HBase预分区方法
(what)什么是预分区?
HBase表在刚刚被创建时,只有1个分区(region),当一个region过大(达到hbase.hregion.max.filesize属性中定义的阈值,默认10GB)时,
表将会进行split,分裂为2个分区。表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。
HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。
(why)预分区的目的是什么?
减少由于region split带来的资源消耗。从而提高HBase的性能。
(how)如何预分区?
===方法1===
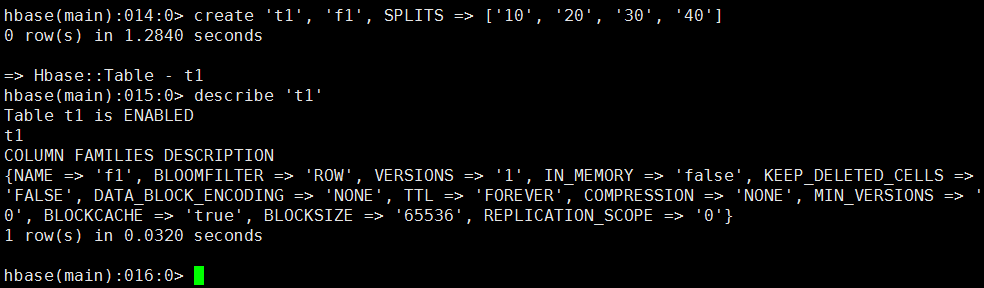
通过HBase shell来创建。命令样例如下:
create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
create 't1', {NAME =>'f1', TTL => 180}, SPLITS => ['10', '20', '30', '40']
create 't1', {NAME =>'f1', TTL => 180}, {NAME => 'f2', TTL => 240}, SPLITS => ['10', '20', '30', '40']
命令截图:
从Web界面查看表结构

===方法2===
仍然是通过HBase shell来创建,不过是通过读取文件
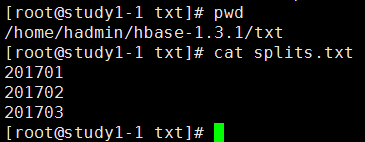
1、在任意路径下创建一个保存分区key的文件,我这里如下
路径:/home/hadmin/hbase-1.3.1/txt/splits.txt
内容如下图
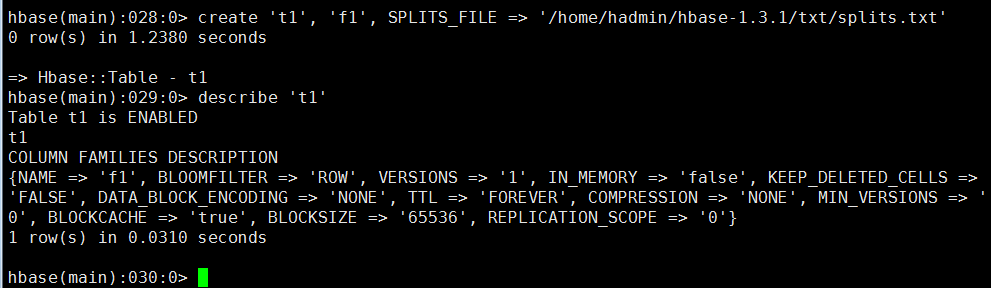
2、通过HBase shell命令创建表
命令样例:
create 't1', 'f1', SPLITS_FILE => '/home/hadmin/hbase-1.3.1/txt/splits.txt'
create 't1', {NAME =>'f1', TTL => 180}, SPLITS_FILE => '/home/hadmin/hbase-1.3.1/txt/splits.txt'
create 't1', {NAME =>'f1', TTL => 180}, {NAME => 'f2', TTL => 240}, SPLITS_FILE => '/home/hadmin/hbase-1.3.1/txt/splits.txt'
操作截图:
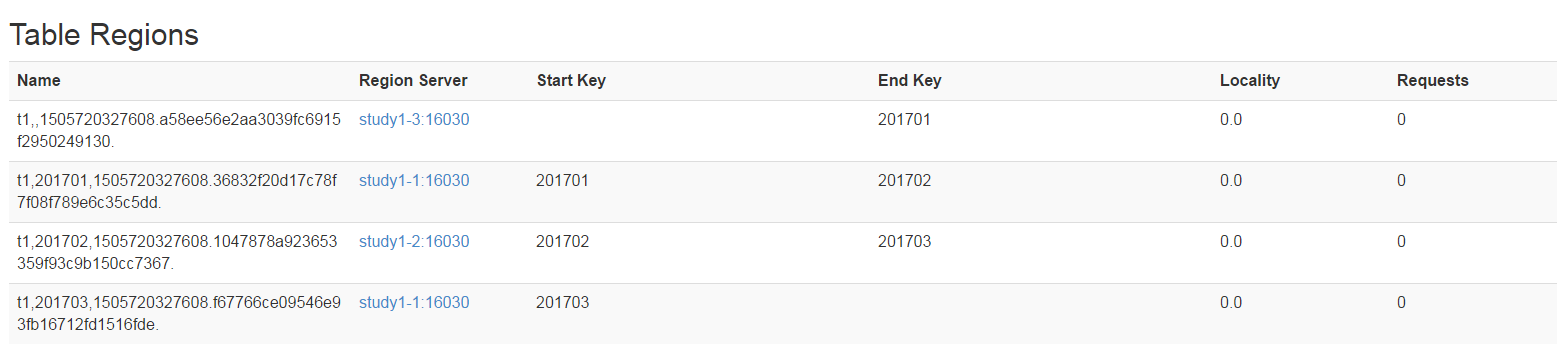
Web界面结果:
====方法3==
通过java api创建,代码样例如下:
package api; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.util.Bytes; public class create_table_sample2 {
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "192.168.1.80,192.168.1.81,192.168.1.82");
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin(); TableName table_name = TableName.valueOf("TEST1");
if (admin.tableExists(table_name)) {
admin.disableTable(table_name);
admin.deleteTable(table_name);
} HTableDescriptor desc = new HTableDescriptor(table_name);
HColumnDescriptor family1 = new HColumnDescriptor(constants.COLUMN_FAMILY_DF.getBytes());
family1.setTimeToLive(3 * 60 * 60 * 24); //过期时间
family1.setMaxVersions(3); //版本数
desc.addFamily(family1); byte[][] splitKeys = {
Bytes.toBytes("row01"),
Bytes.toBytes("row02"),
}; admin.createTable(desc, splitKeys);
admin.close();
connection.close();
}
}
--END--
HBase预分区方法的更多相关文章
- hbase 预分区与自动分区
我们知道,HBASE在创建表的时候,会自动为表分配一个Region,当一个Region过大达到默认的阈值时(默认10GB大小),HBase中该Region将会进行split,分裂为2个Region,以 ...
- Hbase预分区种子生成
提前生成Hbase预分区种子,在创建Hbase表时也进行相应的预分区,同时设置预分区的个数,预分区的范围对应Hbase监控页面的Region Server的start key与End key,从而使数 ...
- HBase预分区
seq 0 7 | awk '{printf("\\x%02x\\x%02x\n", $1/256, $1%256);}' | sort -R |head -3 create 'm ...
- 大数据量场景下storm自定义分组与Hbase预分区完美结合大幅度节省内存空间
前言:在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗.大量的预分 ...
- storm自定义分组与Hbase预分区结合节省内存消耗
Hbas预分区 在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗. ...
- hbase 预分区
转载 http://www.cnblogs.com/bdifn/p/3801737.html
- HBase表预分区与压缩
1.建立HBase预分区表.sql语句如下: create 'buyer_calllogs_info_ts', 'record', {SPLITS_FILE => 'hbase_calllogs ...
- HBase 热点问题——rowkey散列和预分区设计
热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作).大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响 ...
- HBase学习——3.HBase表设计
1.建表高级属性 建表过程中常用的shell命令 1.1 BLOOMFILTER 默认是 NONE 是否使用布隆过虑及使用何种方式,布隆过滤可以每列族单独启用 使用HColumnDescriptor. ...
随机推荐
- 手写html表格熟练度练习
table中的colspan和rowspan 经常手写表格时 查半天的两个属性,记下来 <!DOCTYPE html> <html lang="en" > ...
- java代码----I/O流从控制台输入信息判断并抛出异常
package com.a.b; import java.io.*; public class Yu { public static void main(String[] args) throws I ...
- Velocity基本常用语法
Velocity是一个基于java的模板引擎(template engine),它允许任何人仅仅简单的使用模板语言(template language)来引用由java代码定义的对象.作为一个比较完善 ...
- 2017百度之星初赛B-1002(HDU-6115)
一.思路 这题“看似”比较难搞的一点是,一个节点上有多个办公室,这怎么求?其他的,求树中任意两个节点的距离(注意:没有最远或最最进这一说法,因为树上任意两个节点之间有且仅有一条路径.不然就有回路了,对 ...
- Nginx 服务器开启status页面检测服务状态
一.Nginx status monitor 和apache 中服务器状态一样.输出的内容如: 第1列: 当前与http建立的连接数,包括等待的客户端连接:2 第2列: 接受的客户端连接总数目:20 ...
- 从windows拷贝到linux的脚本报错:未找到命令 or 语法错误
可能真的是命令拼错了或者参数有误,也可能是语法错误. 但是但是但是,如果之前脚本运行的好好的,没做任何改动或者仅仅改了一丁点儿. 那么脚本可能在格式上存在问题,解决方案: 安装dos2unix sud ...
- Python 模块 - jieba
安装 jieba pip3 install jieba jieba 支持三种分词模式: 精确模式:将句子最精确地切开,适合文本分析 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不 ...
- Rhythmk 一步一步学 JAVA (15) mybatis 入门学习-1
1.mybatis 通过mybatis-generator-core-1.3.2 代码生成: 工具下载地址: https://code.google.com/p/mybatis/ 解压工具包 myba ...
- create-react-app react脚手架
create-react-app react脚手架 官方脚手架 1.安装 npm install -g create-react-app 2.创建项目 create-react-app react-c ...
- 「小程序JAVA实战」开发用户redis-session(40)
转自:https://idig8.com/2018/09/05/xiaochengxujavashizhankaifayonghuredis-session39/ 接下来我们需要在我们的项目里面配置下 ...