Hadoop介绍及集群搭建
简介
Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。它的核心组件有HDFS(分布式文件系统)解决海量数据存储、YARN(作业调度和集群资源管理框架)解决资源任务调度和MapReduce(分布式运算编程框架)解决海量数据计算。另外Hadoop如今拥有一个庞大的体系,成长为Hadoop生态圈,新出现的项目越来越多,比如zk、hive、flume等。
Hadoop的特性优点
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop集群搭建
集群简介
HADOOP 集群具体来说包含两个集群:HDFS 集群和 YARN 集群,两者逻辑上分离,但物理上常在一起。
HDFS 集群负责海量数据的存储,集群中的角色主要有:NameNode、DataNode、SecondaryNameNode。YARN 集群负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager。
我们以三节点为例进行搭建,角色分配如下:
bigdata-01: NameNode DataNode | ResourceManager NodeManager
bigdata-02: DataNode SecondaryNameNode| NodeManager
bigdata-03: DataNode | NodeManager
服务器准备
三台linux虚拟机,同步时间,设置主机名和域名映射,关闭防火墙,安装jdk1.8,配置ssh免密登录。
搭建步骤
1 新建文件夹,分别用来存放压缩包、解压后的文件及运行的数据
mkdir -p /export/software
mkdir -p /export/servers
mkdir -p /export/data
2 把安装文件(最好是根据linux系统版本编译好的)放到服务器上的software文件夹内 然后解压到servers文件夹内
cd /export/software
tar -zxvf hadoop-2.7.4.tar -C /export/servers/
3 修改配置文件
#转到配置文件目录
cd /export/servers/hadoop-2.7.4/etc/hadoop
修改hadoop-env.sh
#修改JAVA_HOME路径为自己jdk安装了路径
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改core-site.xml(在configuration标签里面添加)
<!--指定默认文件系统是谁 以及文件系统访问方式 并指定了hdfs的namenode在哪-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-01:9000</value>
</property>
<!--指定hadoop运行时数据保存的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hddata</value> <!--该目录不需要自己提前创建-->
</property>
修改hdfs-site.xml(在configuration标签里面添加)
<!--指定文件副本数 默认3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定secondarynamenode所在机器-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata-02:50090</value>
</property>
修改mapred-site.xml(在configuration标签里面添加)
<!-- 指定mr运行模式 使用yarn进行资源管理-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改yarn-site.xml(在configuration标签里面添加)
<!--指定yarn老大ResourceManager所在的机器-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改slaves文件 指定集群从角色所在机器
bigdata-01
bigdata-02
bigdata-03
4 修改并重新source环境变量
vi /etc/profile
export JAVA_HOME=/export/servers/jdk1.8.0_141
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
5 格式化(初始化)集群
1、格式化准备来说是hdfs系统的初始化 创建一些自己运行所需要目录和文件
2、格式件在集群首次启动之前进行
3、只能格式化一次(本质在于格式件的时候会创建集群ID 如果多次格式化 使得主从之间集群ID标识不一致)
#以下两种格式化方式选一即可,不要两个都运行
hdfs namenode -format
hadoop namenode -format
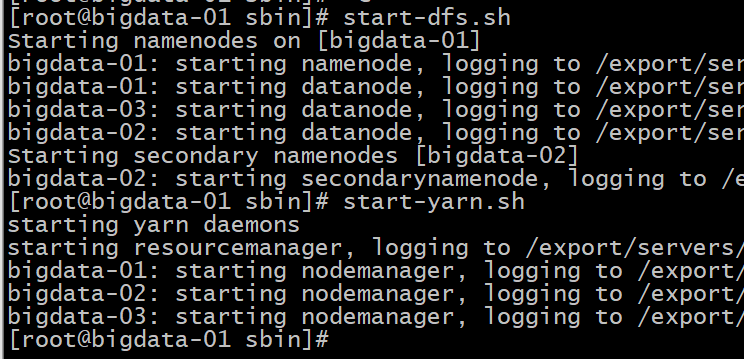
6 启动/停止集群
cd /export/servers/hadoop-2.7.4/sbin #启动/停止HDFS集群
start-dfs.sh stop.dfs.sh
#启动/停止YARN集群
start-yarn.sh stop.yarn.sh
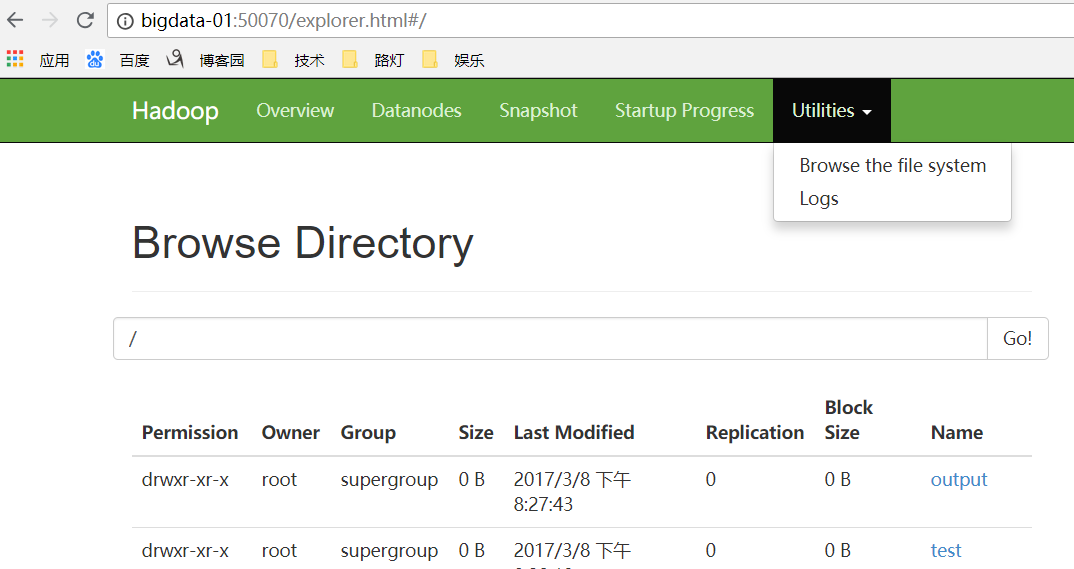
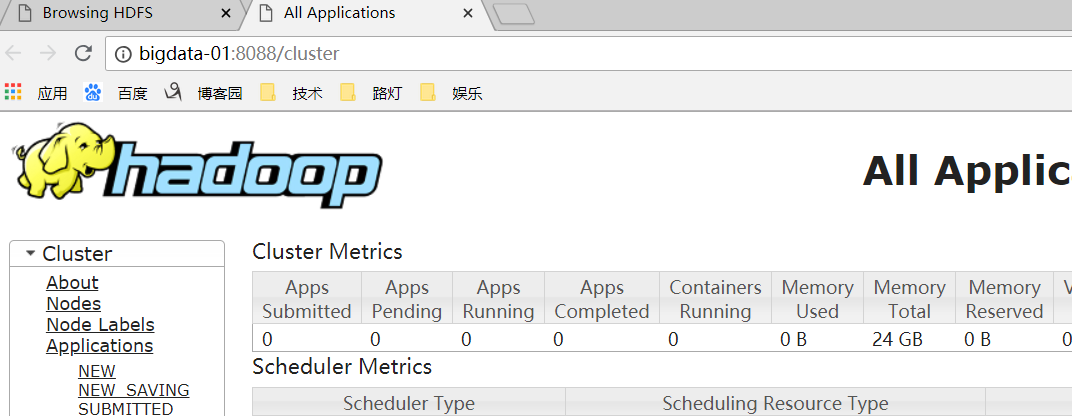
访问bigdata-01:50070 (namenode) 及 bigdata-01:8088 (resourcemanager)(windows电脑上没有配置host 就输ip+port):
Hadoop介绍及集群搭建的更多相关文章
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Hadoop完全分布式集群搭建
Hadoop的运行模式 Hadoop一般有三种运行模式,分别是: 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统.,用于开发和 ...
- 大数据之Hadoop完全分布式集群搭建
1.准备阶段 1.1.新建三台虚拟机 Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建.我们准备3台服务器(关闭防火墙.静态IP.主机名称).如果没 ...
- 从零自学Hadoop(06):集群搭建
阅读目录 序 集群搭建 监控 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- 2. zookeeper介绍及集群搭建
ZooKeeper 概述 Zookeeper 是一个分布式协调服务的开源框架. 主要用来解决分布式集群中 应用系统的一致性问题,例如怎样避免同时操作同一数据造成脏读的问题. ZooKeeper 本质上 ...
- 物联网微消息队列MQTT介绍-EMQX集群搭建以及与SpringBoot整合
项目全部代码地址:https://github.com/Tom-shushu/work-study.git (mqtt-emqt 项目) 先看我们最后实现的一个效果 1.手机端向主题 topic111 ...
随机推荐
- flowable 6.1.2 命令行完成请假审批流程的例子
一.创建 eclipse maven新项目 1.设置项目选项 其中,Create a simple project 要选中. 2.填写项目包名和项目名称 这里的Group id:必须是 org.flo ...
- PHP防止mysql注入方法
本文纲要: 1. 初始化你的变量 2. 一定记得要过滤你的变量 [一.在服务器端配置] 安全,PHP代码编写是一方面,PHP的配置更是非常关键. 我们php手手工安装的,php的默认配置文件在 /us ...
- 微信小程序转支付宝小程序
使用方法: npm install wx-alipay -g wxToalipay --src={{小程序源码目录}} --dest={{支付宝小程序目录,可缺省}} 点击回车后就可将微信小程序转换为 ...
- [转载] 视音频数据处理入门:RGB、YUV像素数据处理
===================================================== 视音频数据处理入门系列文章: 视音频数据处理入门:RGB.YUV像素数据处理 视音频数据处理 ...
- HDU - 233 Matrix
原题地址:http://acm.hdu.edu.cn/showproblem.php?pid=5015 解题思路:一看到题目,感觉是杨辉三角形,然后用组合数学做,不过没想出来怎么做,后来看数据+递推思 ...
- 剑指Offer面试题:1.实现单例模式
一 题目:实现单例模式Singleton 题目:设计一个类,我们只能生产该类的一个实例. 只能生成一个实例的类是实现了Singleton(单例)模式的类型.由于设计模式在面向对象程序设计中起着举足轻重 ...
- 浅析Python中bytes和str区别
本博转载自:Chown-Jane-Y的浅析Python3中的bytes和str类型 Python 3最重要的新特性之一是对字符串和二进制数据流做了明确的区分.文本总是Unicode,由str类型表示, ...
- 【BZOJ2850】巧克力王国 KDtree
[BZOJ2850]巧克力王国 Description 巧克力王国里的巧克力都是由牛奶和可可做成的.但是并不是每一块巧克力都受王国人民的欢迎,因为大家都不喜 欢过于甜的巧克力.对于每一块巧克力,我们设 ...
- 使用.NET Remoting开发分布式应用——基于租约的生存期
一.概述 知名类型的SingleCall对象可以在客户程序的方法调用之后被垃圾收集器清理掉,因为它没有保持状态,属于无状态的.而客户激活的类型的对象和知名类型的SingleTon对象都属于生存期长的对 ...
- 从jvm角度来解析java语法糖
java有很多语法糖,比如自动拆箱,自动装箱,foreach等等,这些原理相信每一个入门教程里都有讲,但是我相信不是每一个人 都通过查看这些语法糖的字节码来确认这些原理,因为我也是现在才想看一下. 1 ...