CatBoost算法原理及Python实现
一、概述
CatBoost 是在传统GBDT基础上改进和优化的一种算法,由俄罗斯 Yandex 公司开发,于2017 年开源,在处理类别型特征和防止过拟合方面有独特优势。
在实际数据中,存在大量的类别型特征,如性别、颜色、类别等,传统的算法通常需要在预处理中对这些特征进行独热编码(One-Hot Encoding)或标签编码(Label Encoding)。但这些方法存在一些问题,独热编码会增加数据的维度,导致模型训练时间变长;标签编码可能会引入不必要的顺序关系,影响模型的准确性。CatBoost 采用了一种独特的处理方式,称为 “Ordered Target Statistics”(有序目标统计),它通过对数据进行排序,利用数据的顺序信息来计算类别型特征的统计量,从而将特征有效地融入到模型中,避免了传统编码方式的弊端。
另外,在构建决策树时,CatBoost 采用了对称树的结构,与传统的非对称决策树相比,对称树在生长过程中,每层的节点数量相同,结构更加规整。这种结构使得模型在训练过程中更加稳定,能够减少过拟合的风险,同时也有助于提高训练速度。
二、算法原理
1.对称树结构
对称树结构在形式上是完全二叉树结构,是指在构建决策树时,对于每个节点的分裂,都考虑所有可能的特征和阈值组合,并且在树的同一层中,所有节点的分裂方式是对称的。具体可描述为
特征选择:在构建对称树时,CatBoost 会对所有可用的特征进行评估,计算每个特征对于目标变量的重要性。通过一些统计指标,如信息增益、基尼系数等,来衡量特征对数据划分的有效性,选择具有最高重要性的特征作为当前节点的分裂特征。
阈值确定:对于选定的分裂特征,CatBoost 会遍历该特征的所有可能取值,寻找一个最优的分裂阈值,使得分裂后的两个子节点能够最大程度地分离不同类别的数据,或者使目标变量在两个子节点上的分布具有最大的差异。
对称分裂:一旦确定了分裂特征和阈值,就在当前节点上按照这个特征和阈值进行分裂,将数据集分为左右两个子节点。在树的同一层中,所有节点都按照相同的特征选择和阈值确定方法进行分裂,形成对称的树结构。
2.训练过程
(1) 初始化弱学习器
首先,初始化一个弱学习器,通常是一个决策树(是否对称树结构均可),记为\(f_0(X)\),其预测结果为初始的预测值\(\hat y_0\)。此时,初始预测值与真实值之间存在误差。
(2) 计算残差或负梯度
在回归任务中,计算每个样本的残差,即真实值\(y_i\)与当前模型预测值\(\hat y_{i,t-1}\)的差值\(r_{i,t}=y_i-\hat y_{i,t-1}\),其中表示迭代的轮数。在分类任务中,计算损失函数关于当前模型预测值的负梯度
\]
(3) 构建决策树
使用计算得到的残差(回归任务)或负梯度(分类任务)作为新的目标值,使用“对称树结构” 的方式来构建一棵新的决策树\(f_t(X)\)。同时采用一些限制决策树深度、控制叶子节点数量的正则化技术。
(4) 更新模型
根据新训练的决策树,更新当前模型。更新公式为\(\hat y_{i,t}=\hat y_{i,t-1}+\alpha f_t(x_i)\),其中是学习率(也称为步长),用于控制每棵树对模型更新的贡献程度。学习率较小可以使模型训练更加稳定,但需要更多的迭代次数;学习率较大则可能导致模型收敛过快,甚至无法收敛。
(5) 重复迭代
重复步骤 (2)–(4)步,不断训练新的决策树并更新模型,直到达到预设的迭代次数、损失函数收敛到一定程度或满足其他停止条件为止。最终,CatBoost模型由多棵决策树组成,其预测结果是所有决策树预测结果的累加。
过程示意图
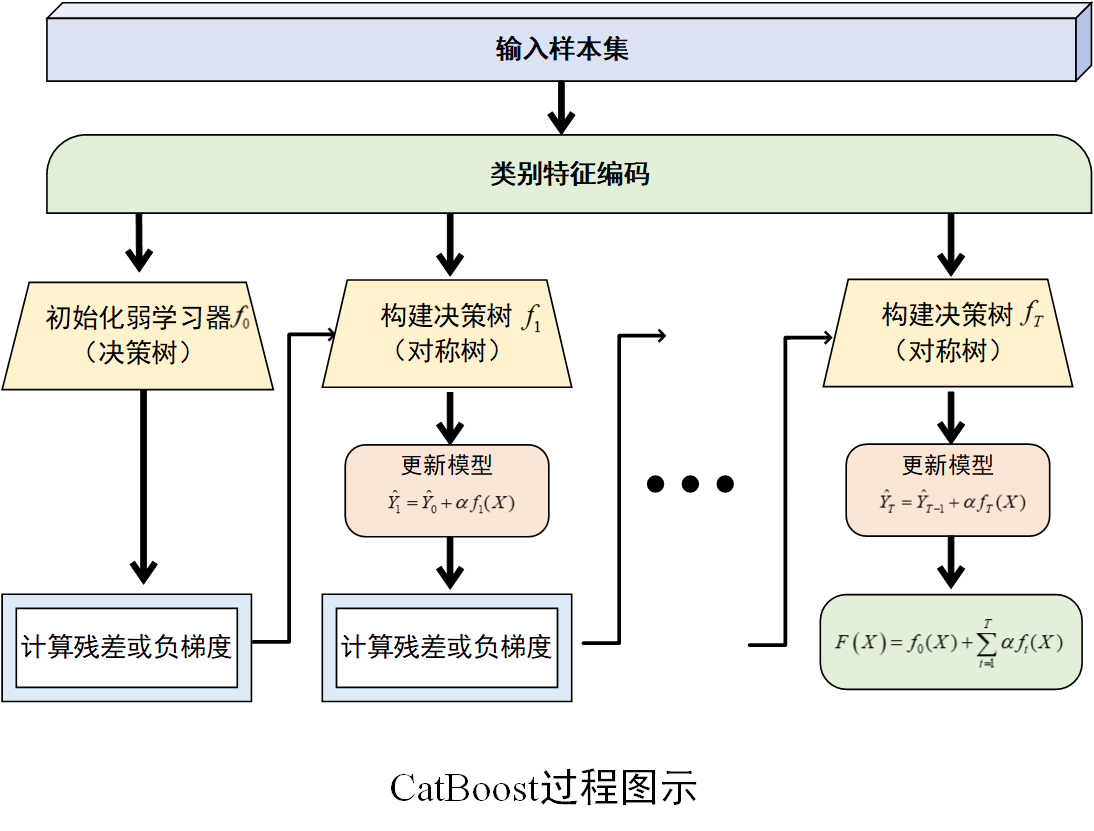
三、应用场景
1. 结构化数据预测
在金融领域,CatBoost 可以用于信用评估、风险预测等任务。通过分析客户的各种属性(如年龄、收入、信用记录等分类和数值特征),预测客户的信用等级和违约风险,帮助金融机构做出更准确的决策。在电商领域,它可以用于商品推荐、销售预测等。根据用户的购买历史、浏览行为等特征,预测用户对不同商品的兴趣,为用户提供个性化的推荐服务,同时也可以帮助商家预测商品的销量,合理安排库存。
2.时间序列分析
CatBoost 在时间序列预测方面也有一定的应用。它可以处理具有复杂模式和趋势的时间序列数据,如股票价格预测、能源消耗预测等。通过提取时间序列中的各种特征(如趋势、季节性、周期性等),结合其他相关的影响因素,构建预测模型,为决策提供支持。
3.图像和文本数据的辅助分析
虽然 CatBoost 主要适用于结构化数据,但在一些情况下,它也可以与其他深度学习算法结合,用于图像和文本数据的辅助分析。例如,在图像分类任务中,可以先使用深度学习模型提取图像的特征,然后将这些特征与其他相关的结构化数据(如拍摄时间、地点等)一起输入到 CatBoost 模型中,进行进一步的分类和预测。
四、Python实现
(环境:Python 3.11,scikit-learn 1.6.1)
分类情形
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import catboost as cb
from sklearn import metrics
# 生成数据集
X, y = make_classification(n_samples = 1000, n_features = 6, random_state = 42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# 创建CatBoost分类模型
model = cb.CatBoostClassifier()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pre = model.predict(X_test)
# 性能评价
accuracy = metrics.accuracy_score(y_test,y_pre)
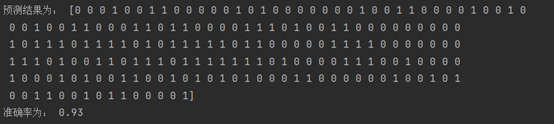
print('预测结果为:',y_pre)
print('准确率为:',accuracy)
回归情形
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
import catboost as cb
from sklearn.metrics import mean_squared_error
# 生成数据集
X, y = make_regression(n_samples = 1000, n_features = 6, random_state = 42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# 创建CatBoost回归模型
model = cb.CatBoostRegressor()
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 计算均方误差评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差: {mse}")

五、小结
CatBoost 算法凭借其独特的算法原理和核心特点,在机器学习领域中占据了一席之地。它在处理类别型特征、防止过拟合、训练速度和易用性等方面都表现出色,适用于多种应用场景。无论是在结构化数据预测、时间序列分析还是与其他类型数据的结合应用中,CatBoost 都展现出了强大的能力。随着数据科学的发展,CatBoost 可逐渐在更多领域得到应用,为解决实际问题提供更多有效的帮助。
End.
CatBoost算法原理及Python实现的更多相关文章
- 深入学习主成分分析(PCA)算法原理(Python实现)
一:引入问题 首先看一个表格,下表是某些学生的语文,数学,物理,化学成绩统计: 首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系,那么如何判断三个学生的优秀程度呢?首先我们一眼 ...
- softmax分类算法原理(用python实现)
逻辑回归神经网络实现手写数字识别 如果更习惯看Jupyter的形式,请戳Gitthub_逻辑回归softmax神经网络实现手写数字识别.ipynb 1 - 导入模块 import numpy as n ...
- KNN算法原理(python代码实现)
kNN(k-nearest neighbor algorithm)算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性 ...
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- PageRank算法原理与Python实现
一.什么是pagerank PageRank的Page可是认为是网页,表示网页排名,也可以认为是Larry Page(google 产品经理),因为他是这个算法的发明者之一,还是google CEO( ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- 【机器学习实战学习笔记(1-1)】k-近邻算法原理及python实现
笔者本人是个初入机器学习的小白,主要是想把学习过程中的大概知识和自己的一些经验写下来跟大家分享,也可以加强自己的记忆,有不足的地方还望小伙伴们批评指正,点赞评论走起来~ 文章目录 1.k-近邻算法概述 ...
- BP算法从原理到python实现
BP算法从原理到实践 反向传播算法Backpropagation的python实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 博主接触深度学习已经一段时间,近期在与别人进行讨论时,发现自 ...
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python) http://blog.csdn.net/liulingyuan6/article/details ...
- 模拟退火算法SA原理及python、java、php、c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径
模拟退火算法SA原理及python.java.php.c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径 模拟退火算法(Simulated Annealing,SA)最早的思 ...
随机推荐
- 在Windows系统中安装Open WebUI并连接Ollama
一.Open WebUI简介与安装前准备 Open WebUI是一个开源的大语言模型(LLM)交互界面,支持本地部署与离线运行.通过它,用户可以在类似ChatGPT的网页界面中,直接操作本地运行的Ol ...
- 2025AI应用元年,DeepSeek让领域小模型训练成本急剧下降!
关注公众号回复1 获取一线.总监.高管<管理秘籍> 模型训练俗称炼丹,而炼丹是修士特权,这就显得模型训练离普通人很远了. 虽然是笑谈,但如果对其中情况不太了解确实也会因为其背后深厚.复杂的 ...
- autMan奥特曼机器人-跳过注册页面直接进入登陆页面
1.将下面4行内容存成txt文件[注意将"账号"和"密码"等字眼替换为自己的真正账号和密码],文件名改成sets.conf,放到autman主文件夹,见下图最下 ...
- Idea - 关于mybatis的插件
idea中配置的mybatis的mapper类和xml文件的图标怎么自动变为mybatis的logo?需要安装什么插件,怎么安装? 在 IntelliJ IDEA 中,要使 MyBatis 的 ...
- 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
2025年2月25日,.NET团队在博客上宣布了.NET 10 Preview 1的正式发布,文章参见:https://devblogs.microsoft.com/dotnet/dotnet-10- ...
- 【插件介绍】Mesh2Geom插件
Mesh to Geometry Plugin,来自达索官方论坛社区 原帖链接:Mesh to Geometry Plugin plugin feature: 允许Abaqus 用户从网格文件生成几何 ...
- 值得推荐的IT公司名单(国企篇)
大家好,今天我们来盘点一下值得推荐的国企,这些企业在行业内具有举足轻重的地位,不仅主营业务突出,福利待遇优厚,尤其是研发岗位的薪资区间,更是让人眼前一亮. 十大顶尖央企国企,待遇优厚如天花板级别!(排 ...
- Web前端入门第 6 问:HTML 的基础语法结构
HTML的全称为超文本标记语言(HyperText Markup Language),基础语法结构由标签.元素.属性和内容组成,遵循层级嵌套的树形结构. 关键语法规则 标签(Tags) 双标签语法 标 ...
- Golang 入门 : 语言环境安装
下载介绍 在go的官方网址上下载go最新版本https://golang.google.cn/dl/,或者在 Go 的中文网上下载https://studygolang.com/dl,两个网站打开的内 ...
- Windows 提权-服务_弱服务权限
本文通过 Google 翻译 Weak Service Permissions – Windows Privilege Escalation 这篇文章所产生,本人仅是对机器翻译中部分表达别扭的字词进行 ...