hadoop之 Hadoop1.x和Hadoop2.x构成对比
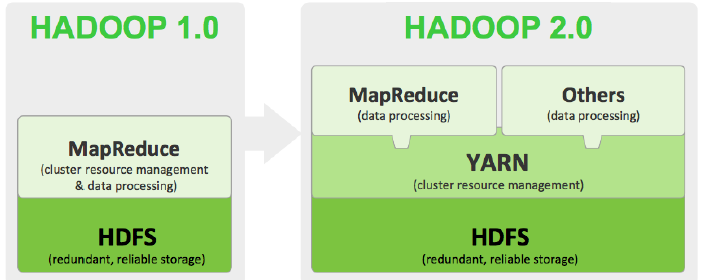
Hadoop1.x构成: HDFS、MapReduce(资源管理和任务调度);运行时环境为JobTracker和TaskTracker;
Hadoop2.0构成:HDFS、MapReduce/其他计算框架、YARN; 运行时环境为YARN
1、HDFS:HA、NameNode Federation
2、MapReduce/其他计算框架:运行在YARN之上的MapReduce通常称之为MapReduce2.0(MRv2)
3、YARN:资源管理系统(Yet Another Resource Negotiator),在其之上可以运行各种计算框架,如:MapReduce、Storm、Spark等;
HDFS2.0
解决HDFS1.0中单点故障和内存受限问题
解决单点故障: HDFS HA(High Available)
通过主备NameNode,当主NameNode发生故障时则切换到备NameNode;
解决内存受限问题: HDFS Federation
水平扩展,支持多个NameNode;
每个NameNode分管一部分目录;不同的NameNode可以分管不同的应用;
所有NameNode共享所有DataNode存储的资源;
HDFS2.0和HDFS1.0相比、仅是架构上发生了变化,使用方式不变,对HDFS使用者来说是透明的。比如说hdfs shell命令:
hadoop fs -ls /luogankun
hadoop fs -mkdir /luogankun/data
在HDFS1.0和HDFS2.0中用法是一致的。
YARN
Hadoop2.0新引入的资源管理系统
YARN核心思想:将MRv1中JobTracker的资源管理和任务调度分开,分别由ResourceManager和ApplicationMaster进程实现;
ResourceManager:负责整个集群的资源管理;整个集群只有一个;
ApplicationMaster:负责应用程序相关的事务,比如:任务调度、任务监控和任务容错;一个应用程序对应一个ApplicationMaster;
YARN引入的好处:使得多个计算框架可以运行在一个集群中,比如:MapReduce、Spark、Storm等;
MapReduce On YARN
运行在YARN之上的MapReduce称为MRv2;
将MapReduce作业直接运行在YARN上,而不是运行在由JobTracker和TaskTracker构建的MRv1之上;在Hadoop2.0中并不存在JobTracker和TaskTracker;
MRv2的模块基本功能:
1、YARN:负责资源管理和调度;
2、MRAppMaster:负责一个应用程序/作业的任务切分、任务调度、任务监控和容错;
3、Map/Reduce Task:任务驱动引擎,与MRv1一致;
每个应用程序/作业对应一个MRAppMaster,所以:
1、单个应用程序/作业运行失败,不会影响其他应用程序/作业;
2、负责应用程序/作业相关的事务,包括将从YARN分配得到的资源二次分配给内部的任务、任务切分、任务健康和容错等;
source : http://www.cnblogs.com/luogankun/p/3886989.html
hadoop之 Hadoop1.x和Hadoop2.x构成对比的更多相关文章
- 从零自学Hadoop(10):Hadoop1.x与Hadoop2.x
阅读目录 序 里程碑 Hadoop1.x与Hadoop2.x 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的 ...
- Hadoop入门进阶步步高(六)-Hadoop1.x与Hadoop2的差别
六.Hadoop1.x与Hadoop2的差别 1.变更介绍 Hadoop2相比較于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了非常大的提高,Ha ...
- Hadoop第3周练习--Hadoop2.X编译安装和实验
作业题目 位系统下进行本地编译的安装方式 选2 (1) 能否给web监控界面加上安全机制,怎样实现?抓图过程 (2)模拟namenode崩溃,例如将name目录的内容全部删除,然后通过secondar ...
- Hadoop学习(5)-- Hadoop2
在Hadoop1(版本<=0.22)中,由于NameNode和JobTracker存在单点中,这制约了hadoop的发展,当集群规模超过2000台时,NameNode和JobTracker已经不 ...
- Hadoop1.x与Hadoop2的区别
转自:http://blog.csdn.net/fenglibing/article/details/32916445 六.Hadoop1.x与Hadoop2的区别 1.变更介绍 Hadoop2相比较 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Data - Hadoop伪分布式配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Hadoop1.0 与Hadoop2.0
Hadoop1.0的局限-MapReduce •扩展性 –集群最大节点数–4000 –最大并发任务数–40000 (当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增 ...
- Hadoop1.0 和 Hadoop2.0
date: 2018-11-16 18:54:37 updated: 2018-11-16 18:54:37 1.从Hadoop整体框架来说 1.1 Hadoop1.0即第一代Hadoop,由分布式存 ...
随机推荐
- 浅谈history对象以及路由插件原理
简介 History对象最初设计用来表示窗口的浏览历史,但是,出于隐私方面的原因,History对象不再允许脚本访问已经访问过的实际URL.虽然,我们不清楚历史URL,但是,我们可以通过History ...
- Python笔记 #09# Basic plots with matplotlib
源:DataCamp 气泡的大小表示人口的多少,横坐标表示人均GDP(美元),纵坐标表示预期寿命.-- 作者:Hans Rosling Python 中有许许多多用于可视化的包,而 matplotli ...
- loj2163 / bzoj2212 / P3521 [POI2011]ROT-Tree Rotations(线段树合并)
P3521 [POI2011]ROT-Tree Rotations loj2163 [POI2011]ROT-Tree Rotations(数据加强) (loj的数据套了个fread优化才过...) ...
- 20145322何志威《网络对抗》Exp2 后门原理与实践
基础问题回答 1 例举你能想到的一个后门进入到你系统中的可能方式? 在网上下载盗版软件时捆绑的后门程序. 不小心进入钓鱼网站. 2 例举你知道的后门如何启动起来(win及linux)的方式? Wind ...
- InstallShieldpro2015 使用教程
1.下载地址:http://pan.baidu.com/s/1pLDCh3H ,如果网盘链接失效,请联系我. 2.解压后双击 3.安装完毕后,运行InstallShieldpro2015,会出现如下提 ...
- ubuntu16.04下安装TensorFlow(GPU加速)----详细图文教程【转】
本文转载自:https://blog.csdn.net/zhaoyu106/article/details/52793183 le/details/52793183 写在前面 一些废话 接触深度学习已 ...
- 内核加载模块时提示usb_common: exports duplicate symbol of_usb_get_dr_mode
1.分析: 既然符号重复了,那么说明有一个部分既被编译到内核中也被编译成模块了,因此在加载模块时,内核报符号重复的提示 2.解决 直接配置内核的某一部分编译成模块,例如笔者就直接将USB这一部分编译成 ...
- Python学习札记(四十三) IO 3
参考:操作文件和目录 NOTE: 1.Python内置的os模块可以直接调用操作系统提供的接口函数: 2.os.name 打印操作系统的名称:如果是posix,说明系统是Linux.Unix或Mac ...
- springboot p6spy 打印完整sql
调试时打印出sql的需求,太正常不过了,mybatis也提供了这样的功能: mybatis: configuration: log-impl: org.apache.ibatis.logging.st ...
- hdu 4739 Zhuge Liang's Mines DFS
http://acm.hdu.edu.cn/showproblem.php?pid=4739 题意: 给定100*100的矩阵中n(n<= 20)个点,每次只能一走能够形成正方形的四个点,正方形 ...