LevelDB 读取记录
【LevelDB 读取记录】
LevelDb是针对大规模Key/Value数据的单机存储库,从应用的角度来看,LevelDb就是一个存储工具。而作为称职的存储工具,常见的调用接口无非是新增KV,删除KV,读取KV,更新Key对应的Value值这么几种操作。LevelDb的接口没有直接支持更新操作的接口,如果需要更新某个Key的Value,你可以选择直接生猛地插入新的KV,保持Key相同,这样系统内的key对应的value就会被更新;或者你可以先删除旧的KV, 之后再插入新的KV,这样比较委婉地完成KV的更新操作。
假设应用提交一个Key值,下面我们看看LevelDb是如何从存储的数据中读出其对应的Value值的。图7-1是LevelDb读取过程的整体示意图。
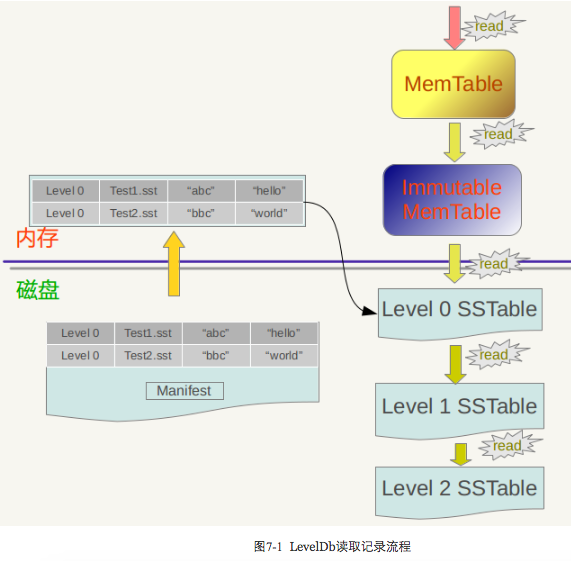
LevelDb首先会去查看内存中的Memtable,如果Memtable中包含key及其对应的value,则返回value值即可;如果在Memtable没有读到key,则接下来到同样处于内存中的Immutable Memtable中去读取,类似地,如果读到就返回,若是没有读到,那么只能万般无奈下从磁盘中的大量SSTable文件中查找。因为SSTable数量较多,而且分成多个Level,所以在SSTable中读数据是相当蜿蜒曲折的一段旅程。总的读取原则是这样的:首先从属于level 0的文件中查找,如果找到则返回对应的value值,如果没有找到那么到level 1中的文件中去找,如此循环往复,直到在某层SSTable文件中找到这个key对应的value为止(或者查到最高level,查找失败,说明整个系统中不存在这个Key)。
那么为什么是从Memtable到Immutable Memtable,再从Immutable Memtable到文件,而文件中为何是从低level到高level这么一个查询路径呢?道理何在?之所以选择这么个查询路径,是因为从信息的更新时间来说,很明显Memtable存储的是最新鲜的KV对;Immutable Memtable中存储的KV数据对的新鲜程度次之;而所有SSTable文件中的KV数据新鲜程度一定不如内存中的Memtable和Immutable Memtable的。对于SSTable文件来说,如果同时在level L和Level L+1找到同一个key,level L的信息一定比level L+1的要新。也就是说,上面列出的查找路径就是按照数据新鲜程度排列出来的,越新鲜的越先查找。
为啥要优先查找新鲜的数据呢?这个道理不言而喻,举个例子。比如我们先往levelDb里面插入一条数据{key="www.samecity.com" value="我们"},过了几天,samecity网站改名为:69同城,此时我们插入数据{key="www.samecity.com" value="69同城"},同样的key,不同的value;逻辑上理解好像levelDb中只有一个存储记录,即第二个记录,但是在levelDb中很可能存在两条记录,即上面的两个记录都在levelDb中存储了,此时如果用户查询key="www.samecity.com",我们当然希望找到最新的更新记录,也就是第二个记录返回,这就是为何要优先查找新鲜数据的原因。
前文有讲:对于SSTable文件来说,如果同时在level L和Level L+1找到同一个key,level L的信息一定比level L+1的要新。这是一个结论,理论上需要一个证明过程,否则会招致如下的问题:为神马呢?从道理上讲呢,很明白:因为Level L+1的数据不是从石头缝里蹦出来的,也不是做梦梦到的,那它是从哪里来的?Level L+1的数据是从Level L 经过Compaction后得到的(如果您不知道什么是Compaction,那么........也许以后会知道的),也就是说,您看到的现在的Level L+1层的SSTable数据是从原来的Level L中来的,现在的Level L比原来的Level L数据要新鲜,所以可证,现在的Level L比现在的Level L+1的数据要新鲜。
SSTable文件很多,如何快速地找到key对应的value值?在LevelDb中,level 0一直都爱搞特殊化,在level 0和其它level中查找某个key的过程是不一样的。因为level 0下的不同文件可能key的范围有重叠,某个要查询的key有可能多个文件都包含,这样的话LevelDb的策略是先找出level 0中哪些文件包含这个key(manifest文件中记载了level和对应的文件及文件里key的范围信息,LevelDb在内存中保留这种映射表), 之后按照文件的新鲜程度排序,新的文件排在前面,之后依次查找,读出key对应的value。而如果是非level 0的话,因为这个level的文件之间key是不重叠的,所以只从一个文件就可以找到key对应的value。
最后一个问题,如果给定一个要查询的key和某个key range包含这个key的SSTable文件,那么levelDb是如何进行具体查找过程的呢?levelDb一般会先在内存中的Cache中查找是否包含这个文件的缓存记录,如果包含,则从缓存中读取;如果不包含,则打开SSTable文件,同时将这个文件的索引部分加载到内存中并放入Cache中。 这样Cache里面就有了这个SSTable的缓存项,但是只有索引部分在内存中,之后levelDb根据索引可以定位到哪个内容Block会包含这条key,从文件中读出这个Block的内容,在根据记录一一比较,如果找到则返回结果,如果没有找到,那么说明这个level的SSTable文件并不包含这个key,所以到下一级别的SSTable中去查找。
从之前介绍的LevelDb的写操作和这里介绍的读操作可以看出,相对写操作,读操作处理起来要复杂很多,所以写的速度必然要远远高于读数据的速度,也就是说,LevelDb比较适合写操作多于读操作的应用场合。而如果应用是很多读操作类型的,那么顺序读取效率会比较高,因为这样大部分内容都会在缓存中找到,尽可能避免大量的随机读取操作。
参考:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
LevelDB 读取记录的更多相关文章
- leveldb 学习记录(三) MemTable 与 Immutable Memtable
前文: leveldb 学习记录(一) skiplist leveldb 学习记录(二) Slice 存储格式: leveldb数据在内存中以 Memtable存储(核心结构是skiplist 已介绍 ...
- leveldb 学习记录(四) skiplist补与变长数字
在leveldb 学习记录(一) skiplist 已经将skiplist的插入 查找等操作流程用图示说明 这里在介绍 下skiplist的代码 里面有几个模块 template<typenam ...
- leveldb 学习记录(四)Log文件
前文记录 leveldb 学习记录(一) skiplistleveldb 学习记录(二) Sliceleveldb 学习记录(三) MemTable 与 Immutable Memtablelevel ...
- leveldb 学习记录(一) skiplist
leveldb LevelDb是一个持久化存储的KV系统,并非完全将数据放置于内存中,部分数据也会存储到磁盘上. 想了解这个由谷歌大神编写的经典项目. 可以从数据结构以及数据结构的处理下手,也可以从示 ...
- leveldb 学习记录(五)SSTable格式介绍
本节主要记录SSTable的结构 为下一步代码阅读打好基础,考虑到已经有大量优秀博客解析透彻 就不再编写了 这里推荐 https://blog.csdn.net/tankles/article/det ...
- leveldb 学习记录(七) SSTable构造
使用TableBuilder构造一个Table struct TableBuilder::Rep { // TableBuilder内部使用的结构,记录当前的一些状态等 Options options ...
- leveldb 学习记录(八) compact
随着运行时间的增加,memtable会慢慢 转化成 sstable. sstable会越来越多 我们就需要进行整合 compact 代码会在写入查询key值 db写入时等多出位置调用MaybeSche ...
- leveldb 学习记录(二) Slice
基本每个KV库都有一个简洁的字符串管理类 比如redis的sds 比如leveldb的slice 管理一个字符串指针和数据长度 通过对字符串指针 长度的管理实现一般的创建 判断是否为空 获取第N个位 ...
- leveldb 学习记录(六)SSTable:Block操作
block结构示意图 sstable中Block 头文件如下: class Block { public: // Initialize the block with the specified con ...
随机推荐
- java-IO-基本输出输入流
/ 标准输入输出流: 直接类名调用 一经创建无法改变 public static final PrintStream err “标准”错误输出流. public static final InputS ...
- html5实现本页面元素拖放和本地文件拖放
HTML5拖放 拖放本地数据 1.HTML拖放 拖放(Drag 和 Drop)是HTML5标准的组成部分 2.拖放开始: ondragStart:调用了一个函数,drag(event),它规定了被 ...
- POJ2942 Knights of the Round Table【Tarjan点双联通分量】【二分图染色】【补图】
LINK 题目大意 有一群人,其中有一些人之间有矛盾,现在要求选出一些人形成一个环,这个环要满足如下条件: 1.人数大于1 2.总人数是奇数 3.有矛盾的人不能相邻 问有多少人不能和任何人形成任何的环 ...
- Python面试题(十二)
1.利用Python执行shell脚本取得返回结果 import subprocess result = subprocess.getoutput('dir') 答案 2.用Python将" ...
- Oracle Database express 11g 第 2 版安装和配置
官方Oracle Database 快捷版 11g 第 2 版的下载地址: http://www.oracle.com/technetwork/cn/products/express-edition/ ...
- windows7安装django并创建第一个应用
1.安装django 1.1.下载Django包 https://www.djangoproject.com/download/https://www.djangoproject.com/m/rele ...
- UOJ 347(洛谷4220) 【WC2018】通道——随机化
题目:http://uoj.ac/problem/347 https://www.luogu.org/problemnew/show/P4220 先写了暴力分的44分.那个两棵树.其中一棵是编号连续的 ...
- Sql Server中的事务隔离级别
数据库中的事物有ACID(原子性,一致性,隔离性,持久性)四个特性.其中隔离性是用来处理并发执行的事务之间的数据访问控制.SqlServer中提供了几种不同级别的隔离类型. 概念 Read UnCom ...
- Linux环境安装jdk10
一. 下载jdk 下载方式一:直接在linux上下载 wget --no-check-certificate --no-cookies --header "Cookie: oraclelic ...
- SQL相关简单游标
BEGIN TRY Create Table #Temp_Table_Record_Stat ( .... ) DECLARE table_Cursor CURSOR FOR SELECT objec ...