Kafka高性能揭秘:sequence IO、PageCache、SendFile的应用详解
大家都知道Kafka是将数据存储于磁盘的,而磁盘读写性能往往很差,但Kafka官方测试其数据读写速率能达到600M/s,那么为什么Kafka性能会这么高呢?
首先producer往broker发送消息时,采用batch的方式即批量而非一条一条的发送,这种方式可以有效降低网络IO的请求次数,提升性能。此外这些批次消息会"暂存"在缓冲池中,避免频繁的GC问题。批量发送的消息可以进行压缩并且传输的时候可以进行高效的序列化,从而减少数据大小。
Kafka除了在producer发送消息方面做了很多优化,还有很多其他的优化,比如Kafka利用了sequence IO、PageCache、SendFile这3种处理方案:
sequence IO
首先来了解一下磁盘的特性:快速顺序读写、慢速随机读写。因为磁盘是典型的IO块设备,每次读写都会经历寻址,其中寻址中寻道是比较耗时的。随机读写会导致寻址时间延长,从而影响磁盘的读写速度。
大家有没有想过MapReduce进行shuffle的时候,为什么map端和reduce端要进行排序,不排序不也不影响正常业务的处理,排序反而因为消耗资源增加了处理时间?
以map端为例,执行过程中会产生很多小文件,这些小文件要经历归并排序等一系列处理后才会被reduce端进行处理。提前对未合并的文件进行排序正是利用了磁盘快速顺序读写的特性来提高归并排序的速度。
而Kafka在将数据持久化到磁盘时,采用只追加的顺序写,有效降低了寻址时间,提高效率。下图展示了Kafka写入数据到partition的方式:
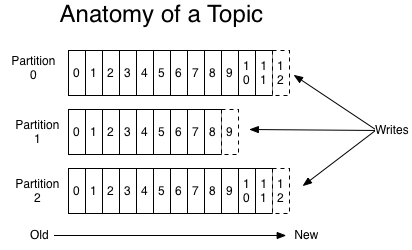
可以看到Kafka会将数据插入到文件末尾,并且Kafka不会"直接"删除数据,而是把所有数据保存到磁盘,每个consumer会指定一个offset来记录自己订阅的topic的partition中消费的位置。当然我们可以设置策略来清理数据,比如通过参数log.retention.hours指定过期时间,当达到过期时间时,Kafka会清理数据。
PageCache
PageCache是系统级别的缓存,它把尽可能多的空闲内存当作磁盘缓存使用来进一步提高IO效率,同时当其他进程申请内存,回收PageCache的代价也很小。
当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
PageCache同时可以避免在JVM内部缓存数据,避免不必要的GC、以及内存空间占用。对于In-Process Cache,如果Kafka重启,它会失效,而操作系统管理的PageCache依然可以继续使用。
对应到Kafka生产和消费消息中:
producer把消息发到broker后,数据并不是直接落入磁盘的,而是先进入PageCache。PageCache中的数据会被内核中的处理线程采用同步或异步的方式写回到磁盘。
Consumer消费消息时,会先从PageCache获取消息,获取不到才回去磁盘读取,并且会预读出一些相邻的块放入PageCache,以方便下一次读取
如果Kafka producer的生产速率与consumer的消费速率相差不大,那么几乎只靠对broker PageCache的读写就能完成整个生产和消费过程,磁盘访问非常少。
SendFile
传统的网络I/O过程:
1. 操作系统从磁盘把数据读到内核区
2. 用户进程把数据从内核区copy到用户区
3. 然后用户进程再把数据写入到socket,数据流入内核区的Socket Buffer上
4. 最后把数据从socket Buffer中发送到到网卡,这样完成一次发送
可以发现,同一份数据在内核Buffer与用户Buffer之间拷贝两次:
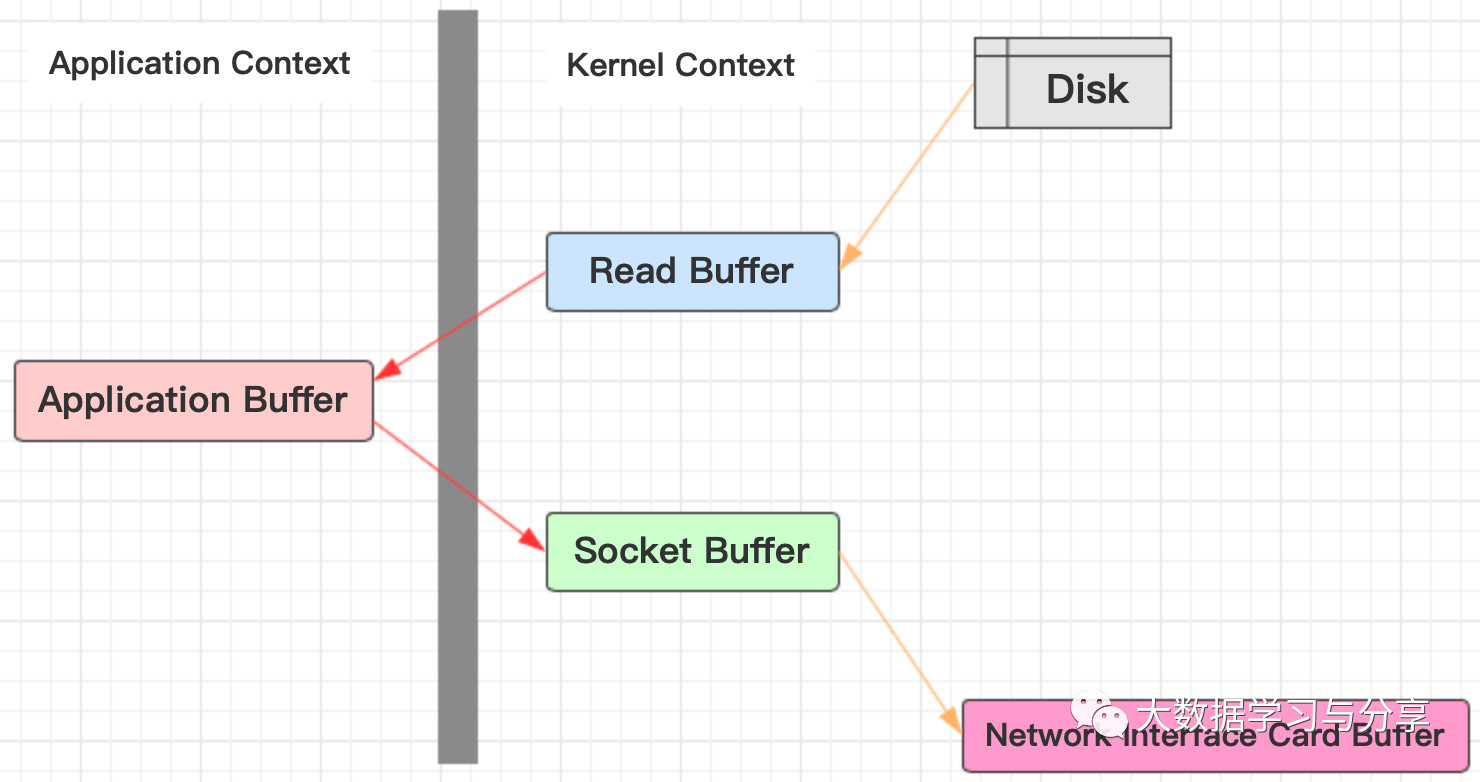
但是通过SendFile(又称zero copy)优化后,直接把数据从内核区copy到socket,然后发送到网卡,避免了在内核Buffer与用户Buffer来回拷贝的弊端:
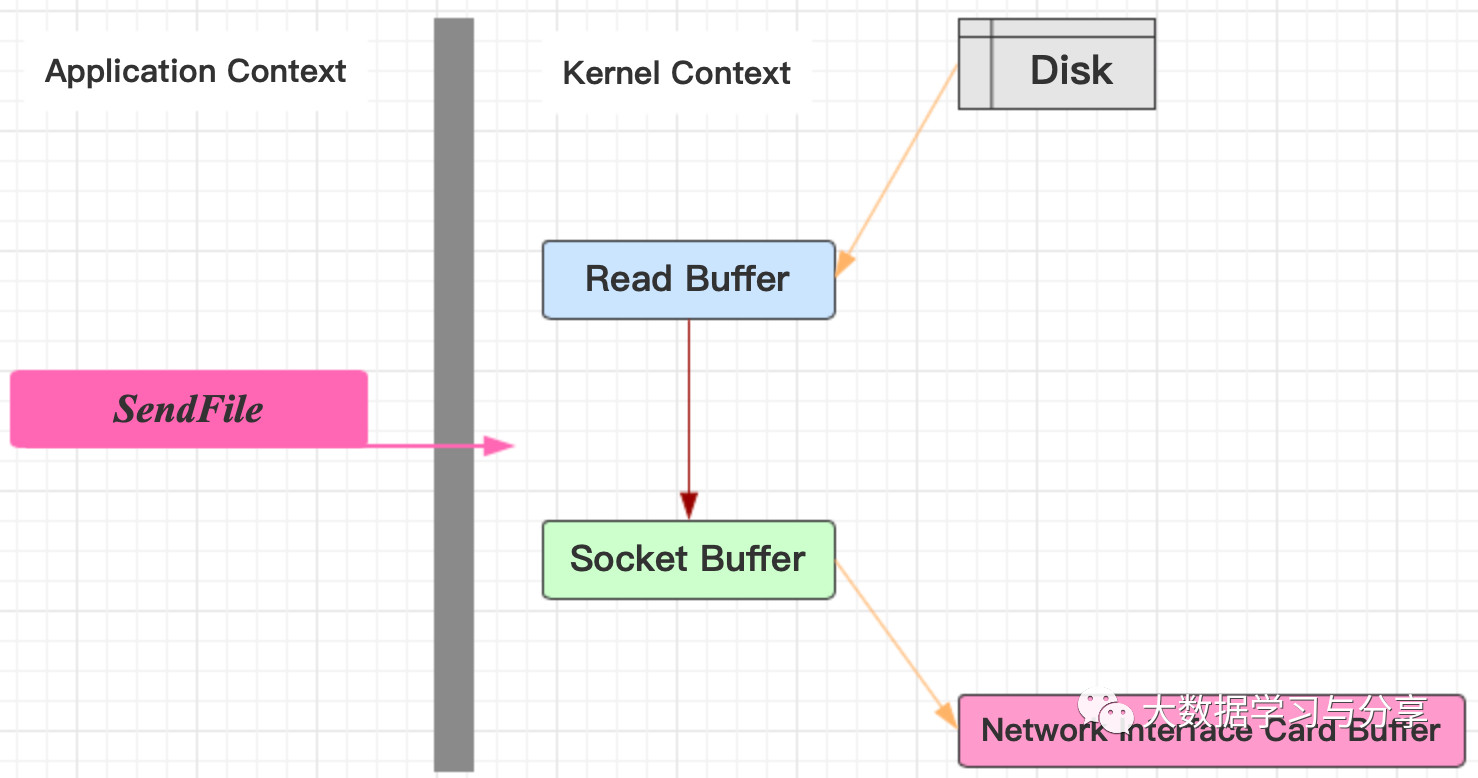
不仅是Kafka,Java的NIO提供的FileChannle,它的transferTo、transferFrom方法也利用了这种在内核区完成数据传输的功能。
关注微信公众号:大数据学习与分享,获取更对技术干货
Kafka高性能揭秘:sequence IO、PageCache、SendFile的应用详解的更多相关文章
- kafka原理和实践(五)spring-kafka配置详解
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕
Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕 今天会逐行解析一下SparkStreaming运行的日志,运行的是WordCountO ...
- kafka的server.properties配置文件参考示范(图文详解)(多种方式)
简单点的,就是 kafka_2.11-0.8.2.2.tgz的3节点集群的下载.安装和配置(图文详解) 但是呢,大家在实际工作中,会一定要去牵扯到调参数和调优问题的.以下,是我给大家分享的kafka的 ...
- IO测试工具之fio详解
目前主流的第三方IO测试工具有fio.iometer和Orion,这三种工具各有千秋. fio在Linux系统下使用比较方便,iometer在window系统下使用比较方便,Orion是oracle的 ...
- IO测试工具之fio详解(转)
http://www.cnblogs.com/raykuan/p/6914748.html 目前主流的第三方IO测试工具有fio.iometer和Orion,这三种工具各有千秋. fio在Linux系 ...
- .net System.IO之Stream的使用详解
本篇文章是对.Net中System.IO之Stream的使用进行了详细的分析介绍,需要的朋友参考下 Stream在msdn的定义:提供字节序列的一般性视图(provides a generic vie ...
- Hadoop IO基于文件的数据结构详解【列式和行式数据结构的存储策略】
Charles所有关于hadoop的文章参考自hadoop权威指南第四版预览版 大家可以去safari免费阅读其英文预览版.本人也上传了PDF版本在我的资源中可以免费下载,不需要C币,点击这里下载. ...
- java IO、NIO、AIO详解
概述 在我们学习Java的IO流之前,我们都要了解几个关键词 同步与异步(synchronous/asynchronous):同步是一种可靠的有序运行机制,当我们进行同步操作时,后续的任务是等待当前调 ...
- 【转】Linux IO实时监控iostat命令详解
转自:http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858810.html 简介 iostat主要用于监控系统设备的IO负载情况,iosta ...
随机推荐
- spring-boot-route(十七)使用aop记录操作日志
在上一章内容中--使用logback管理日志,我们详细讲述了如何将日志生成文件进行存储.但是在实际开发中,使用文件存储日志用来快速查询问题并不是最方便的,一个优秀系统除了日志文件还需要将操作日志进行持 ...
- faker切换user-agent
import random import requests url = "http://tool.yeves.cn" import faker fake = faker.Faker ...
- 树莓派调试PCF8591遇到的小问题
错误提示:bus = smbus.SMBus(1) IOError: [Errno 2] No such file or directory 提示的内容为端口没有打开即IIC端口:如图,打开IIC使能 ...
- sql左连接查询+右表带有条件的实现
select * from A表 a left join B表 b on a.id=b.a_id and b.字段='/*条件*/' ; 可查出左表所有数据 select * from A表 a le ...
- MVC单文件上传
前言 现在来写下最基础的单文件上传,完成后可以扩展成各种不同的上传方式 HTML <input id="Input_File" type="file" / ...
- kubernetes教程第一章-kubeadm高可用安装k8s集群
目录 Kubeadm高可用安装k8s集群 kubeadm高可用安装1.18基本说明 k8s高可用架构解析 kubeadm基本环境配置 kubeadm基本组件安装 kubeadm集群初始化 高可用Mas ...
- 函数-深入JS笔记
代码特点:高内聚,低耦合 耦合 存在执行多个相同作用代码时,这就叫耦合 if (1 > 0) { console.log('a'); } if (2 > 0) { console.log( ...
- (CVPR 2019)The better version of SRMD
CVPR2019的文章,解决SRMD的诸多问题, 并进行模拟实验. 进行双三次差值(bicubic)===>对应matlab imresize() %% read images im = {}; ...
- 如何計算n個圓的聯集面積
如何計算n個圓的聯集面積 前言 一般人第一次遇到這個問題,可能會想要想辦法用排容原理,找圓之間交疊的凸包之類的.... 然而我只要舉一個例子,你就會發現我們就算把凸包找出來了,我們也非常難知道找到的凸 ...
- Redis---07主从复制(哨兵模式)
一.什么是哨兵模式 基于主从复制的一般模式(一主二从)下,当发生主机发生宕机时,会通过流言协议判断主机是不是宕机,是的话则会通过投票协议自动把某一个从机转换成主机. 二.设置哨兵模式的配置文件 通过r ...