LevelDB 读取记录
【LevelDB 读取记录】
LevelDb是针对大规模Key/Value数据的单机存储库,从应用的角度来看,LevelDb就是一个存储工具。而作为称职的存储工具,常见的调用接口无非是新增KV,删除KV,读取KV,更新Key对应的Value值这么几种操作。LevelDb的接口没有直接支持更新操作的接口,如果需要更新某个Key的Value,你可以选择直接生猛地插入新的KV,保持Key相同,这样系统内的key对应的value就会被更新;或者你可以先删除旧的KV, 之后再插入新的KV,这样比较委婉地完成KV的更新操作。
假设应用提交一个Key值,下面我们看看LevelDb是如何从存储的数据中读出其对应的Value值的。图7-1是LevelDb读取过程的整体示意图。
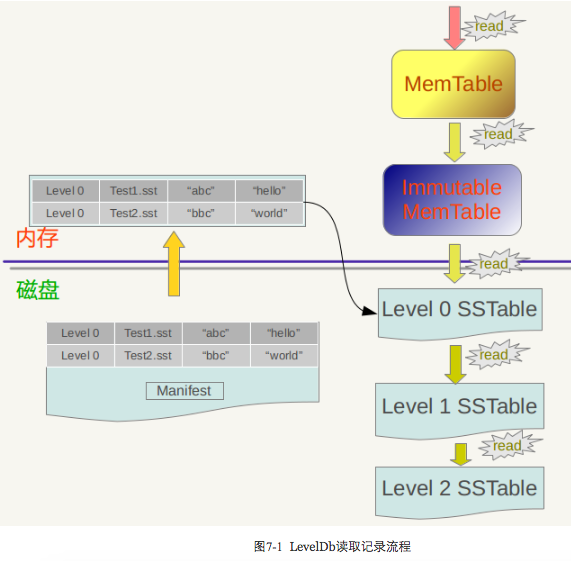
LevelDb首先会去查看内存中的Memtable,如果Memtable中包含key及其对应的value,则返回value值即可;如果在Memtable没有读到key,则接下来到同样处于内存中的Immutable Memtable中去读取,类似地,如果读到就返回,若是没有读到,那么只能万般无奈下从磁盘中的大量SSTable文件中查找。因为SSTable数量较多,而且分成多个Level,所以在SSTable中读数据是相当蜿蜒曲折的一段旅程。总的读取原则是这样的:首先从属于level 0的文件中查找,如果找到则返回对应的value值,如果没有找到那么到level 1中的文件中去找,如此循环往复,直到在某层SSTable文件中找到这个key对应的value为止(或者查到最高level,查找失败,说明整个系统中不存在这个Key)。
那么为什么是从Memtable到Immutable Memtable,再从Immutable Memtable到文件,而文件中为何是从低level到高level这么一个查询路径呢?道理何在?之所以选择这么个查询路径,是因为从信息的更新时间来说,很明显Memtable存储的是最新鲜的KV对;Immutable Memtable中存储的KV数据对的新鲜程度次之;而所有SSTable文件中的KV数据新鲜程度一定不如内存中的Memtable和Immutable Memtable的。对于SSTable文件来说,如果同时在level L和Level L+1找到同一个key,level L的信息一定比level L+1的要新。也就是说,上面列出的查找路径就是按照数据新鲜程度排列出来的,越新鲜的越先查找。
为啥要优先查找新鲜的数据呢?这个道理不言而喻,举个例子。比如我们先往levelDb里面插入一条数据{key="www.samecity.com" value="我们"},过了几天,samecity网站改名为:69同城,此时我们插入数据{key="www.samecity.com" value="69同城"},同样的key,不同的value;逻辑上理解好像levelDb中只有一个存储记录,即第二个记录,但是在levelDb中很可能存在两条记录,即上面的两个记录都在levelDb中存储了,此时如果用户查询key="www.samecity.com",我们当然希望找到最新的更新记录,也就是第二个记录返回,这就是为何要优先查找新鲜数据的原因。
前文有讲:对于SSTable文件来说,如果同时在level L和Level L+1找到同一个key,level L的信息一定比level L+1的要新。这是一个结论,理论上需要一个证明过程,否则会招致如下的问题:为神马呢?从道理上讲呢,很明白:因为Level L+1的数据不是从石头缝里蹦出来的,也不是做梦梦到的,那它是从哪里来的?Level L+1的数据是从Level L 经过Compaction后得到的(如果您不知道什么是Compaction,那么........也许以后会知道的),也就是说,您看到的现在的Level L+1层的SSTable数据是从原来的Level L中来的,现在的Level L比原来的Level L数据要新鲜,所以可证,现在的Level L比现在的Level L+1的数据要新鲜。
SSTable文件很多,如何快速地找到key对应的value值?在LevelDb中,level 0一直都爱搞特殊化,在level 0和其它level中查找某个key的过程是不一样的。因为level 0下的不同文件可能key的范围有重叠,某个要查询的key有可能多个文件都包含,这样的话LevelDb的策略是先找出level 0中哪些文件包含这个key(manifest文件中记载了level和对应的文件及文件里key的范围信息,LevelDb在内存中保留这种映射表), 之后按照文件的新鲜程度排序,新的文件排在前面,之后依次查找,读出key对应的value。而如果是非level 0的话,因为这个level的文件之间key是不重叠的,所以只从一个文件就可以找到key对应的value。
最后一个问题,如果给定一个要查询的key和某个key range包含这个key的SSTable文件,那么levelDb是如何进行具体查找过程的呢?levelDb一般会先在内存中的Cache中查找是否包含这个文件的缓存记录,如果包含,则从缓存中读取;如果不包含,则打开SSTable文件,同时将这个文件的索引部分加载到内存中并放入Cache中。 这样Cache里面就有了这个SSTable的缓存项,但是只有索引部分在内存中,之后levelDb根据索引可以定位到哪个内容Block会包含这条key,从文件中读出这个Block的内容,在根据记录一一比较,如果找到则返回结果,如果没有找到,那么说明这个level的SSTable文件并不包含这个key,所以到下一级别的SSTable中去查找。
从之前介绍的LevelDb的写操作和这里介绍的读操作可以看出,相对写操作,读操作处理起来要复杂很多,所以写的速度必然要远远高于读数据的速度,也就是说,LevelDb比较适合写操作多于读操作的应用场合。而如果应用是很多读操作类型的,那么顺序读取效率会比较高,因为这样大部分内容都会在缓存中找到,尽可能避免大量的随机读取操作。
参考:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
LevelDB 读取记录的更多相关文章
- leveldb 学习记录(三) MemTable 与 Immutable Memtable
前文: leveldb 学习记录(一) skiplist leveldb 学习记录(二) Slice 存储格式: leveldb数据在内存中以 Memtable存储(核心结构是skiplist 已介绍 ...
- leveldb 学习记录(四) skiplist补与变长数字
在leveldb 学习记录(一) skiplist 已经将skiplist的插入 查找等操作流程用图示说明 这里在介绍 下skiplist的代码 里面有几个模块 template<typenam ...
- leveldb 学习记录(四)Log文件
前文记录 leveldb 学习记录(一) skiplistleveldb 学习记录(二) Sliceleveldb 学习记录(三) MemTable 与 Immutable Memtablelevel ...
- leveldb 学习记录(一) skiplist
leveldb LevelDb是一个持久化存储的KV系统,并非完全将数据放置于内存中,部分数据也会存储到磁盘上. 想了解这个由谷歌大神编写的经典项目. 可以从数据结构以及数据结构的处理下手,也可以从示 ...
- leveldb 学习记录(五)SSTable格式介绍
本节主要记录SSTable的结构 为下一步代码阅读打好基础,考虑到已经有大量优秀博客解析透彻 就不再编写了 这里推荐 https://blog.csdn.net/tankles/article/det ...
- leveldb 学习记录(七) SSTable构造
使用TableBuilder构造一个Table struct TableBuilder::Rep { // TableBuilder内部使用的结构,记录当前的一些状态等 Options options ...
- leveldb 学习记录(八) compact
随着运行时间的增加,memtable会慢慢 转化成 sstable. sstable会越来越多 我们就需要进行整合 compact 代码会在写入查询key值 db写入时等多出位置调用MaybeSche ...
- leveldb 学习记录(二) Slice
基本每个KV库都有一个简洁的字符串管理类 比如redis的sds 比如leveldb的slice 管理一个字符串指针和数据长度 通过对字符串指针 长度的管理实现一般的创建 判断是否为空 获取第N个位 ...
- leveldb 学习记录(六)SSTable:Block操作
block结构示意图 sstable中Block 头文件如下: class Block { public: // Initialize the block with the specified con ...
随机推荐
- 纪念又一次ak
t1网络流 随便建个图就可以了 t2单调队列 分成两组来做 t3dp+高精度 为了不被卡厂用了万进制
- idea如何热部署(转)
IntelliJ IDEA 怎么热部署,每次修改java文件就得重启tomcat 原文链接:http://blog.csdn.net/dandandeshangni/article/details/ ...
- C# 序列化详解,xml序列化,json序列化对比
本文讲讲一些纯技术的东西.并且讲讲一些原理性的东西,和一般的百度的文章不一致,如果你对序列化不清楚,绝对可以很有收获. 技术支持QQ群(主要面向工业软件及HSL组件的):592132877 (组件的 ...
- 20155236 2016-2017-2 《Java程序设计》第六周学习总结
20155236 2016-2017-2 <Java程序设计>第六周学习总结 教材学习内容总结 InputStream与OutputStream 从应用程序角度来看,如果要将数据从来源取出 ...
- Inno Setup 软件封装
例子: ; 脚本用 Inno Setup 脚本向导 生成. ; 查阅文档获取创建 INNO SETUP 脚本文件的详细资料! #define MyAppName "隧道照明系统客户端程序&q ...
- ubuntu系统无法ssh登录--安装openssh
与红帽子系列的Linux发行版不同,Ubuntu系统安装后并不能直接进行ssh登录.需要手动安装openssh才行. Ubuntu安装openssh命令如下: sudo apt-get install ...
- cratedb 基本试用
安装 docker run -d -p 4200:4200 crate UI访问 http://localhost:4200/#!/ 创建数据 tweets 是默认导入的,点击帮助导航可以操作 登陆 ...
- Windows 10 上的 Git 如何清除密码? Git Credential Manager for Windows
Windows 10 上的 Git 如何清除密码? 因为一台新的电脑是 Windows 10 在第一次使用 Git 要求输入密码时把密码给输错了. 之前提交都是说 Token 错了,不再出现提示密码. ...
- 用JavaScript解决Placeholder的IE8兼容问题
<script type="text/javascript"> if( !('placeholder' in document.createElement('input ...
- 刷新SQL Server所有视图、函数、存储过程 更多 sql 此脚本用于在删除或添加字段时刷新相关视图,并检查视图、函数、存储过程有效性。 [SQL]代码 --视图、存储过程、函数名称 DECLARE @NAME NVARCHAR(255); --局部游标 DECLARE @CUR CURSOR --自动修改未上状态为旷课 SET @CUR=CURSOR SCROLL DYNAMIC FO
刷新SQL Server所有视图.函数.存储过程 更多 sql 此脚本用于在删除或添加字段时刷新相关视图,并检查视图.函数.存储过程有效性. [SQL]代码 --视图.存储过程.函数名称 DE ...