Python3.6+Scrapy爬取知名技术文章网站
爬取分析
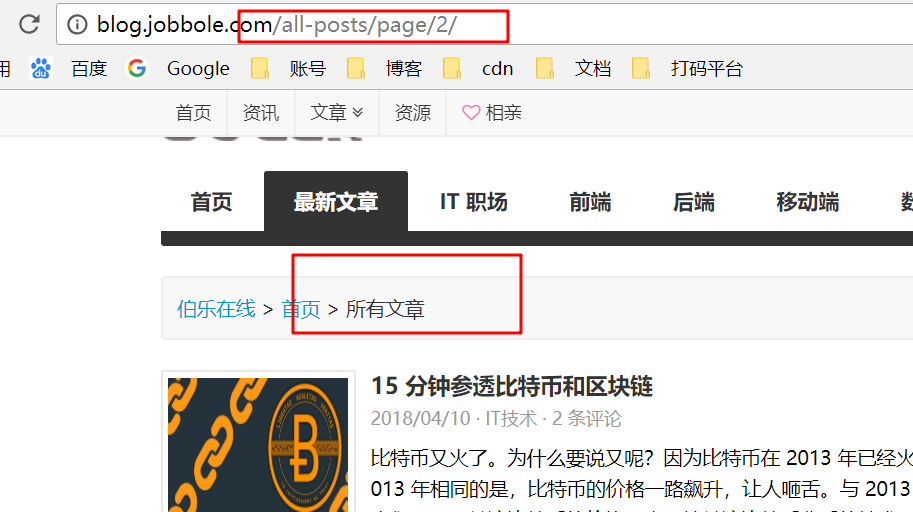

伯乐在线已经提供了所有文章的接口,还有下一页的接口,所有我们可以直接爬取一页,再翻页爬。
环境搭建
Windows下安装Python: http://www.cnblogs.com/0bug/p/8228378.html
virtualenv的安装:http://www.cnblogs.com/0bug/p/8598458.html
创建项目的虚拟环境(Python3.6):
mkvirtualenv article_spider
scrapy github项目:https://github.com/scrapy/scrapy
安装Scrapy
1.pip install lxml 2.pip install pyopenssl 3.pip install pywin32 4.下载相应版本的twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 4.安装下载的twisted : pip install C:\Users\lichengguang\Downloads\Twisted-17.9.0-cp36-cp36m-win_amd64.whl 5.pip install scrapy
scrapy命令:
1 查看帮助
scrapy -h
scrapy <command> -h
2 有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
edit #编辑器,一般不用
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
bench #scrapy bentch压力测试
选择一个项目的工程目录,创建项目:
scrapy startproject ArticleSpider

cd ArticleSpider\ scrapy genspider jobbole blog.jobbole.com
用Pycharm打开项目进行编写
设置用于调试的启动脚本main

# -*- coding:utf-8 -*- from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(['scrapy', 'crawl', 'jobbole'])
import os p1 = os.path.abspath(__file__) # 当前文件的路径 print(p1) # D:\Workspace\ArticleSpider\ArticleSpider\test.py p2 = os.path.dirname(os.path.abspath(__file__)) # 当前文件路径的上一级路径 print(p2) # D:\Workspace\ArticleSpider\ArticleSpider
在setting.py里把robots协议项设置为Flase
ROBOTSTXT_OBEY = False
XPATH
xpath基础语法:http://www.cnblogs.com/0bug/p/8903668.html
开始编写爬虫
编写jobbole.py,初始url设置为 http://blog.jobbole.com/110287/
# -*- coding: utf-8 -*-
import scrapy
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/110287/']
def parse(self, response):
pass
启动scrapy shell
scrapy shell http://blog.jobbole.com/110287/
用xpath来找标题

>>> title = response.xpath('//div[@class="entry-header"]/h1/text()')
>>> title
[<Selector xpath='//div[@class="entry-header"]/h1/text()' data='2016 腾讯软件开发面试题(部分)'>]
>>> title.extract()
['2016 腾讯软件开发面试题(部分)']
>>> title.extract()[0]
'2016 腾讯软件开发面试题(部分)'
用css选择器的写法:
>>> title = response.css('.entry-header h1::text').extract()
>>> title
['2016 腾讯软件开发面试题(部分)']
>>> title = response.css('.entry-header h1::text').extract()[0]
>>> title
'2016 腾讯软件开发面试题(部分)'
通过xpath提取文章的具体字段
def parse(self, response):
# 提取文章的具体字段
import re
title = response.xpath('//div[@class="entry-header"]/h1/text()').extract_first("")
create_date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
praise_nums = response.xpath("//span[contains(@class, 'vote-post-up')]/h10/text()").extract()[0]
fav_nums = response.xpath("//span[contains(@class, 'bookmark-btn')]/text()").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.xpath("//a[@href='#article-comment']/span/text()").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.xpath("//div[@class='entry']").extract()[0]
tag_list = response.xpath("//p[@class='entry-meta-hide-on-mobile']/a/text()").extract()
tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
tags = ",".join(tag_list)
通过css选择器提取文档的具体字段
def parse(self, response):
# 通过css选择器提取字段
import re
front_image_url = response.meta.get("front_image_url", "") # 文章封面图
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·", "").strip()
praise_nums = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css(".bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = int(match_re.group(1))
else:
fav_nums = 0
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = int(match_re.group(1))
else:
comment_nums = 0
content = response.css("div.entry").extract()[0]
tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract()
tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
tags = ",".join(tag_list)
pass
Python3.6+Scrapy爬取知名技术文章网站的更多相关文章
- 第4章 scrapy爬取知名技术文章网站(2)
4-8~9 编写spider爬取jobbole的所有文章 # -*- coding: utf-8 -*- import re import scrapy import datetime from sc ...
- 第4章 scrapy爬取知名技术文章网站(1)
4-1 scrapy安装以及目录结构介绍 安装scrapy可以看我另外一篇博文:Scrapy的安装--------Windows.linux.mac等操作平台,现在是在虚拟环境中安装可能有不同. 1. ...
- 用scrapy爬取亚马逊网站项目
这次爬取亚马逊网站,用到了scrapy,代理池,和中间件: spiders里面: # -*- coding: utf-8 -*- import scrapy from scrapy.http.requ ...
- 使用scrapy爬取jian shu文章
settings.py中一些东西的含义可以看一下这里 python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 & ...
- 爬虫框架之Scrapy——爬取某招聘信息网站
案例1:爬取内容存储为一个文件 1.建立项目 C:\pythonStudy\ScrapyProject>scrapy startproject tenCent New Scrapy projec ...
- Scrapy爬取伯乐在线文章
首先搭建虚拟环境,创建工程 scrapy startproject ArticleSpider cd ArticleSpider scrapy genspider jobbole blog.jobbo ...
- 第5章 scrapy爬取知名问答网站
第五章感觉是第四章的练习项目,无非就是多了一个模拟登录. 不分小节记录了,直接上知识点,可能比较乱. 1.常见的httpcode: 2.怎么找post参数? 先找到登录的页面,打开firebug,输入 ...
- scrapy爬取伯乐在线文章数据
创建项目 切换到ArticleSpider目录下创建爬虫文件 设置settings.py爬虫协议为False 编写启动爬虫文件main.py
- 一文搞定scrapy爬取众多知名技术博客文章保存到本地数据库,包含:cnblog、csdn、51cto、itpub、jobbole、oschina等
本文旨在通过爬取一系列博客网站技术文章的实践,介绍一下scrapy这个python语言中强大的整站爬虫框架的使用.各位童鞋可不要用来干坏事哦,这些技术博客平台也是为了让我们大家更方便的交流.学习.提高 ...
随机推荐
- 【转载】 程序员制作996.icu网站抗议加班,你认为996能提高工作效率吗?
原文地址: https://zhidao.baidu.com/question/623053193192988612.html ------------------------------------ ...
- SQL*Plus连接符拼接输出
在日常工作中,可能需要使用重复的命令,修改的只是某个不同字段的值,可以使用连接字符串进行拼接 #本篇文档: 一.使用连接符拼接SQL 二.Spool输出查询结果 三.Spool输出xml/ html ...
- ROI-Align解决方案
https://yq.aliyun.com/articles/558181 Mask R-CNN与Faster R-CNN相似,Faster R-CNN是two-stage的,其中第一个stage是R ...
- 08 正则表达式,Math类,Random,System类,BigInteger,BigDecimal,Date,DateFormat,Calendar
正则表达式: 是指一个用来描述或者匹配一系列符合某个语法规则的字符串的单个字符串.其实就是一种规则.有自己特殊的应用. public class Demo2_Regex { public sta ...
- 【杭电OJ3938】【离线+并查集】
http://acm.hdu.edu.cn/showproblem.php?pid=3938 Portal Time Limit: 2000/1000 MS (Java/Others) Memo ...
- hdu2509 Be the Winner 博弈
Let's consider m apples divided into n groups. Each group contains no more than 100 apples, arranged ...
- maven 总结整理(二)——download source code
当我们用maven下载jar包时,有时希望下载jar包的源代码,此时可以在pom.xml文件中,进行设置. <build> <finalName>WebProject&l ...
- doubleclick protobuf file load to project
1,download protobuf file to local wget https://developers.google.com/ad-exchange/rtb/downloads/openr ...
- Linux内核启动分析笔记
一.驱动加载 1.驱动加载调用关系 start_kernel //init/main.c rest_init //最后执行它 kernel_init //使用kernel_thread创建一个进程执行 ...
- 使用ipns 为ipfs 系统自定义域名
ipns 可以帮助我们进行寻址操作,但是默认的hashid 还是太长,不好记忆,ipns 同时也支持 基于域名的解析,我们添加txt 记录就可以方便的解决ipfs 文件访问地址难记的问题,使用的是 一 ...