Scrapy架构概述
Scrapy架构概述
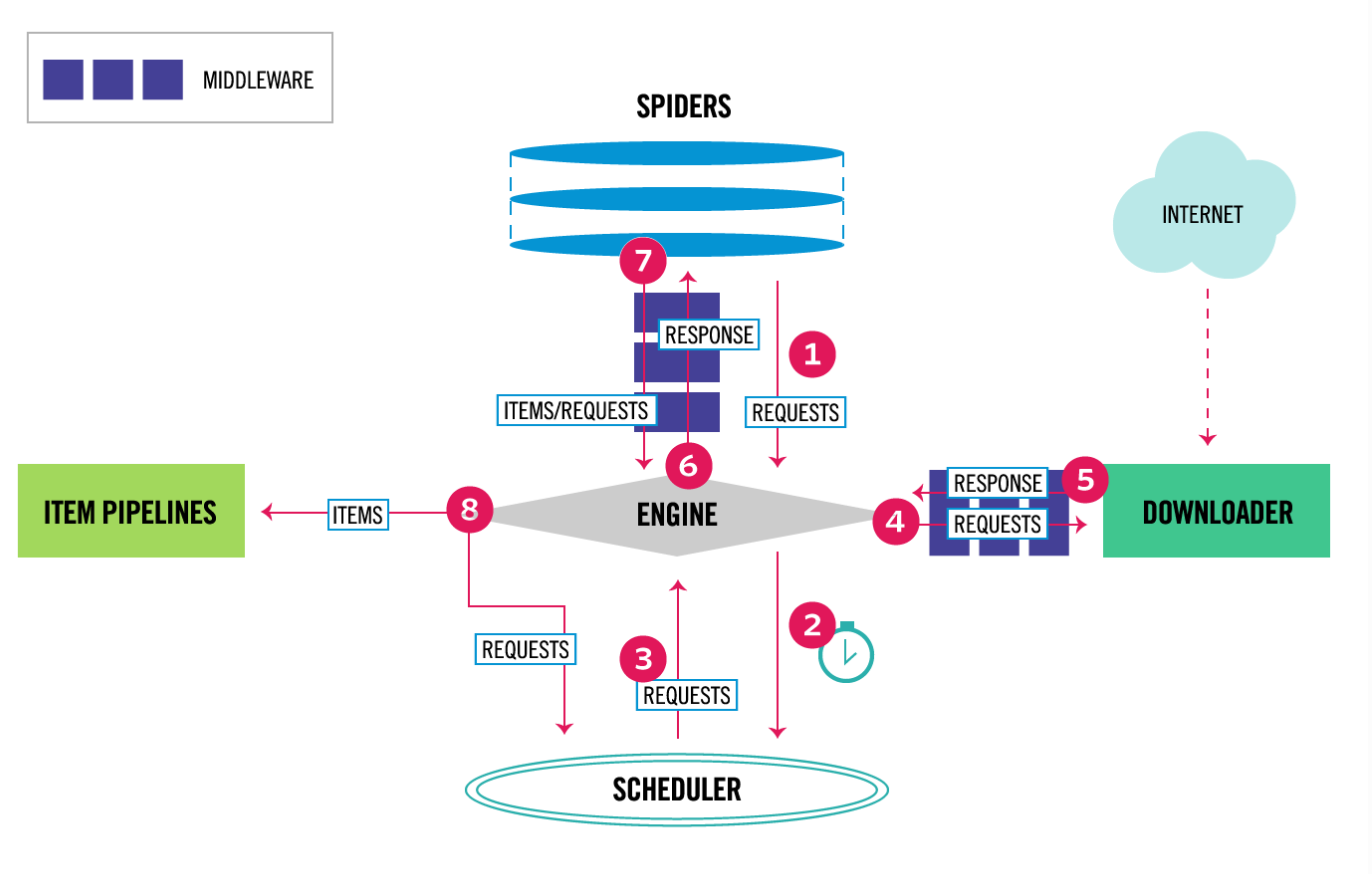
1, 从最初自己编写的spiders,获取到start_url,并且封装成Request对象。
2,通过engine(引擎)调度给SCHEDULER(Requests管理调度器)。
3,SCHEDULER管理ENGINE传递过来的所有Requests,通过优先级,传递给ENGINE。
4,ENGINE 将传递过来的Request对象传递给Downloader(下载器),但是在传递之间会通过MiddleWare(中间件)对Requests进行包装,添加头部,代理IP之类的。
5,Downloader(下载器)将包装好的Requests进行下载,并将下载后的Response对象传递给Engin。
6,Engin将Response对象传递给自己编码的Spider,但是中间仍有对于Response加工的中间件,在spider中通过自己编写的规则对内容进行提取。
7,提取完成后会产生两种对象,一个是自己想要的数据,存储在Item中;另一个是想要继续爬取的URL,包装成Request一并传递给Engine
8,Engine获取到 7 传递过来的Item,将其传递给ItemPipelines(Item管道,将Item中数据写入存储);获取到 7 传递来的Requests对象,跟之前一样,交给SCHEDULER进行管理调度
9,SCHEDULER中没有Requests对象需要下载时,爬虫关闭。
Scrapy架构概述的更多相关文章
- Python -- Scrapy 架构概览
架构概览 本文档介绍了Scrapy架构及其组件之间的交互. 概述 接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示). 下面对每个组件都做了简单介绍,并给出了详 ...
- 老李推荐: 第14章2节《MonkeyRunner源码剖析》 HierarchyViewer实现原理-HierarchyViewer架构概述
老李推荐: 第14章2节<MonkeyRunner源码剖析> HierarchyViewer实现原理-HierarchyViewer架构概述 HierarchyViewer库的引入让M ...
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- MySQL逻辑架构概述
1.MySQL逻辑架构 MySQL逻辑架构图 MySQL逻辑架构分四层 1.连接层:主要完成一些类似连接处理,授权认证及相关的安全方案. 2.服务层:在 MySQL据库系统处理底层数据之前的所有工作都 ...
- scrapy架构简介
一.scrapy架构介绍 1.结构简图: 主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine ...
- 大型互联网架构概述 关于架构的架构目标 典型实现 DNS CDN LB WEB APP SOA MQ CACHE STORAGE
大型互联网架构概述 目录 架构目标 典型实现 DNS CDN LB WEB APP SOA MQ CACHE STORAGE 本文旨在简单介绍大型互联网的架构和核心组件实现原理. 理论上讲,从安装配置 ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- Tornado之架构概述图
一.Tornado之架构概述图 二.Application类详细分析: #!/usr/bin/env python # -*- coding: utf8 -*- # __Author: "S ...
随机推荐
- Python利用pandas处理Excel数据的应用
Python利用pandas处理Excel数据的应用 最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做 ...
- L1-Day9
1.学习让我感觉很棒.(什么关系?动作 or 描述?主语部分是?) [我的翻译]Learning makes me that feel good. [标准答案]Lear ...
- [Kubernetes] CRI 的设计与工作原理
咱们来看看,有了 CRI 之后, Kubernetes 的架构图: 我们可以看到, CRI 机制能够发挥作用的核心,在于每一个容器项目现在都可以自己实现一个 CRI shim ,自行对 CRI 请求进 ...
- pwnable.tw start&orw
emm,之前一直想做tw的pwnable苦于没有小飞机(,今天做了一下发现都是比较硬核的pwn题目,对于我这种刚入门?的菜鸡来说可能难度刚好(orz 1.start 比较简单的一个栈溢出,给出一个li ...
- GIt -- fatal: refusing to merge unrelated histories 问题处理
今晚碰到这个问题-- fatal: refusing to merge unrelated histories 想了一下,为什么就这样了? 因为我是先本地创建了仓库,并添加了文件,然后再到github ...
- C# 登陆验证码工具类VerifyCode
using System; using System.Collections.Generic; using System.Drawing; using System.Drawing.Imaging; ...
- Android真机测试,连接到本地服务器的方法
1. 前言 作为一名Android开发者,不管怎么说,都会经历使用Android真机来测试连接本地服务器这样的事情.这里所说的“本地服务器”大多数时候指的是:搭载有某种服务器软件的PC,例如搭载有To ...
- sql查找某一列中某一数值出现次数大于3的记录的前3条
SELECT * FROM table GROUP BY column HAVING COUNT(column)>=3 ORDER BY column DESC LIMIT 0,3;
- ef core自动映射
原回答:https://stackoverflow.com/questions/26957519/ef-core-mapping-entitytypeconfiguration 一.反射 protec ...
- Core 2.0使用Nlog记录日志+Mysql
一.先创建一个Core2.0的项目,并在NuGet中引入3个类库文件 MySql.Data.dll NLog.dll NLog.Web.AspNetCore.dll 二.创建一个nlog.config ...