python 数据分析算法(决策树)
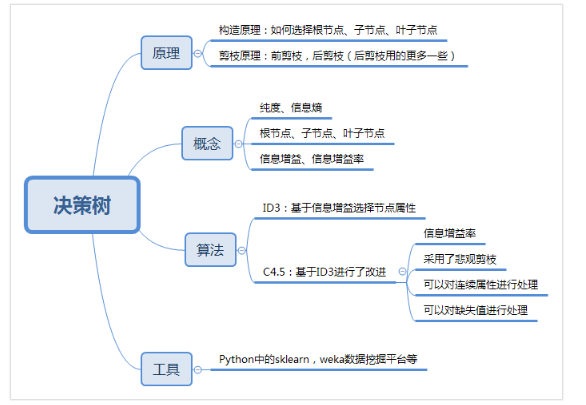
决策树基于时间的各个判断条件,由各个节点组成,类似一颗树从树的顶端,然后分支,再分支,每个节点由响的因素组成
决策树有两个阶段,构造和剪枝
构造: 构造的过程就是选择什么属性作为节点构造,通常有三种节点
1. 根节点:就是树的最顶端,最开始那个节点 (选择哪些属性作为根节点)
2. 内部节点: 就是树中间的那些节点 (选择哪些属性作为子节点)
3. 叶节点: 就是树最底部的节点,也就是决策的结果(什么时候停止并得到目标状态,叶节点)
剪枝: 实现不需要太多的判断,同样可以得到不错的结果,防止过拟合现象发生
过拟合百度百科直观了解一下(https://baike.baidu.com/item/%E8%BF%87%E6%8B%9F%E5%90%88/3359778)
简单介绍就是为了得到一致假设而使假设变得过度严格称为过拟合。
预剪枝是在决策树构造前进行剪枝,在构造过程中对节点进行评估,如果某个节点的划分,在验证集中不能带来准确性的提升,划分则无意义当成叶节点不做划分
后剪枝是在生成决策树后再进行剪枝,通常会从决策树的叶节点开始,逐层向上对每个节点进行评估,减掉与保留差准确性差别不大,或者减掉改节点字数,能在验证集中带来准确性提升,就可以剪枝。
信息熵: 表示了信息的不确定度,下面是计算公式,信息熵越大纯度越低
当不确定性越大,包含的信息量就越大,信息熵就越高
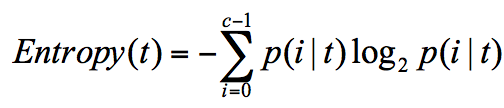
信息增益:ID3 算法 指划分可以带来纯度的提高,信息熵的下降,父节点的信息熵减去所有子节点的信息熵,计算过程中,会计算子节点归一化的信心上 下面是计算公式
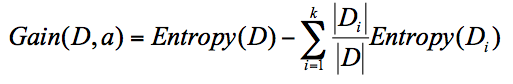
公式中D是父亲节点,Di 是子节点,Gain(D,a) 中的a作为D节点的属性选择
归一化子节点的信息熵,就是公式中的Di/D 信息增益最大可以作为父亲节点,再重复进行判断到最后得出几轮
C4.5算法
1 采用信息增益率 信息增益率 = 信息增益/属性熵 信息增益的同事,属性熵也会变大
2 采用悲观剪枝 ID3 中容易产生过拟合现象, 这个方法可以提升决策树的泛华能力,属于后剪枝的一种,比较剪枝前后这个节点的分类错误率来觉得是否对其进行剪枝
3 离散化处理连续属性 C4.5可以处理连续属性的情况,对连续属性进行离散化处理,就是对值进行计算,而不是分为几等分(高,中,底) C4.5 选择具有最高信息增益的划分所对应的阈值
4 处理缺失值 C4.5 也可以处理,假如数据集存在较少的缺失值, 对子节点归一化计算信息增益,然后计算信息增益率,由于有对应的缺失值,所以信息增益率*占权比重,(比如7个数据,少了一个*6/7)所以在属性确实的情况下也可以计算信息增益
ID3和C4.5比较, ID3算法简单,确定是对噪声敏感,少量错误会产生决策树的错误,C4.5 进行了改进,长上面可以看出,但是C4.5 需要对数据集进行多次扫描,算法效率相对较低
python 数据分析算法(决策树)的更多相关文章
- python数据分析算法(决策树2)CART算法
CART(Classification And Regression Tree),分类回归树,,决策树可以分为ID3算法,C4.5算法,和CART算法.ID3算法,C4.5算法可以生成二叉树或者多叉树 ...
- Python机器学习算法 — 决策树(Decision Tree)
决策树 -- 简介 决策树(decision tree)一般都是自上而下的来生成的.每个决策或事件(即自然状态)都可能引出两个或多个事件,导致不同的结果,把这种决策分支画成图形很像一棵 ...
- Python数据挖掘之决策树DTC数据分析及鸢尾数据集分析
Python数据挖掘之决策树DTC数据分析及鸢尾数据集分析 今天主要讲述的内容是关于决策树的知识,主要包括以下内容:1.分类及决策树算法介绍2.鸢尾花卉数据集介绍3.决策树实现鸢尾数据集分析.希望这篇 ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- Python数据分析【炼数成金15周完整课程】
点击了解更多Python课程>>> Python数据分析[炼数成金15周完整课程] 课程简介: Python是一种面向对象.直译式计算机程序设计语言.也是一种功能强大而完善的通用型语 ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- 《Python数据分析与挖掘实战》读书笔记
大致扫了一遍,具体的代码基本都没看了,毕竟我还不懂python,并且在手机端的排版,这些代码没法看. 有收获,至少了解到以下几点: 一. Python的语法挺有意思的 有一些类似于JavaSc ...
- (python数据分析)第03章 Python的数据结构、函数和文件
本章讨论Python的内置功能,这些功能本书会用到很多.虽然扩展库,比如pandas和Numpy,使处理大数据集很方便,但它们是和Python的内置数据处理工具一同使用的. 我们会从Python最基础 ...
- python数据分析系列(1)
目录 python基础 python语言基础 Ipython的一些特性 Python语法基础 Python控制流 lambda表达式 Python的数据结构 元组 列表 字典 集合 列表.集合.字典推 ...
随机推荐
- 【剑指offer】【python】面试题2~5
使用python实现<剑指offer>面试题ヾ(◍°∇°◍)ノ゙,以此记录. 2_实现Singleton模式 题目:实现单例模式 单例模式,是一种常用的软件设计模式.在它的核心结构中只包含 ...
- 【原创】大数据基础之Marathon(1)简介、安装、使用
marathon 1.6.322 官方:https://mesosphere.github.io/marathon/ 一 简介 Marathon is a production-grade conta ...
- 转载:.Net 程序集 签名工具sn.exe 密钥对SNK文件 最基本的用法
.Net 程序集 签名工具sn.exe 密钥对SNK文件 最基本的用法 阐述签名工具这个概念之前,我先说说它不是什么: 1.它不是用于给程序集加密的工具,它与阻止Reflector或ILSpy对程序集 ...
- canvas图片与img图片的相互转换
最近在一个项目中,遇到了一个问题,需要把生成的canvas形式的二维码转换为图片,可以长按识别,保存等.查找了一些资料归纳总结了一些知识. 默认在jq库里进行,引入jquery.qrcode.min. ...
- djjango安装及其 操作命令
一 首先掌握HTTP协议 HTTP四大特性: 1 基于tcp/IP作用在应用层之上的协议 2 基于请求响应 3 无状态(不识别来的用户的状态) 4 无连接(请求完返回响应后就断开) 数据格式: 请求 ...
- 论文阅读笔记四十六:Feature Selective Anchor-Free Module for Single-Shot Object Detection(CVPR2019)
论文原址:https://arxiv.org/abs/1903.00621 摘要 本文提出了基于无anchor机制的特征选择模块,是一个简单高效的单阶段组件,其可以结合特征金字塔嵌入到单阶段检测器中. ...
- vmware安装centOs操作系统配置网络的一系列问题
1:最近公司在测试项目,需要在linux操作系统上面测试,可惜自己之前学linux操作系统不是很深,配置网络也不是很熟练,网上方法太多,但是不是很好用,确实难为了自己一把,在这里自己总结一下配置网络的 ...
- Python实现简单的HttpServer
要写一个类似tomcat的简易服务器,首先需弄清楚这几点: 1. 客户端(Client)和服务端(Server)的角色及作用 角色A向角色B请求数据,这时可以把A视为客户端,B视为服务端.客户端的主要 ...
- Git基本操作指令
Git是世界上目前最先进的分布式版本控制系统. 工作原理图: Workspace工作区,Index暂存区,Repository本地仓库区,Remote远程仓库. SVN与Git的最主要的区别? SVN ...
- jsp填坑:找不到属性
javax.el.PropertyNotFoundException: Property [***] not found on type 接手的项目的页面是用jsp写的,虽然再有十几天就2019年了, ...