初识spark的MLP模型
初识Spark的MLP模型
1. MLP介绍
Multi-layer Perceptron(MLP),即多层感知器,是一个前馈式的、具有监督的人工神经网络结构。通过多层感知器可包含多个隐藏层,实现对非线性数据的分类建模。MLP将数据分为训练集、测试集、检验集。其中,训练集用来拟合网络的参数,测试集防止训练过度,检验集用来评估网络的效果,并应用于总样本集。当因变量是分类型的数值,MLP神经网络则根据所输入的数据,将记录划分为最适合类型。常被MLP用来进行学习的反向传播算法,在模式识别的领域中算是标准监督学习算法,并在计算神经学及并行分布式处理领域中,持续成为被研究的课题。MLP已被证明是一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题。
2. 使用Java进行开发
2.1开发环境准备
- 基本Java开发环境
Eclipse,Maven,Jdk1.7
- spark开发需要环境
Windows操作系统保存训练模型必须要依赖于hadoop-common-2.2.0-bin-master,如果不保存模型不需要配置此环境,linux操作系统不需要配置此环境。
配置此环境有以下两种方法:
- 直接在代码最开始写
System.setProperty("hadoop.home.dir", "D:\\Programe\\hadoop-common-2.2.0-bin-master");
- 配置入环境变量
直接在Windows的系统变量里面配置HADOOP_HOME,然后在PATH里面配置HADOOP_HOME/bin
2.2项目搭建
- 创建简单的maven项目
- 在pom下增加下列jar
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.3</version>
<scope>runtime</scope>
</dependency>
注意:本例使用jdk1.7,spark2.2.x要求jdk1.8。
2.3官网实例
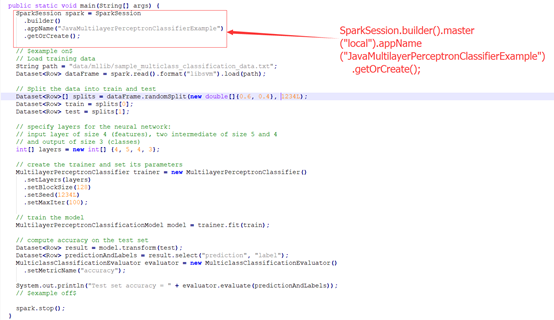
注意:创建SparkSession时添加.master(“local”)
2.4保存训练模型
上例是直接使用数据训练模型之后进行预测,大多数情况是模型只需训练一次,之后就可以直接使用,于是Spark提供了保存模型的方法。
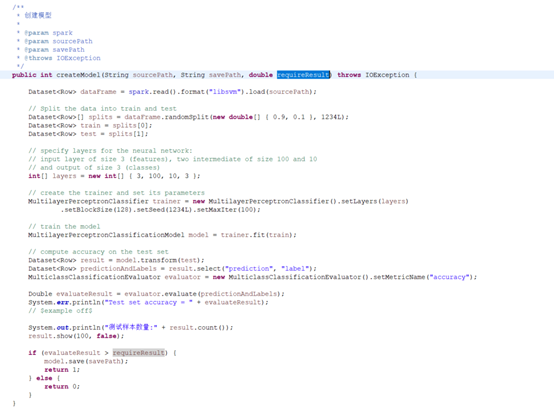
2.5获取训练模型

2.6其他相关知识
- Java类型数据转换为Spark数据类型
略
- 如何从word生成Spark可加载的libsvm的文档
略
3. 参考文档
hadoop-common-2.2.0-bin-master下载地址
https://github.com/srccodes/hadoop-common-2.2.0-bin
Spark的MPL例子官网地址(2.4.0版本与本文版本不一样,但是没有影响)
代码例子官网地址(2.4.0版本与本文版本不一样,但是没有影响)
https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples
初识spark的MLP模型的更多相关文章
- Spark—初识spark
Spark--初识spark 一.Spark背景 1)MapReduce局限性 <1>仅支持Map和Reduce两种操作,提供给用户的只有这两种操作 <2>处理效率低效 Map ...
- 初识Spark(Spark系列)
1.Spark Spark是继Hadoop之后,另外一种开源的高效大数据处理引擎,目前已提交为apach顶级项目. 效率: 据官方网站介绍,Spark是Hadoop运行效率的10-100倍(随内存计算 ...
- Spark之编程模型RDD
前言:Spark编程模型两个主要抽象,一个是弹性分布式数据集RDD,它是一种特殊集合,支持多种数据源,可支持并行计算,可缓存:另一个是两种共享变量,支持并行计算的广播变量和累加器. 1.RDD介绍 S ...
- Spark分布式计算执行模型
引言 相对Hadoop, Spark在处理需要迭代运算的机器学习训练等任务上有着很大性能提升,同时提供了批处理.实时数据处理.机器学习以及图算法等一站式的服务,因此最近大家一起来学习Spark,特别是 ...
- Spark2.1.0之初识Spark
随着近十年互联网的迅猛发展,越来越多的人融入了互联网——利用搜索引擎查询词条或问题:社交圈子从现实搬到了Facebook.Twitter.微信等社交平台上:女孩子们现在少了逛街,多了在各大电商平台上的 ...
- Spark 决策树--回归模型
package Spark_MLlib import org.apache.spark.ml.Pipeline import org.apache.spark.ml.evaluation.Regres ...
- Spark 决策树--分类模型
package Spark_MLlib import org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.{D ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- 带你初识Angular中MVC模型
简介 MVC是一种使用 MVC(Model View Controller 模型-视图-控制器)设计模式,该模型的理念也被许多框架所吸纳,比如,后端框架(Struts.Spring MVC等).前端框 ...
随机推荐
- JAX-RS和 Spring 整合开发
JAX-RS 和 和 Spring 整合开发 1.建立maven项目 2.导入maven坐标 <dependencies> <!-- cxf 进行rs开发 必须导入 --> & ...
- Docker技术应用场景(转载)
场景一:节省项目环境部署时间 1.单项目打包 每次部署项目到测试.生产等环境,都要部署一大堆依赖的软件.工具,而且部署期间出现问题几率很大,不经意就花费了很长时间. Docker主要理念就是环境打包部 ...
- list<T>升序、降序
List<test> list = new List<test> (); var result = list.OrderByDescending(p => p.we).T ...
- ios 信任charles https 证书
https://www.charlesproxy.com/documentation/using-charles/ssl-certificates/ https://support.apple.com ...
- 设计在canal中的运用,看到随手记下
观察者模式,定义添加修改删除对应的操作 系统很多Monitor/Listener都是类似 Monitor内含listener,调用再触发 public synchronized void start( ...
- 【译】图解Transformer
目录 从宏观上看Transformer 把张量画出来 开始编码! 从宏观上看自注意力 自注意力的细节 自注意力的矩阵计算 "多头"自注意力 用位置编码表示序列的顺序 残差 解码器 ...
- Namenode启动报错Operation category JOURNAL is not supported in state standby
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category JO ...
- 微信小程序:request合法域名检验出错,https://apis.map.qq.com 不在以下 request 合法域名列表中
设置域名 登录微信小程序后台, 设置→开发设置→服务器设置 必须设置域名,微信小程序才能进行网络通讯,不然会报错 如果没有设置合法域名,在开发阶段是可以不设置合法域名的 详情 -项目设置 好了,完美解 ...
- Pandas分组级运算和转换
分组级运算和转换 假设要添加一列的各索引分组平均值 第一种方法 import pandas as pd from pandas import Series import numpy as np df ...
- Python学习—数据库篇之索引
一.索引简介 索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构.类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可,对于索引,会保存在额外的文件中.在mys ...