第5章 scrapy爬取知名问答网站
第五章感觉是第四章的练习项目,无非就是多了一个模拟登录。
不分小节记录了,直接上知识点,可能比较乱。
1.常见的httpcode:
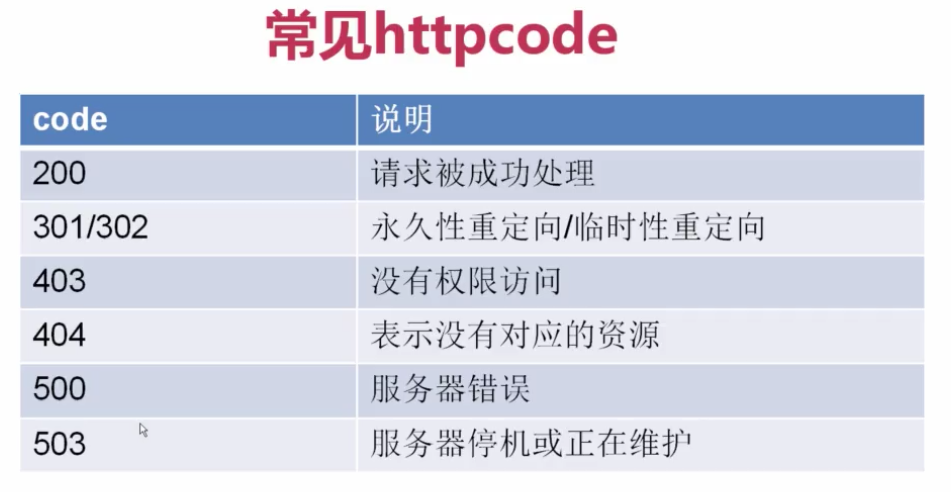
2.怎么找post参数?
先找到登录的页面,打开firebug,输入错误的账号和密码,观察post_url变换,从而确定参数。
3.读取本地的文件,生成cookies。
try:
import cookielib #py2
except:
import http.cookiejar as cookielib #py3
4.用requests登录知乎
# -*- coding: utf-8 -*-
__author__ = 'jinxiao' import requests
try:
import cookielib
except:
import http.cookiejar as cookielib import re session = requests.session() #实例化session,下面的requests可以直接换成session
session.cookies = cookielib.LWPCookieJar(filename="cookies.txt") #实例化cookies,保存cookies
#读取cookies
try:
session.cookies.load(ignore_discard=True)
except:
print ("cookie未能加载") #知乎一定要加上浏览器的头,其他网站不一定,一般都是要的
agent = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0"
header = {
"HOST":"www.zhihu.com",
"Referer": "https://www.zhizhu.com",
'User-Agent': agent
} def is_login():
#通过个人中心页面返回状态码来判断是否为登录状态
inbox_url = "https://www.zhihu.com/question/56250357/answer/148534773"
response = session.get(inbox_url, headers=header, allow_redirects=False) #禁止重定向,判断为是否登录
if response.status_code != 200:
return False
else:
return True def get_xsrf():
#获取xsrf code
response = session.get("https://www.zhihu.com", headers=header)
match_obj = re.match('.*name="_xsrf" value="(.*?)"', response.text)
if match_obj:
return (match_obj.group(1))
else:
return "" def get_index():
response = session.get("https://www.zhihu.com", headers=header)
with open("index_page.html", "wb") as f:
f.write(response.text.encode("utf-8"))
print ("ok") def zhihu_login(account, password):
#知乎登录
if re.match("^1\d{10}",account):
print ("手机号码登录")
post_url = "https://www.zhihu.com/login/phone_num"
post_data = {
"_xsrf": get_xsrf(),
"phone_num": account,
"password": password
}
else:
if "@" in account:
#判断用户名是否为邮箱
print("邮箱方式登录")
post_url = "https://www.zhihu.com/login/email"
post_data = {
"_xsrf": get_xsrf(),
"email": account,
"password": password
} response_text = session.post(post_url, data=post_data, headers=header)
session.cookies.save() zhihu_login("", "admin123")
# get_index()
print(is_login())
zhihu_requests_login
5.在shell调试中添加UserAgent
scrapy shell -s USER_AGENT='...' url
6.JsonView插件
可以很好的可视化看json
7.写入html文件
with open(''e:/zhihu.html'',"wb") as f:
f.write(response.text.encode('utf-8'))
8.yield理解
如果是yield item 会到pipelins中处理
如果是yield Request 会到下载器去下载
9.在mysql中怎么去重,设置主键去重,主键冲突
解决:在插入的sql语句后面加上 ON DUPLICATE KEY UPDATE content=VALUES(content) #这是需要更新的内容
10.手动输入验证码(zhihu.login_requests.py)
def get_captcha():
import time
t=str(int(time.time()*1000))
captcha_url="https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t)
t=session.get(captcha_url,headers=header)
with open("captcha.jpg","wb") as f:
f.write(t.content)
f.close()
captcha=input("输入验证码:")
return captcha
#为什么是第五行是session,而不是requests?
#因为requests会重新建立一次绘画 session,这与后面的参数不符,输入的验证码并不是当前的验证码。
作者:今孝
出处:http://www.cnblogs.com/jinxiao-pu/p/6749332.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
第5章 scrapy爬取知名问答网站的更多相关文章
- 第4章 scrapy爬取知名技术文章网站(2)
4-8~9 编写spider爬取jobbole的所有文章 # -*- coding: utf-8 -*- import re import scrapy import datetime from sc ...
- 第4章 scrapy爬取知名技术文章网站(1)
4-1 scrapy安装以及目录结构介绍 安装scrapy可以看我另外一篇博文:Scrapy的安装--------Windows.linux.mac等操作平台,现在是在虚拟环境中安装可能有不同. 1. ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
- Python3.6+Scrapy爬取知名技术文章网站
爬取分析 伯乐在线已经提供了所有文章的接口,还有下一页的接口,所有我们可以直接爬取一页,再翻页爬. 环境搭建 Windows下安装Python: http://www.cnblogs.com/0bug ...
- Python网络爬虫 | Scrapy爬取妹子图网站全站照片
根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地. 网站的分析 网页的网址分析 打开网站,发现网页的网址都是以 http://www.mei ...
- Scrapy爬取某装修网站部分装修效果图
爬取图片资源 spider文件 from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpid ...
- 44.scrapy爬取链家网站二手房信息-2
全面采集二手房数据: 网站二手房总数据量为27650条,但有的参数字段会出现一些问题,因为只给返回100页数据,具体查看就需要去细分请求url参数去请求网站数据.我这里大概的获取了一下筛选条件参数,一 ...
- 43.scrapy爬取链家网站二手房信息-1
首先分析:目的:采集链家网站二手房数据1.先分析一下二手房主界面信息,显示情况如下: url = https://gz.lianjia.com/ershoufang/pg1/显示总数据量为27589套 ...
随机推荐
- uwp获取版本信息win10 VersionInfo
using Windows.System.Profile; Después vamos a agregar una propiedad que va a contener un mensaje con ...
- js日期转换工具
var dq = new Date();//定义当前时间var sDueDate = formatDate(dq);/调用日期转换方法 传入当前时间 //进行日期转换 function formatD ...
- [uwp]自定义图形裁切控件
开始之前,先上一张美图.图中的花叫什么,我已经忘了,或者说从来就不知道,总之谓之曰“野花”.只记得花很美,很香,春夏时节,漫山遍野全是她.这大概是七八年前的记忆了,不过她依旧会很准时的在山上沐浴春光, ...
- Mysql 中日期类型bigint和datetime互转
MySql数据库中字段类型bigint 长度是10位的 mysql> select (from_unixtime(1554047999))as datatime;+--------------- ...
- Java中运算符“|”和“||”以及“&”和“&&”区别
1.“|”运算符:不论运算符左侧为true还是false,右侧语句都会进行判断,下面代码 int a =1,b=1; if(a++ == 1 | ++b == 2) System.out.printl ...
- vue 路由传参
mode:路由的形式 用的哪种路由 1.hash 路由 会带#号的哈希值 默认是hash路由 2.history路由 不会带#的 单页面开发首屏加载慢怎么解决?单页面开发首屏加载白屏怎 ...
- 队列的理解和实现(二) ----- 链队列(java实现)
什么是链队列 链队是指采用链式存储结构实现的队列,通常链队用单链表俩表示.一个链队显然需要两个分别指示队头和队尾的指针,也称为头指针和尾指针,有了这两个指针才能唯一的确定. package 链队列; ...
- iOS应用发布中的一些细节
iOS应用发布中的一些细节 前言 这几天最大的新闻我想就是巴黎恐怖袭击了,诶,博主每年跨年都那么虔诚地许下“希望世界和平”的愿望,想不到每年都无法实现,维护世界和平这么难,博主真是有心无力啊,其实芸芸 ...
- Camera Sensor
camera sensor分为YUV sensor和Bayer sensor. YUV Sensor YUV Sensor输出的格式是YUV,图像的处理效果使用sensor内部的ISP,BB端接收到的 ...
- 直接线性变换解法(DLT)用于标定相机
直接线性变换法是建立像点坐标和相应物点物方空间坐标之间直接的线性关系的算法.特点:不需要内外方位元素:适合于非量测相机:满足中.低精度的测量任务:可以标定单个相机. 1 各坐标系之间的关系推导直接线性 ...