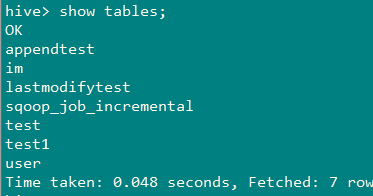
Sqoop(四)增量导入、全量导入、减量导入
增量导入
一、说明
当在生产环境中,我们可能会定期从与业务相关的关系型数据库向Hadoop导入数据,导入数仓后进行后续离线分析。这种情况下我们不可能将所有数据重新再导入一遍,所以此时需要数据增量导入。
增量导入数据分为两种方式:
一是基于递增列的增量数据导入(Append方式)。
二是基于时间列的数据增量导入(LastModified方式)。
二、增量导入
方式一:Append方式
比如:有一个订单表,里面每个订单有一个唯一标识自增列ID,在关系型数据库中以主键形式存在,之前已经将id在1-3的编号的订单导入到了Hive中,现在一段时间后我们需要将近期产生的新的订单数据(id为4、5的两条数据)导入Hive,供后续数仓进行分析。此时我们只需要指定-incremental参数为append,-last-value参数为3即可。表示只从大于3后开始导入。
1、MYSQL建表
CREATE TABLE `appendTest` (
`id` int(11) ,
`name` varchar(255)
)
2、导入数据
insert into appendTest(id,name) values(1,'name1');
insert into appendTest(id,name) values(2,'name2');
insert into appendTest(id,name) values(3,'name3');
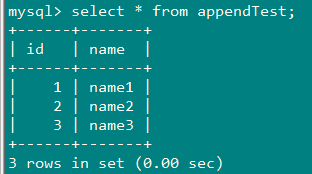
3、创建一张跟mysql中的appendTest表一样的hive表appendTest
sqoop create-hive-table \
--connect jdbc:mysql://192.168.200.100:3306/yang \
--username root \
--password 010209 \
--table appendTest \
--hive-table appendTest
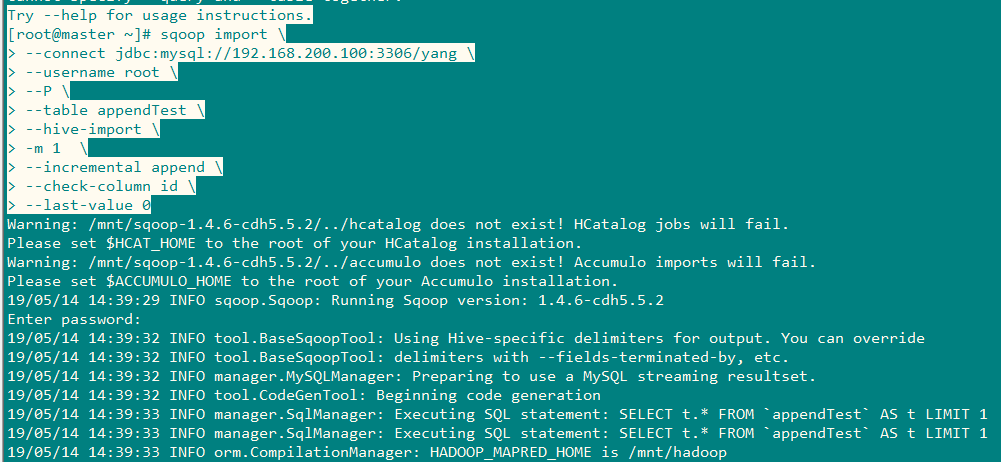
4、进行导入,将id>0的三条数据进行导入
sqoop import \
--connect jdbc:mysql://192.168.200.100:3306/yang \
--username root \
--P \
--table appendTest \
--hive-import \
-m 1 \
--hive-table appendTest \
--incremental append \
--check-column id \
--last-value 0
结果:


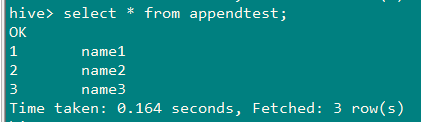
5、查看
6、向mysql表appendTest再次插入数据
insert into appendTest(id,name) values(4,'name4');
insert into appendTest(id,name) values(5,'name5');
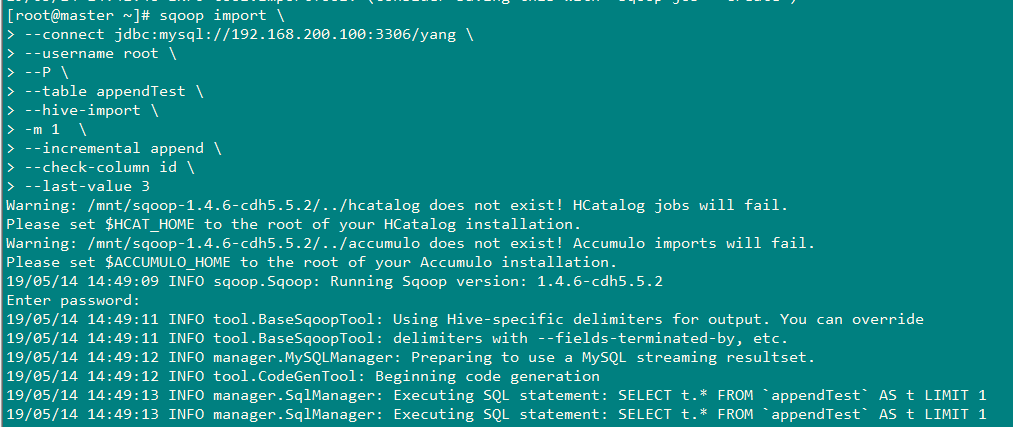
7、再次执行增量导入
由于上一次导入的时候,,将--last-value设置为0,将id>0的三条数据导入后,现在进行导入了时候需要将last-value设置为3
sqoop import \
--connect jdbc:mysql://192.168.200.100:3306/yang \
--username root \
--P \
--table appendTest \
--hive-import \
-m 1 \
--hive-table appendTest \
--incremental append \
--check-column id \
--last-value 3
结果:

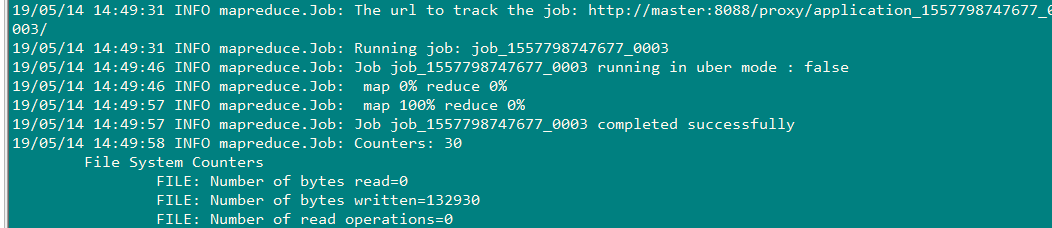
8、查看hive表appendTest
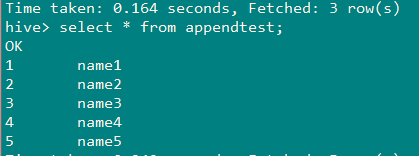
重要参数说明:
9、说明
说明:
增量抽取,需要指定--incremental append,同时指定按照源表中哪个字段进行增量--check-column id,
并指定hive表appendTest当前最大值--last-value 3。创建sqoop job的目的是,每次执行job以后,sqoop会自动记录appedndTest的last-value,
下次再执行时,就会自动指定last-value,不需要手工去改了。
方式二:lastModify方式
基于lastModify的方式,要求原表中有time字段,它能指定一个时间戳,让SQoop把该时间戳之后的数据导入至Hive,因为后续订单可能状态会发生变化,变化后time字段时间戳也会发生变化,此时SQoop依然会将相同状态更改后的订单导入Hive,当然我们可以指定merge-key参数为id,表示将后续新的记录与原有记录合并。
1、Mysql建表
CREATE TABLE lastModifyTest (
id INT,
name VARCHAR (20),
last_mod TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
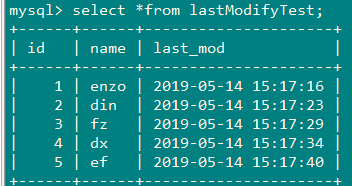
2、导入数据
insert into lastModifyTest(id,name) values(1,'enzo');
insert into lastModifyTest(id,name) values(2,'din');
insert into lastModifyTest(id,name) values(3,'fz');
insert into lastModifyTest(id,name) values(4,'dx');
insert into lastModifyTest(id,name) values(5,'ef');
3、HIve建表
sqoop create-hive-table \
--connect jdbc:mysql://192.168.200.100:3306/yang \
--username root \
--password 010209 \
--table lastModifyTest \
--hive-table lastModifyTest
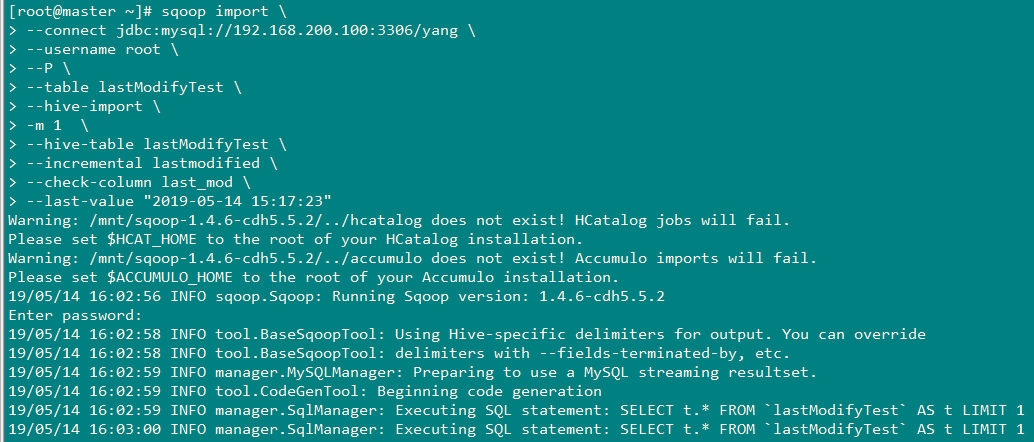
4、导入数据,将 时间以后的数据进行导入
时间以后的数据进行导入
sqoop import \
--connect jdbc:mysql://192.168.200.100:3306/yang \
--username root \
--P \
--table lastModifyTest \
--hive-import \
-m 1 \
--hive-table lastModifyTest \
--incremental lastmodified \
--check-column last_mod \
--last-value "2019-05-14 15:17:23"
结果:

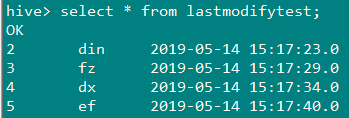
5、查看数据导入结果
6、参数说明

全量导入
将mysql表中全部数据都导入Hive,下面来查看实例:
1、MYSQL数据
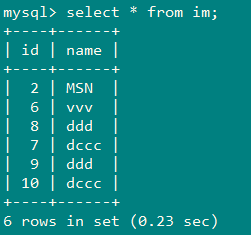
2、一次性将mysql表im数据全量导入hive中
sqoop import \
--connect jdbc:mysql://192.168.200.100:3306/yang \
--username root \
--password 010209 \
--table im \
--hive-import \
--hive-table im \
-m 1
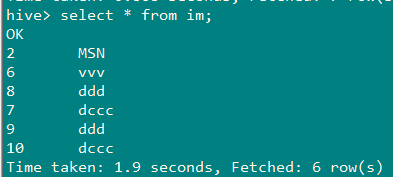
减量导入
设置where条件,通过判断条件可以判断减少的数据和增加的数据,控制更加灵活。
sqoop import \
--connect jdbc:mysql://192.168.200.100:3306/yang \
--username root \
--P \
--table appendTest \
--hive-import \
-m 1 \
--incremental append \
--where "age>30"
--check-column id \
--last-value 0
Sqoop(四)增量导入、全量导入、减量导入的更多相关文章
- hbase增量和全量备份
1.星期五全量备份星期四23:59:59的数据,星期一全量备份到星期日23:59:59的数据,其他的增量备份,备份前一天00:00:00 - 23:59:59的数据 * * /opt/prodfu ...
- solr-DIH:dataimport增量全量创建索引
索引创建完毕,就要考虑怎么定时的去重建, 除了写solrj,可以定时调用下面两条url进行增量或者全量创建索引 全量:http://ip:port/webapp_name/core_name/da ...
- mysql的全量备份与增量备份
mysql的全量备份与增量备份 全量备份:可以使用mysqldump直接备份整个库或者是备份其中某一个库或者一个库中的某个表. 备份所有数据库:[root@my ~]# mysqldump -uroo ...
- Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一.使用Logstash将mysql数据导入elasticsearch 1.在mysql中准备数据: mysql> show tables; +----------------+ | Table ...
- hadoop项目实战--ETL--(三)实现mysql表到HIVE表的全量导入与增量导入
一 在HIVE中创建ETL数据库 ->create database etl; 二 在工程目录下新建MysqlToHive.py 和conf文件夹 在conf文件夹下新建如下文件,最后的工程目录 ...
- sqoop1.4.6 全量导入与增量导入 与使用技巧
全量导入: sqoop import --connect jdbc:mysql://192.168.0.144:3306/db_blog --username root --password 1234 ...
- 10.Solr4.10.3数据导入(DIH全量增量同步Mysql数据)
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.创建MySQL数据 create database solr; use solr; DROP TABLE ...
- MySQL5.7.18 备份、Mysqldump,mysqlpump,xtrabackup,innobackupex 全量,增量备份,数据导入导出
粗略介绍冷备,热备,温暖,及Mysqldump,mysqlpump,xtrabackup,innobackupex 全量,增量备份 --备份的目的 灾难恢复:意外情况下(如服务器宕机.磁盘损坏等)对损 ...
- sqoop定时增量导入导出
sqoop定时增量导入 2013-11-06 14:23 4553人阅读 评论(0) 收藏 举报 sqoop使用hsql来存储job信息,开启metastor service将job信息共享,所有no ...
随机推荐
- fedora版本如何升级
自动升级 sudo dnf update --refresh # 更新系统包 sudo dnf install dnf-plugin-system-upgrade # 安装系统更新插件 sudo dn ...
- 第 6篇 Scrum 冲刺博客
一.站立式会议 1.站立式会议照片 2.昨天已完成的工作 完成了在数据库中对商品信息的查询 职工管理页面 3.今天计划完成的工作 完成对商品信息的分析 计划分析并编写职工信息模块代码 4.工作中遇到的 ...
- 题解 CF1375E Inversion SwapSort
蒟蒻语 这题是真的奇妙... 想了好久才想明白. 蒟蒻解 考虑冒泡排序是怎样的. 对于相邻的两个数 \(a_i, a_{i+1}\),如果 \(a_i>a_{i+1}\) 那么就交换两个数. 总 ...
- 2020/12月最新WinSpy/WinSpy++下载exe
>>>下载地址 https://wws.lanzous.com/iFUsVj931xa 密码:5hp7 解压密码:yunmuq 夹带私货:在这里希望大家分享文件别再用百度云了,不用百 ...
- redis学习之——redis.conf配置(基本)文件学习
# Redis configuration file example # Note on units: when memory size is needed, it is possible to sp ...
- 基于gin的golang web开发:实现用户登录
前文分别介绍过了Resty和gin-jwt两个包,Resty是一个HTTP和REST客户端,gin-jwt是一个实现了JWT的Gin中间件.本文将使用这两个包来实现一个简单的用户登录功能. 环境准备 ...
- PCRE正则表达式语法
字符 描述 \ 将下一个字符标记为一个特殊字符,或一个原义字符,或一个向后引用,或一个八进制转义符.例如,"\n"匹配一个换行符. ^ 匹配输入字符串的开始位置. $ 匹配输入字符 ...
- mysql批量刷新用户密码
不知道用户密码,并且不改变用户密码的情况下,批量刷新MySQL数据库用户的密码 select concat('alter user \'',user,'\'@\'',host,'\' identifi ...
- 高手查看Linux系统用户命令-测评
一.Linux查看用户命令-测评 查看linux所有的用户 cat /etc/passwd 查看普通用户.系统用户(1-499) root:x:0:0:root:/root:/bin/bash < ...
- Python开发:一个直播弹幕机器人诞生过程,自动发送弹幕
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. Python爬取B站弹幕视频讲解 https://www.bilibili.com/vide ...