scrapy入门二(分页抓取文章入库)
分页抓取博客园新闻,先从列表里分析下一页按钮
相关代码:
# -*- coding: utf-8 -*-
import scrapy from cnblogs.items import ArticleItem class BlogsSpider(scrapy.Spider):
name = 'blogs'
allowed_domains = ['news.cnblogs.com']
start_urls = ['https://news.cnblogs.com/'] def parse(self, response):
articleList=response.css('.content') for item in articleList:
# 由于详情页里浏览次数是js动态加载的,无法获取,这里需要传递过去
viewcount = item.css('.view::text').extract_first()[:-3].strip()
detailurl = item.css('.news_entry a::attr(href)').extract_first()
detailurl = response.urljoin(detailurl)
yield scrapy.Request(url=detailurl, callback=self.parse_detail, meta={"viewcount": viewcount})
#获取下一页标签
text=response.css('#sideleft > div.pager > a:last-child::text').extract_first().strip()
if text=='Next >':
next = response.css('#sideleft > div.pager > a:last-child::attr(href)').extract_first()
url=response.urljoin(next) yield scrapy.Request(url=url,callback=self.parse) ##解析详情页内容
def parse_detail(self, response):
article=ArticleItem()
article['linkurl']=response.url
article['title']=response.css('#news_title a::text').extract_first()
article['img'] = response.css('#news_content img::attr(src)').extract_first("default.png")
article['source'] = response.css('.news_poster ::text').extract_first().strip()
article['releasetime'] = response.css('.time::text').extract_first()[3:].strip()
article['viewcount']= response.meta["viewcount"]
article['content']=response.css('#news_body').extract_first("") yield article
写入数据库,先在setting.py页面配置mongo连接数据信息
ROBOTSTXT_OBEY = True
MONGODB_HOST='localhost'
MONGO_PORT=27017
MONGO_DBNAME='cnblogs'
MONGO_DOCNAME='article'
修改pipelines.py页面,相关代码
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.conf import settings
from cnblogs.items import ArticleItem
class CnblogsPipeline(object):
#初始化信息
def __init__(self): host = settings['MONGODB_HOST']
port = settings['MONGO_PORT']
db_name = settings['MONGO_DBNAME']
client = pymongo.MongoClient(host=host, port=port)
db = client[db_name]
self.post=db[settings['MONGO_DOCNAME']] ##获取值进行入库
def process_item(self, item, spider): article=dict(item)
self.post.insert(article) return item
__init__函数里,获取配置文件里的mongo连接信息,连接mongo库
process_item函数里获取blogs.py里parse里yield返回的每一行,然后将数据入库 最后需要在setting取消注释pipelines.py页面运行的注释,不修改(pipelines.py页面代码可能无法正常调用)
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}
最后在Terminal终端运行命令:scrapy crawl blogs
启用后便会开始进行抓取,结束后打开mongo客户端工具:库和表名创建的都是setting.py里配置的

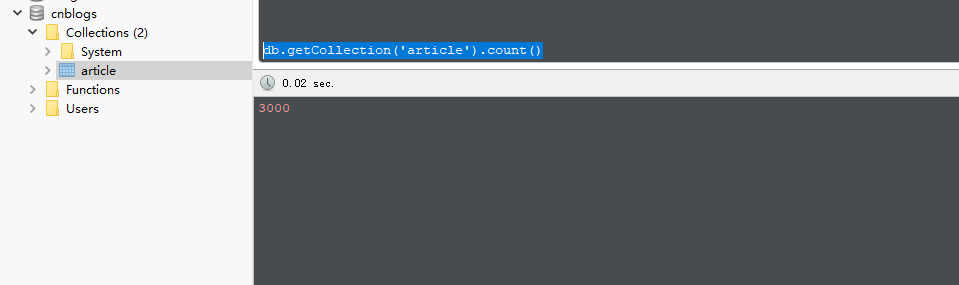
到此,3000条文章资讯数据一条不差的下载下来了
scrapy入门二(分页抓取文章入库)的更多相关文章
- Heritrix源码分析(九) Heritrix的二次抓取以及如何让Heritrix抓取你不想抓取的URL
本博客属原创文章,欢迎转载!转载请务必注明出处:http://guoyunsky.iteye.com/blog/644396 本博客已迁移到本人独立博客: http://www.yun5u ...
- Node.js 爬虫,自动化抓取文章标题和正文
持续进行中... 目标: 动态User-Agent模拟浏览器 √ 支持Proxy设置,避免被服务器端拒绝 √ 支持多核模式,发挥多核CPU性能 √ 支持核内并发模式 √ 自动解码非英文站点,避免乱码出 ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
- 爬虫 - 动态分页抓取 游民星空 的资讯 - bs4
# coding=utf-8 # !/usr/bin/env python ''' author: dangxusheng desc : 动态分页抓取 游民星空 的资讯 date : 2018-08- ...
- python实现一个栏目的分页抓取列表页抓取
python实现一个栏目的分页抓取列表页抓取 #!/usr/bin/env python # coding=utf-8 import requests from bs4 import Beautifu ...
- Scrapy 使用CrawlSpider整站抓取文章内容实现
刚接触Scrapy框架,不是很熟悉,之前用webdriver+selenium实现过头条的抓取,但是感觉对于整站抓取,之前的这种用无GUI的浏览器方式,效率不够高,所以尝试用CrawlSpider来实 ...
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
豆瓣有些电影页面需要登录才能查看. 目录 [隐藏] 1 创建工程 2 定义Item 3 编写爬虫(Spider) 4 存储数据 5 配置文件 6 艺搜参考 创建工程 scrapy startproj ...
- 基于scrapy的分布式爬虫抓取新浪微博个人信息和微博内容存入MySQL
为了学习机器学习深度学习和文本挖掘方面的知识,需要获取一定的数据,新浪微博的大量数据可以作为此次研究历程的对象 一.环境准备 python 2.7 scrapy框架的部署(可以查看上一篇博客的简 ...
- [转]使用Scrapy建立一个网站抓取器
英文原文:Build a Website Crawler based upon Scrapy 标签: Scrapy Python 209人收藏此文章, 我要收藏renwofei423 推荐于 11个月 ...
随机推荐
- kubectl 命令记录 转帖自: https://www.kubernetes.org.cn/doc-45
kubectl annotate – 更新资源的注解. kubectl api-versions – 以“组/版本”的格式输出服务端支持的API版本. kubectl apply – 通过文件名或控制 ...
- Delphi cxGrid加行号
procedure SetRowNumber(var ASender: TcxGridTableView; AViewInfo: TcxCustomGridIndicatorItemViewInfo; ...
- TCP协议 连接三次握手
TCP(Transmission Control Protocol) 传输控制协议 TCP是主机对主机层的传输控制协议,提供可靠的连接服务,采用三次握手确认建立一个连接: 位码即tcp标志位,有6种标 ...
- Mysql的myqldump命令使用方法(备份与还原)
这里的备份与还原,是指表结构数据,和表里面的具体数据(一条一条的记录)同时备份和还原.因此mysqldump,mysql这两命令很强大. 1.备份(即导出)mysqldump -u root -p e ...
- WebSite下创建webapi
注意这里说的是WebSite,不是Webapp 就是我们常说的新建网站,而不是新建项目 直接上代码: 1 在要在website下创建,那么应该这么干.先添加引用和global.asax 2 然后创建对 ...
- Codeforces Round #374 (Div. 2) C(DAG上的DP)
C. Journey time limit per test 3 seconds memory limit per test 256 megabytes input standard input ou ...
- MT【171】共轭相随
$\textbf{证明:}$对任意$a,b\in R^+$, $\dfrac{1}{\sqrt{a+2b}}+\dfrac{1}{\sqrt{a+4b}}+\dfrac{1}{\sqrt{a+6b}} ...
- psutil库
psutil是一个非常强大的第三方库,用法简单,这里主要是做一下梳理. 先看看官方说明: psutil (python system and process utilities) is a cross ...
- (转)Maven学习总结(二)——Maven项目构建过程练习
孤傲苍狼 只为成功找方法,不为失败找借口! Maven学习总结(二)——Maven项目构建过程练习 上一篇只是简单介绍了一下maven入门的一些相关知识,这一篇主要是体验一下Maven高度自动化构建项 ...
- 2:jquery.cookie用法详细解析
一个轻量级的cookie 插件,可以读取.写入.删除 cookie. jquery.cookie.js 的配置 首先包含jQuery的库文件,在后面包含 jquery.cookie.js 的库文件. ...