mongodb复制集搭建
注:mongodb当前版本是3.4.3
1.准备三个虚拟机做服务器
192.168.168.129:27017
192.168.168.130:27017
192.168.168.131:27017
2.在三台服务器上安装mongodb服务
详细请见linux安装mongodb(设置非root用户和开机启动)
3.修改配置,在mongodb.conf增加replSet配置,然后启动服务即可
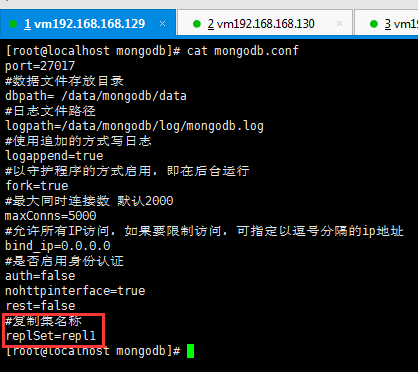
三个服务器的mongodb.conf中都需要加入replSet的指定,它们都属于repl1复制集;
replSet中的S一定要大写!
4.初始化复制集
登入任意一台机器的mongodb执行,因为是全新的复制集,所以可以任意进入一台执行;要是一台有数据,则需要在有数据上执行;要多台有数据则不能初始化。

rs.initiate({_id:'repl1',members:[{_id:1,host:'192.168.168.129:27017'}]})
初始化参数说明:
_id:复制集名称(第一个_id)
members:复制集服务器列表
_id:服务器的唯一ID(数组里_id)
host:服务器主机
我们操作的是192.168.168.129服务器,其中repl1即是复制集名称,和mongodb.conf中保持一致,初始化复制集的第一个服务器将会成为主复制集
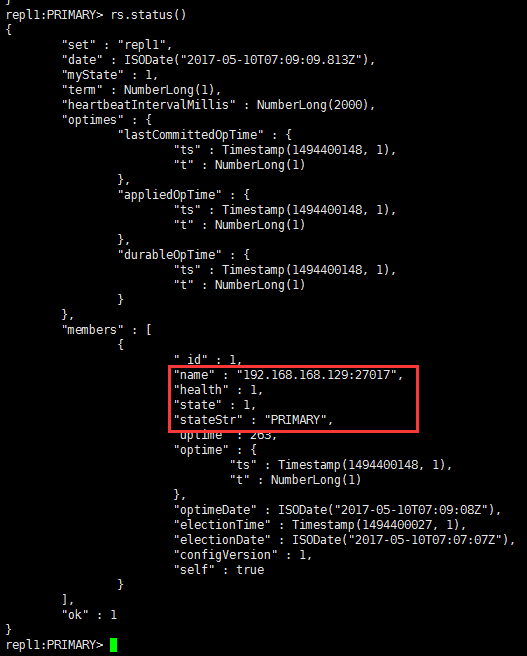
通过rs.status()查看复制集状态可以看到,192.168.168.129:27017已被自动分配为primary主复制集了
5.由主复制集添加从复制集

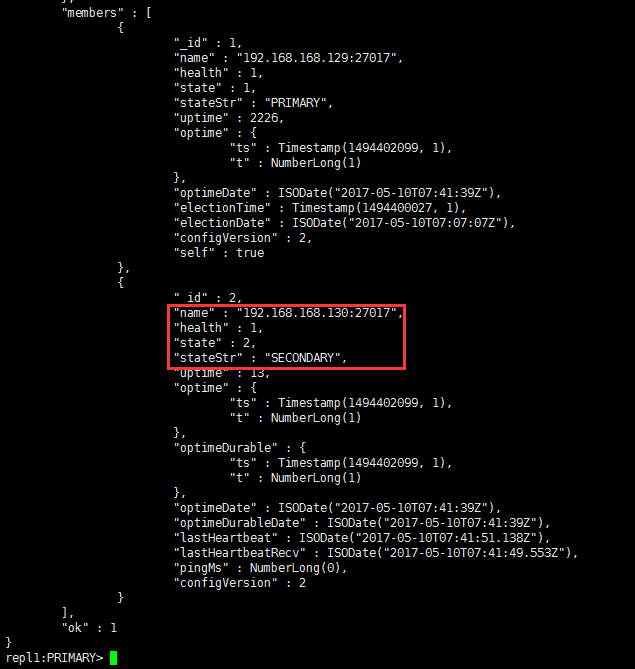
rs.add('192.168.168.130:27017'),增加192.168.168.130为从节点,第一次执行add时报了一个错,这个错说的是找到192.168.168.130服务,是因为防火墙的原因,我们把192.168.168.130防火墙关掉(service iptables stop),当第二次执行add的时候就成功了。
注:为了保证复制集中三个服务器之间正常连接,请保证三个服务器的防火墙都已关闭!
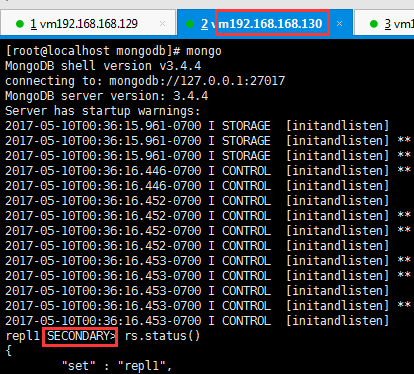
可以看到192.168.168.130:27017成为了secondary节点
6.由主复制集添加仲裁复制集
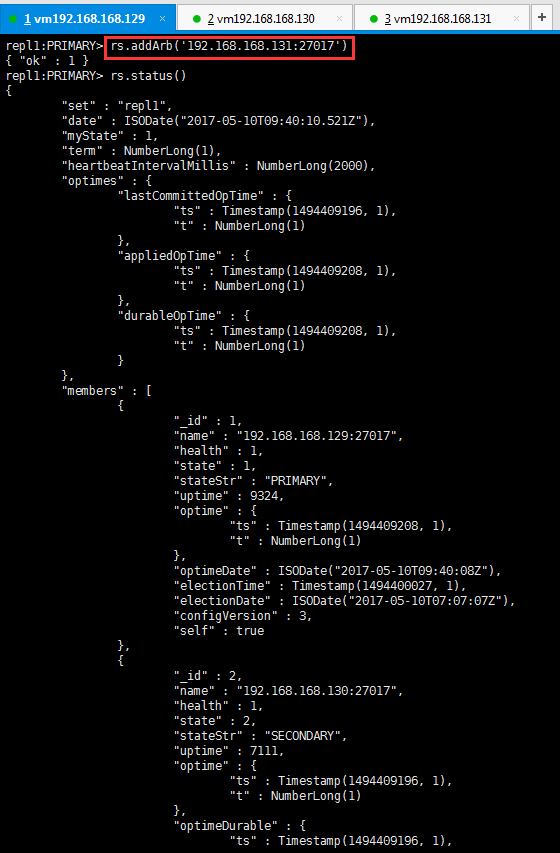

rs.addArb('192.168.168.131:27017')
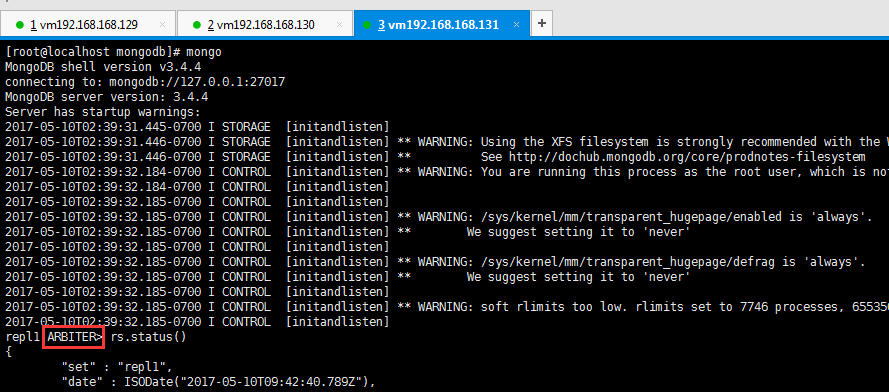
可以看到192.168.168.131:27017成为了arbiter节点
7.测试复制集secondary节点数据复制功能
在primary(192.168.168.129:27017)上插入数据:
repl1:PRIMARY> dbtestrepl1:PRIMARY> show collectionsrepl1:PRIMARY>for(var i =0; i <4; i ++){db.user.insert({userName:'gxt'+i,age:i})}WriteResult({"nInserted":1})repl1:PRIMARY> show collectionsuserrepl1:PRIMARY> db.user.find(){"_id":ObjectId("5912e308e5c3987e4a8131e2"),"userName":"gxt0","age":0}{"_id":ObjectId("5912e308e5c3987e4a8131e3"),"userName":"gxt1","age":1}{"_id":ObjectId("5912e308e5c3987e4a8131e4"),"userName":"gxt2","age":2}{"_id":ObjectId("5912e308e5c3987e4a8131e5"),"userName":"gxt3","age":3}repl1:PRIMARY>
在secondary上查看是否已经同步:
repl1:SECONDARY> dbtestrepl1:SECONDARY> show collections2017-05-10T03:14:54.665-0700 E QUERY [thread1]Error: listCollections failed:{"ok":0,"errmsg":"not master and slaveOk=false","code":13435,"codeName":"NotMasterNoSlaveOk"}:_getErrorWithCode@src/mongo/shell/utils.js:25:13DB.prototype._getCollectionInfosCommand@src/mongo/shell/db.js:805:1DB.prototype.getCollectionInfos@src/mongo/shell/db.js:817:19DB.prototype.getCollectionNames@src/mongo/shell/db.js:828:16shellHelper.show@src/mongo/shell/utils.js:762:9shellHelper@src/mongo/shell/utils.js:659:15@(shellhelp2):1:1repl1:SECONDARY> rs.slaveOk()repl1:SECONDARY> show collectionsuserrepl1:SECONDARY> db.user.find(){"_id":ObjectId("5912e308e5c3987e4a8131e2"),"userName":"gxt0","age":0}{"_id":ObjectId("5912e308e5c3987e4a8131e3"),"userName":"gxt1","age":1}{"_id":ObjectId("5912e308e5c3987e4a8131e4"),"userName":"gxt2","age":2}{"_id":ObjectId("5912e308e5c3987e4a8131e5"),"userName":"gxt3","age":3}repl1:SECONDARY>
通过db.user.find()查询到和主复制集上一样的数据,表示数据同步成功!
"errmsg" : "not master and slaveOk=false"错误说明:因为secondary是不允许读写的,如果非要解决,则执行:rs.slaveOk()
在arbiter上查看是否会有数据同步:
repl1:ARBITER> dbtestrepl1:ARBITER> show collections2017-05-10T03:22:02.554-0700 E QUERY [thread1]Error: listCollections failed:{"ok":0,"errmsg":"not master and slaveOk=false","code":13435,"codeName":"NotMasterNoSlaveOk"}:_getErrorWithCode@src/mongo/shell/utils.js:25:13DB.prototype._getCollectionInfosCommand@src/mongo/shell/db.js:805:1DB.prototype.getCollectionInfos@src/mongo/shell/db.js:817:19DB.prototype.getCollectionNames@src/mongo/shell/db.js:828:16shellHelper.show@src/mongo/shell/utils.js:762:9shellHelper@src/mongo/shell/utils.js:659:15@(shellhelp2):1:1repl1:ARBITER> rs.slaveOk()repl1:ARBITER> show collectionsrepl1:ARBITER> db.user.find()Error: error:{"ok":0,"errmsg":"node is not in primary or recovering state","code":13436,"codeName":"NotMasterOrSecondary"}repl1:ARBITER>
我们可以看到,arbiter并没有进行数据同步,因为仲裁节点只参与投票,不接收数据!
8.测试复制集主从节点故障转移功能
关闭primary节点,查看其它两个节点的情况:
repl1:PRIMARY>use adminswitched to db adminrepl1:PRIMARY> db.shutdownServer()server should be down...2017-05-10T03:27:04.162-0700 I NETWORK [thread1] trying reconnect to 127.0.0.1:27017(127.0.0.1) failed2017-05-10T03:27:04.207-0700 I NETWORK [thread1]Socket recv()Connection reset by peer 127.0.0.1:270172017-05-10T03:27:04.208-0700 I NETWORK [thread1]SocketException: remote:(NONE):0 error:9001 socket exception [RECV_ERROR] server [127.0.0.1:27017]2017-05-10T03:27:04.208-0700 I NETWORK [thread1] reconnect 127.0.0.1:27017(127.0.0.1) failed failed>
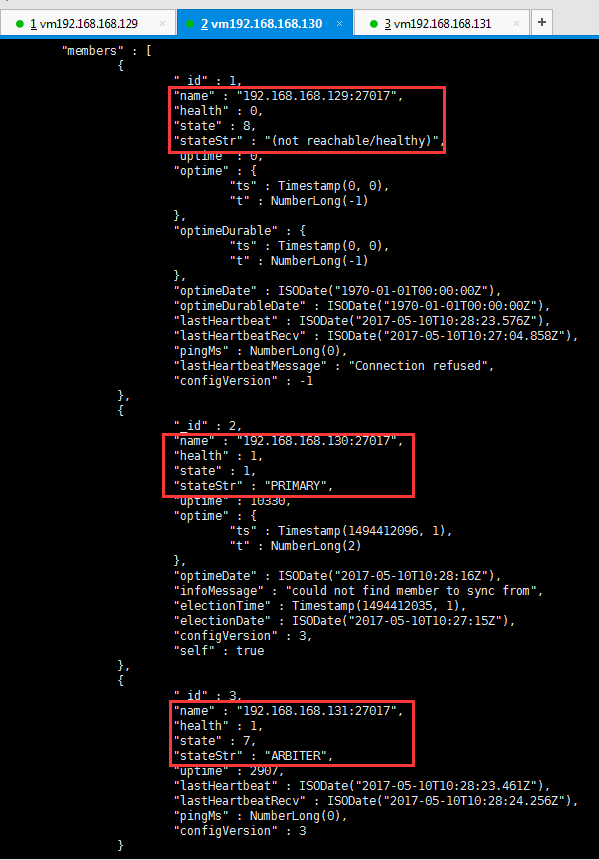
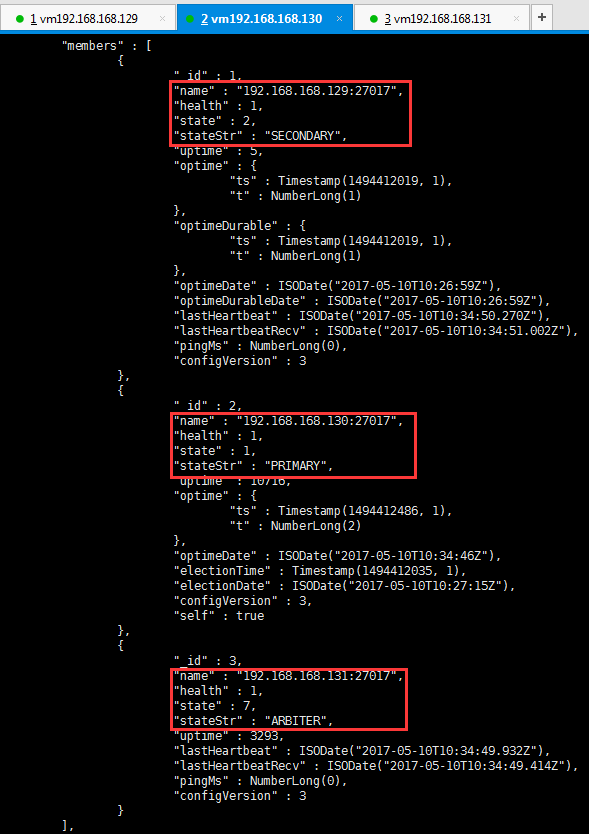
我们可以看到192.168.168.130:27017从secondary变成了primary,故障转移成功!不过现在这个复制集已没有可以同步数据的从节点了,但我们可以把192.168.168.129:27017重新启动,这时129会变成secondary,这样这个复制集就可以正常工作了。
9.复制集常用方法总结
rs.initiate():复制集初始化,例如:rs.initiate({_id:'repl1',members:[{_id:1,host:'192.168.168.129:27017'}]})
rs.reconfig():重新加载配置文件,例如:
rs.reconfig({_id:'repl1',members:[{_id:1,host:'192.168.168.129:27017'}]},{force:true})当只剩下一个secondary节点时,复制集变得不可用,则可以指定force属性强制将节点变成primary,然后再添加secondary节点
rs.status():查看复制集状态
db.printSlaveReplicationInfo():查看复制情况
rs.conf()/rs.config():查看复制集配置
rs.slaveOk():在当前连接让secondary可以提供读操作
rs.add():增加复制集节点,例如:
rs.add('192.168.168.130:27017')rs.add({"_id":3,"host":"192.168.168.130:27017","priority":0,"hidden":true})指定hidden属性添加备份节点rs.add({"_id":3,"host":"192.168.168.130:27017","priority":0,"slaveDelay":60})指定slaveDelay属性添加延迟节点priority:是优先级,默认为1,如果想手动指定某个节点为primary节点,则把对应节点的priority属性设置为所有节点中最大的一个即可
rs.remove():删除复制集节点,例如:rs.remove('192.168.168.130:27017')
rs.addArb():添加仲裁节点,例如:
rs.addArb('192.168.168.131:27017')或者rs.add({"_id":3,"host":"192.168.168.130:27017","arbiterOnly":true}),仲裁节点,只参与投票,不接收数据
属性说明:
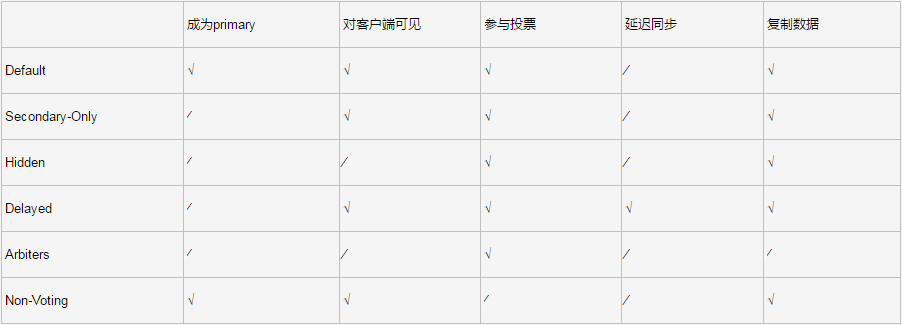
mongodb复制集搭建的更多相关文章
- MongoDB复制集搭建(3.4.17版)
==版本== mongodb-linux-x86_64-rhel70-3.4.17.tgz ==准备== 3个节点,我这里的IP及hostname分别是: 10.11.2.52 dscn49 10.1 ...
- MongoDB之 复制集搭建
MongoDB复制集搭建步骤,本次搭建使用3台机器,一个是主节点,一个是从节点,一个是仲裁者. 主节点负责与前台客户端进行数据读写交互,从节点只负责容灾,构建高可用,冗余备份.仲裁者的作用是当主节点宕 ...
- MongoDB复制集原理、环境配置及基本测试详解
一.MongoDB复制集概述 MongoDB复制集实现了冗余备份和故障转移两大功能,这样能保证数据库的高可用性.在生产环境,复制集至少包括三个节点,其中一个必须为主节点,一个从节点,一个仲裁节点.其中 ...
- MongoDB学习4:MongoDB复制集机制和原理,搭建复制集
1.复制集的作用 1.1 MongoDB复制集的主要意义在于实现服务高可用 1.2 它的实现依赖于两个方面的功能: · 数据写入时将数据迅速复制到另一个独立节点上 · 在接收写入的 ...
- MongoDB复制集技术
复制集搭建 没毛病: https://www.cnblogs.com/nicolegxt/p/6841442.html?utm_source=itdadao&utm_medium=referr ...
- mongdb复制集搭建
可参考官网教程 复制集增加了数据的冗余同时也提高了mongodb的可靠性,相比传统的主从架构,mongodb具有自动容灾的特性,即主库挂掉后会自动从剩下的从库中选举出一个节点做为主库(不需要人工干预) ...
- MongoDB 复制集节点增加移除及节点属性配置
复制集(replica Set)或者副本集是MongoDB的核心高可用特性之一,它基于主节点的oplog日志持续传送到辅助节点,并重放得以实现主从节点一致.再结合心跳机制,当感知到主节点不可访问或宕机 ...
- MongoDb复制集实现故障转移,读写分离
前言 数据库技术是信息系统的一个核心技术,发展很快,各种功能类型数据库层出不穷,之前工作中使用过关系型数据库(mysql.oracle等).面相对象数据库(db4o).key-value存储(Memc ...
- windows版本 MongoDB副本集搭建及开启身份验证
------------恢复内容开始------------ ------------恢复内容开始------------ MongoDB副本集搭建 我搭建的是一个主节点,两个副节点 构建目录结构如下 ...
随机推荐
- Oracle 同环比排除分母0
A 本期 B 同期(环期) 同比(环比) = (A-B)/B DECODE(NVL(B,0),0,0,ROUND(((A-B)/B),4)), --环比 DECODE(NVL(B),0,0,ROUN ...
- luogu P2764 最小路径覆盖问题
题目描述 给定有向图G=(V,E).设P 是G 的一个简单路(顶点不相交)的集合.如果V 中每个顶点恰好在P 的一条路上,则称P是G 的一个路径覆盖.P 中路径可以从V 的任何一个顶点开始,长度也是任 ...
- 【BZOJ 2241 打地鼠】
Time Limit: 10 Sec Memory Limit: 512 MBSubmit: 1430 Solved: 908[Submit][Status][Discuss] Descripti ...
- Consumer [分组背包]
Consumer Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/65536 K (Java/Others) Total Subm ...
- D. Sorting the Coins
Recently, Dima met with Sasha in a philatelic store, and since then they are collecting coins togeth ...
- nginx反向代理Tomcat/Jetty获取客户端IP地址
使用nginx做反向代理,Tomcat服务器和Jetty服务器如何获取客户端真实IP地址呢?首先nginx需要配置proxy_set_header,这样JSP使用request.getHeader(& ...
- Windows Server 2008 R2 Upgrade Paths
https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/dd ...
- 播放video
<html> <head> <title> four in one vedio</title> <style type="text/cs ...
- Linux下设置防火墙(开启端口)
1.修改文件/etc/sysconfig/iptables 在文件中加入如下内容,目的是对外界开放7001端口 -A RH-Firewall-1-INPUT -m state --state NEW ...
- Java基础学习知识体系图