【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了。
工具
1.Python 2.7
2.BeautifulSoup
分析网页
我们先来看看知乎上该网页的情况:
网址:  ,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了。
,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了。
再来看一下我们要爬取的内容:
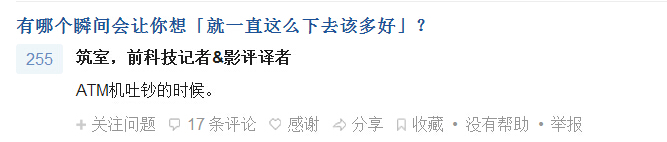
我们要爬取两个内容:问题和回答,回答仅限于显示了全部内容的回答,如下面这种就不能爬取,因为好像无法展开(反正我不会。。),再说答案不全的话爬来也没用,所以就不爬答案不全的了吧。

好,那么下面我们要找到他们在网页源代码中的位置:

即我们找到问题的内容包含在<h2 class = "zm-item-title"><a tar...>中,那么我们等会就可以在这个标签里面找问题。
然后是回复:

有两个地方都有回复的内容,因为上面那个的内容还包括了<span..>等一些内容,不方便处理,我们爬下面那个的内容,因为那个里面的内容纯正无污染。
修正前代码
好,这时候我们试着写出python代码:
# -*- coding: cp936 -*-
import urllib2
from BeautifulSoup import BeautifulSoup f = open('howtoTucao.txt','w') #打开文件 for pagenum in range(1,21): #从第1页爬到第20页 strpagenum = str(pagenum) #页数的str表示
print "Getting data for Page " + strpagenum #shell里面显示的,表示已爬到多少页
url = "http://www.zhihu.com/collection/27109279?page="+strpagenum #网址
page = urllib2.urlopen(url) #打开网页
soup = BeautifulSoup(page) #用BeautifulSoup解析网页 #找到具有class属性为下面两个的所有Tag
ALL = soup.findAll(attrs = {'class' : ['zm-item-title','zh-summary summary clearfix'] }) for each in ALL : #枚举所有的问题和回答
#print type(each.string)
#print each.name
if each.name == 'h2' : #如果Tag为h2类型,说明是问题
print each.a.string #问题中还有一个<a..>,所以要each.a.string取出内容
if each.a.string: #如果非空,才能写入
f.write(each.a.string)
else : #否则写"No Answer"
f.write("No Answer")
else : #如果是回答,同样写入
print each.string
if each.string:
f.write(each.string)
else :
f.write("No Answer")
f.close() #关闭文件
代码虽然不常,可是写了我半天,开始各种出问题。
运行
然后我们运行就可以爬了:
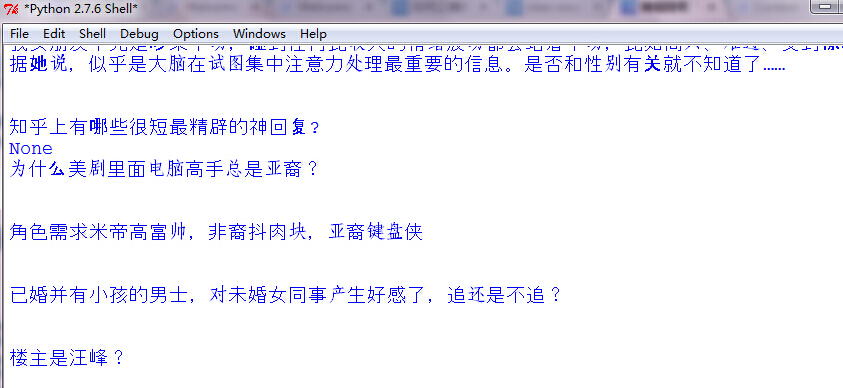
修正前结果
等运行完毕,我们打开文件howtoTucao.txt,可以看到,这样就爬取成功了。只是格式可能还是有点问题,原来是我No Answer没加换行,所以No Answer还会混到文本里面去,加两个换行就可以了。
结果在这 : 点我
说明
有朋友说好像这个内容有人写过 : http://www.cnblogs.com/fengfenggirl/p/zhihu_shenhuifu.html
他跟我写的不同,大家也可以看看,这里并无借鉴与抄袭。
优化及修正
文章发出后,收到了一些朋友,前辈的指导,进行了修正:
1.可以爬取全部内容
2.格式的修正
由上图我们知道,全部内容是在content hidden中的,之前我因为不知道如何处理<span..那一段,所以就没有爬全部内容,而是简略地爬取了部分内容。
其实去掉那一段并不难,用正则表达式匹配:
nowstring = re.sub('<s.+>\n<a.+>\n<.+>\n','',each.a.string)
即可。
然后就是一些格式的整理,由下图我们看到,爬取出的内容会有很多<..> 这只有html才能够解析,放到txt文件中就不能解析,从而出现这些字符,影响阅读,所以我们也用正则将它们去掉。

除了<br>用换行符代替外,其余的我们都用''空串来代替,并且将图片等也换掉。
修正后代码
# -*- coding: cp936 -*-
import urllib2
import re
from BeautifulSoup import BeautifulSoup f = open('howtoTucao.txt','w') #open the file for pagenum in range(1,21): strpagenum = str(pagenum)
print "Getting data for Page " + strpagenum #for we can see the process in shell
url = "http://www.zhihu.com/collection/27109279?page="+strpagenum
page = urllib2.urlopen(url) #get the web page
soup = BeautifulSoup(page) #use BeautifulSoup to parsing the web page ALL = soup.findAll(attrs = {'class' : ['zm-item-title','content hidden'] }) for each in ALL :
if each.name == 'h2' :
nowstring = re.sub('<s.+>\n<a.+>\n<.+>\n','',each.a.string)
nowstring = re.sub('<br>','\n',nowstring)
nowstring = re.sub('<\w+>','',nowstring)
nowstring = re.sub('</\w+>','',nowstring)
nowstring = re.sub('<.+>','\n图片\n',nowstring)
nowstring = re.sub('"','"',nowstring)
print nowstring
if nowstring:
f.write(nowstring)
else :
f.write("\n No Answer \n")
else :
nowstring = re.sub('<s.+>\n<a.+>\n<.+>\n','',each.string)
nowstring = re.sub('<br>','\n',nowstring)
nowstring = re.sub('<\w+>','',nowstring)
nowstring = re.sub('</\w+>','',nowstring)
nowstring = re.sub('<.+>','\n图片\n',nowstring)
nowstring = re.sub('"','"',nowstring)
print nowstring
if nowstring:
f.write(nowstring)
else :
f.write("\n No Answer \n")
f.close() #close the file
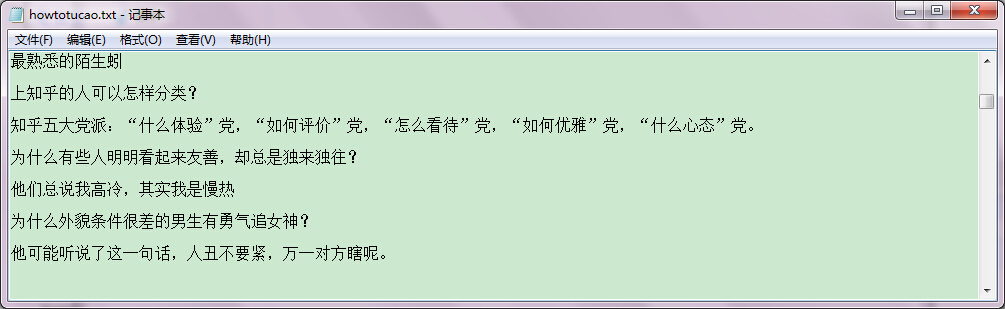
修正后结果

这样就可以了。
感谢网友 Anonymous Coward , 盛强 提供建议!
结果可在我的github中查看。
【Python数据分析】简单爬虫 爬取知乎神回复的更多相关文章
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- Python编写网页爬虫爬取oj上的代码信息
OJ升级,代码可能会丢失. 所以要事先备份. 一開始傻傻的复制粘贴, 后来实在不能忍, 得益于大潇的启示和聪神的原始代码, 网页爬虫走起! 已经有段时间没看Python, 这次网页爬虫的原始代码是 p ...
- 【Python】简单实现爬取小说《天龙八部》,并在页面本地访问
背景 很多人说学习爬虫是提升自己的一个非常好的方法,所以有了第一次使用爬虫,水平有限,依葫芦画瓢,主要作为学习的记录. 思路 使用python的requests模块获取页面信息 通过re模块(正则表达 ...
- 用python写一个爬虫——爬取性感小姐姐
忍着鼻血写代码 今天写一个简单的网上爬虫,爬取一个叫妹子图的网站里面所有妹子的图片. 然后试着先爬取了三页,大概有七百多张图片吧!各个诱人的很,有兴趣的同学可以一起来爬一下,大佬级程序员勿喷,简单爬虫 ...
- Python写网络爬虫爬取腾讯新闻内容
最近学了一段时间的Python,想写个爬虫,去网上找了找,然后参考了一下自己写了一个爬取给定页面的爬虫. Python的第三方库特别强大,提供了两个比较强大的库,一个requests, 另外一个Bea ...
- Python超简单的爬取网站中图片
1.首先导入相关库 import requests import bs4 import threading #用于多线程爬虫,爬取速度快,可以完成多页爬取 import os 2.使用bs4获取htm ...
- 简单爬虫-爬取免费代理ip
环境:python3.6 主要用到模块:requests,PyQuery 代码比较简单,不做过多解释了 #!usr/bin/python # -*- coding: utf-8 -*- import ...
- PHP简单爬虫 爬取免费代理ip 一万条
目标站:http://www.xicidaili.com/ 代码: <?php require 'lib/phpQuery.php'; require 'lib/QueryList.php'; ...
随机推荐
- mongodb系列3 mongo mongoskin 连接以及连接数的问题进阶
1)使用mongodb连接mongo var mongo = require('mongodb'), //引入mongodb dbHost = '127.0.0.1', dbPort = 27017; ...
- 完美卸载oracle11g步骤
完美卸载oracle11g步骤:1. 开始->设置->控制面板->管理工具->服务 停止所有Oracle服务.2. 开始->程序->Oracle - OraHome ...
- SharePoint 2013 为用户组自定义EventReceiver
前 言 在SharePoint的开发中,EventReceiver是很重要的一个部分,但是,常常遇到有些需要事件的时候,却没有相应的模板,因为EventReceiver创建时的模板只有那几个,除此之外 ...
- Oracle11gR2用EXP导出时报EXP-00011错误的解决
C:\>exp businessdata/businessdata file=dropcol.dmp tables=ACSTRULE,ARREARSCFG,ARREARS_REPORT_ACCT ...
- 关于iOS中的时间
两类 绝对时间 [NSDate date].CFAbsoluteTimeGetCurrent(),或者gettimeofday(). 返回的是从某一个时刻开始,度过的秒数.会随着用户设置的系统时间更改 ...
- iOS设置文字过长时的显示格式
以label为例: //设置文字过长时的显示格式 aLabel.lineBreakMode = UILineBreakModeMiddleTruncation; //截去中间 aLabel.lineB ...
- warning 当xcode里点运行出现treating unicode character as whites
可能是由于粘贴网页上的代码的时候两行之间的回车引起的,两行之间重新输入回车就行......删掉重新写一遍就ok了
- 【代码笔记】iOS-判断是否是iPhone5
一,代码. #import "RootViewController.h" // 判断是否是iPhone5 #define iPhone5 ([UIScreen instancesR ...
- 打电话、发短信、web以及发邮件
#import "ViewController.h" #import <MessageUI/MessageUI.h> //导入信息UI库 @interface View ...
- unity安卓和IOS读写目录
StreamingAssets文件夹下的只读不可写路径: 安卓读:filePath = Application.streamingAssetsPath + "/文件名.格式名"; ...