多种办法,其中最常用的就是遍历数组,或者将输入的命令编程字符串,然后解析字符串,我选择的是将用户输入的各种选项和命令拼接成一个字符串,然后遍历整个字符串,并做相应的分析。
(3).统计模块
统计模块主要就是对每个文件做相应的统计操作,包括对行数的统计,对单词数的统计,对字符数的统计,每个功能写在一个单独的函数里面。统计完字符后顺便将数据写入文件。
五.关键代码分析
1.命令处理函数
// 对用户输入的命令进行分析
// 传入的用户输入的命令的字符串,中间用空格隔开
// 如果是-开头的,则认为是选项
// 如果检测到-o,就立即读取后面紧跟的输出文件
// 如果不是-开头的,就认为是输入文件 // 第二个参数是一串文件的头结点
void analyseCommand(char commandStr[], struct Node *Head)
{
// 遍历整个字符串
initFileNode(Head);
struct Node *cur;
cur = Head;
for (int i = ;; i++)
{
// 读出当前字符
char c = commandStr[i];
// 如果遍历到了\0,说明字符串结束,则退出函数
if (c == )
return;
// 如果c是-,则应该是一个选项
if (c == '-')
{
i++;
// 读取出-后面的字符,并做判断
read:
c = commandStr[i];
// 如果-后面是c,就将_c置为true
if (c == 'c')
{
cur->_c = true;
if (commandStr[++i] != ' ')
{
goto read;
}
continue;
}
// 如果-后面是w,就将_w置为true
else if (c == 'w')
{
cur->_w = true;
if (commandStr[++i] != ' ')
{
goto read;
}
continue;
}
// 如果-后面是l,就将_l置为true
else if (c == 'l')
{
cur->_l = true;
if (commandStr[++i] != ' ')
{
goto read;
}
continue;
}
// 如果-后面是o,则后面紧跟的一个参数一定是filePath
// 首先判断后面是否有文件,如果有,就添加
// 如果没有,就报错
// 此时i的index是在选项上的
else if (c == 'o')
{
i += ; // 将i移动到
char next = commandStr[i];
if (next == '-' || next == '')
{
printf("after -o must a para\n");
exit(-);
}
char path[] = ""; // 用来存放输出路径
for (int j = ;; j++)
{
// 读取出命令中的文件名中的每一个字符
char ch = commandStr[i++]; // 如果读取到了0,就说明文件名读取结束,就退出
if (ch == ' ')
{
break;
}
path[j] = ch;
}
memset(outFile, , sizeof(outFile));
strcpy(outFile, path);
}
else
{
// 如果-后面什么都没有,就判定为错误
printf("after - must a para\n");
exit(-);
}
}
else
{
// 如果不是-,则判定为输入文件
// 此时i定位在输入文件的第一个字符上
char path[] = "";
for (int j = ;; j++)
{
char ch = commandStr[i++];
if (ch == ' ')
{
break;
}
path[j] = ch;
}
strcpy(cur->inFile, path);
cur->_hasFile = true;
struct Node *fileNode;
fileNode = (struct Node *)malloc(sizeof(struct Node));
initFileNode(fileNode);
cur->next = fileNode;
cur = fileNode;
i--;
}
}
// 检测是否有输入文件
// if (strlen(cur->inFile) == 0)
// {
// printf("you do not have input file");
// exit(-1);
// }
}
代码分析:该函数是这次作业中最重要的一个函数,因此单独拿出来说一下。
要点说明:
1.使用for循环遍历整个字符串
2.遇到-之后就认为是一个选项,就紧接着读取他的后一个字符,如果是有效参数,就记录在当前文件的结构体中,否则报错
3.如果是-o,则认为后面紧跟着一个输出文件,不做文件名有效性检验,不做权限检查
4.如果是普通字符开头,则认为是输入文件,不做文件名有效性检查,不做权限检查
5.根据规则,输出文件应该放在该文件对应参数的后面
6.遍历完毕之后,就将相关数据都保存在了文件的结构体中,并连接成了链表,返回后可进行后期相关操作。
六.测试设计
根据要求,根据如下条件设计测试:
是否有输入
是否输入-
-后是否有参数
是否统计行数
是否统计字符数
是否统计单词数
是否支持命令连写
是否支持多文件统计
是否有-o
-o后是否跟文件
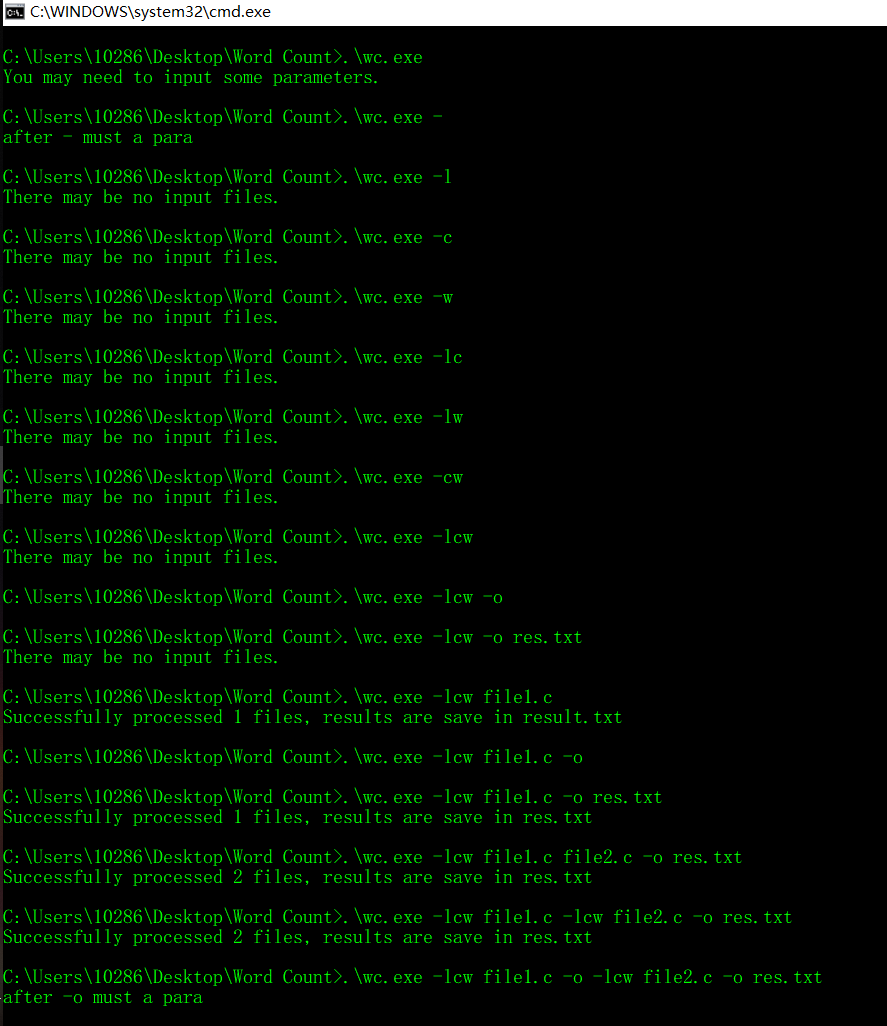
根据以上条件,设计了如下批处理文件:
.\wc.exe
.\wc.exe -
.\wc.exe -l
.\wc.exe -c
.\wc.exe -w
.\wc.exe -lc
.\wc.exe -lw
.\wc.exe -cw
.\wc.exe -lcw
.\wc.exe -lcw -o
.\wc.exe -lcw -o res.txt
.\wc.exe -lcw file1.c
.\wc.exe -lcw file1.c -o
.\wc.exe -lcw file1.c -o res.txt
.\wc.exe -lcw file1.c file2.c -o res.txt
.\wc.exe -lcw file1.c -lcw file2.c -o res.txt
.\wc.exe -lcw file1.c -o -lcw file2.c -o res.txt
PAUSE
测试结果如下:
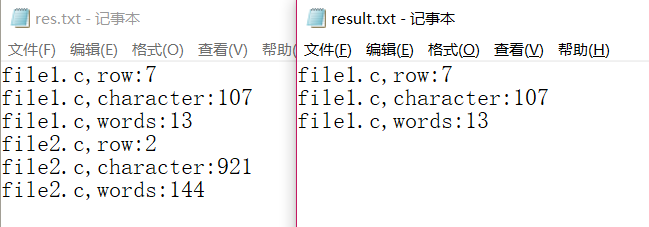
文件输出结果:
七.参考文献
《构建之法--现代软件工程》 --邹新 [第三版]
博客园把我的格式变成了这个样子
(哇的一声就哭出来了)
Word Count作业的更多相关文章
- Java --本地提交MapReduce作业至集群☞实现 Word Count
还是那句话,看别人写的的总是觉得心累,代码一贴,一打包,扔到Hadoop上跑一遍就完事了????写个测试样例程序(MapReduce中的Hello World)还要这么麻烦!!!?,还本地打Jar包, ...
- 个人项目作业-Word Count
个人项目作业 1.Github地址 https://github.com/CLSgGhost/SE_work 2.项目相关需求 wc.exe 是一个常见的工具,它能统计文本文件的字符数.单词数和行数. ...
- 【2016.3.22】作业 Word count 小程序
今天更下word count程序的设计思路及实现方法. 我的程序贴在coding里,这里就先不贴出来了, 我的coding地址:https://coding.net/u/holy_angel/p/wo ...
- Mac下hadoop运行word count的坑
Mac下hadoop运行word count的坑 Word count体现了Map Reduce的经典思想,是分布式计算中中的hello world.然而博主很幸运地遇到了Mac下特有的问题Mkdir ...
- Hive Word count
--https://github.com/slimandslam/pig-hive-wordcount/blob/master/wordcount.hql DROP TABLE myinput; DR ...
- mac上eclipse上运行word count
1.打开eclipse之后,建立wordcount项目 package wordcount; import java.io.IOException; import java.util.StringTo ...
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- Word Count
Word Count 一.个人Gitee地址:https://gitee.com/godcoder979/(该项目完整代码在这里) 二.项目简介: 该项目是一个统计文件字符.单词.行数等数目的应用程序 ...
- [Hive_add_6] Hive 实现 Word Count
0. 说明 Hive 通过 explode()函数 和 split()函数 实现 WordConut 1. Hive 实现 Word Count 方式一 1.1 思路 将每一行文本变为 Array 数 ...
随机推荐
- [SQL]LeetCode178. 分数排名 | Rank Scores
Write a SQL query to rank scores. If there is a tie between two scores, both should have the same ra ...
- [Swift]LeetCode294. 翻转游戏之 II $ Flip Game II
You are playing the following Flip Game with your friend: Given a string that contains only these tw ...
- [Swift]LeetCode802. 找到最终的安全状态 | Find Eventual Safe States
In a directed graph, we start at some node and every turn, walk along a directed edge of the graph. ...
- 封装nodeJS中 $on $emit $off 事件
事件绑定一个事件名称对应多个事件函数 应此它们的关系是一对多的关系 数据类型采用对象的形式 key:val 因为函数有多个 所以val选用数组 事件仓库 eventList = { key:val ...
- BUGKU-逆向(reverse)-writeup
目录 入门逆向 Easy_vb Easy_Re 游戏过关 Timer(阿里CTF) 逆向入门 love LoopAndLoop(阿里CTF) easy-100(LCTF) SafeBox(NJCTF) ...
- 说一说MVC的CustomHandlerErrorAttribute(五)
九月第一篇,呵呵 前言:最近刚入职了一家公司,上司让我维护一个项目,我接手了看了一下项目,try catch 严重影响我的视觉,我直接通过vs插件将其try catch全部替换掉占位符,呵呵. 所以我 ...
- https和http共存的nginx简单配置
server{ listen 80; listen 443 ssl; ssl_certificate /usr/local/nginx/ssl/www.demo.com/www.demo.com.cn ...
- Hystrix是如何工作的
接上一篇:<Hystrix介绍> 流程图 下面这幅图相当重要 稍微解释一下上面的流程: Construct a HystrixCommand or HystrixObservableCom ...
- Android Hybrid App自动化测试实战讲解(基于python)
1.Hybrid App自动化测试概要 什么是Hybrid App? Hybrid App(混合模式移动应用)是指介于web-app.native-app这两者之间的app,兼具“Native App ...
- 前端笔记之JavaScript(十二)缓冲公式&检测设备&Data日期
一.JavaScript缓冲公式ease 原生JS没有自己的缓冲公式,但是你要自己推理的话,必须要懂一些数学和物理公式: 让div用100毫秒(帧),从left100px的位置变化到left800px ...