ES-IK分词器
一、安装
https://www.cnblogs.com/wudequn/p/11001382.html
https://github.com/medcl/elasticsearch-analysis-ik/(官方文档)
二、配置
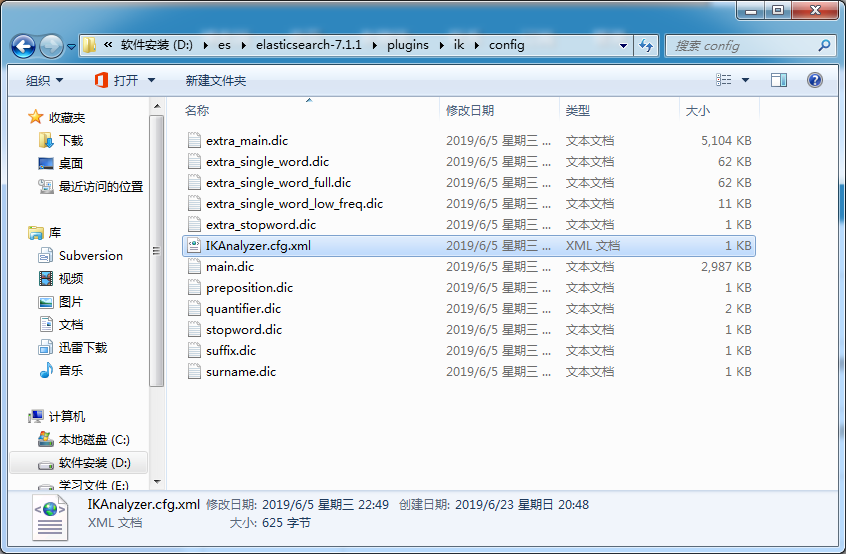
IKAnalyzer.cfg.xml 这个是配置文件,其他的都是自带的分词文件。
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
将分词文件填入***.dic <entry key ="exyt_dict">my.dic<entry>中,在重启es。
或者
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">words_location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">words_location</entry>
其中location是指一个 url,比如http://*******,该请求只需满足以下两点即可完成分词热更新。
1、该 http 请求需要返回两个头部(header),一个是Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
2、该 http 请求返回的内容格式是一行一个分词,换行符用\n即可。
满足上面两点要求可实现热更新分词,不需要重启 ES 实例。
三、测试
https://github.com/medcl/elasticsearch-analysis-ik/ (官网教程 要是跑不通就试试下面的)

mapping相当于指定表中字段 以及 字段类型。这时也可以指定分词。
https://blog.csdn.net/qinyuezhan/article/details/82463340 (mapping 详解)
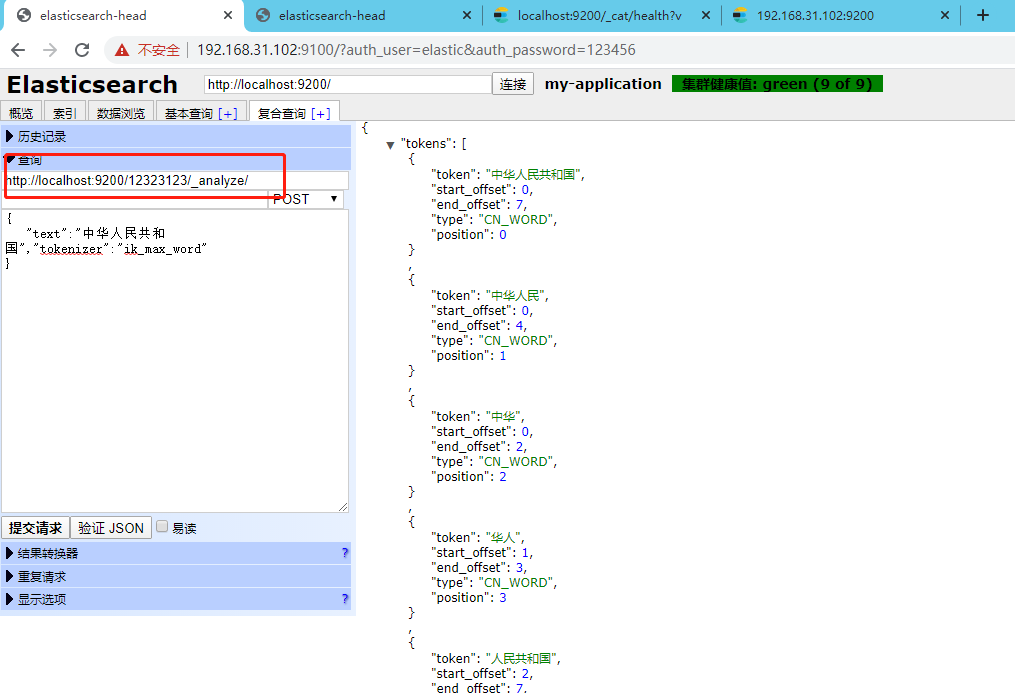
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
http://localhost:9200/这里是索引名称/_analyze/
ES-IK分词器的更多相关文章
- ES ik分词器使用技巧
match查询会将查询词分词,然后对分词的结果进行term查询. 然后默认是将每个分词term查询之后的结果求交集,所以只要分词的结果能够命中,某条数据就可以被查询出来,而分词是在新建索引时指定的,只 ...
- ES系列一、CentOS7安装ES 6.3.1、集成IK分词器
Elasticsearch 6.3.1 地址: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3. ...
- 安装ik分词器以及版本和ES版本的兼容性
一.查看自己ES的版本号与之对应的IK分词器版本 https://github.com/medcl/elasticsearch-analysis-ik/blob/master/README.md 二. ...
- es之IK分词器
1:默认的分析器-- standard 使用默认的分词器 curl -XGET 'http://hadoop01:9200/_analyze?pretty&analyzer=standard' ...
- Elasticsearch5.1.1+ik分词器+HEAD插件安装小记
一.安装elasticsearch 1.首先需要安装好java,并配置好环境变量,详细教程请看 http://tecadmin.net/install-java-8-on-centos-rhel-an ...
- elasticsearch 之IK分词器安装
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik 安装好ES之后就可以安装分词器插件了 记住选择ES对应的版本 对应的有版本选择下载 ...
- 如何开发自己的搜索帝国之安装ik分词器
Elasticsearch默认提供的分词器,会把每个汉字分开,而不是我们想要的根据关键词来分词,我是中国人 不能简单的分成一个个字,我们更希望 “中国人”,“中国”,“我”这样的分词,这样我们就需要 ...
- elasticsearch安装ik分词器
一.概要: 1.es默认的分词器对中文支持不好,会分割成一个个的汉字.ik分词器对中文的支持要好一些,主要由两种模式:ik_smart和ik_max_word 2.环境 操作系统:centos es版 ...
- ElasticSearch6.5.0 【安装IK分词器】
不得不夸奖一下ES的周边资源,比如这个IK分词器,紧跟ES的版本,卢本伟牛逼!另外ES更新太快了吧,几乎不到半个月一个小版本就发布了!!目前已经发了6.5.2,估计我还没怎么玩就到7.0了. 下载 分 ...
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
随机推荐
- phpstorm 2019.1 修改浏览器
如图,修改如下浏览器的位置,由于我安装了虚拟机,导致每次点击谷歌浏览器后,都是打开的虚拟机里面的谷歌浏览器,需要重新设置浏览器的位置 打开设置 打开浏览器设置界面 双击可以选择浏览器的路径,然后就可以 ...
- Python 之pyinstaller模块打包成exe文件
一.安装pyinstaller pip install pyinstaller 二.下载安装pyinstaler运行时所需要的windows扩展pywin32 https://github.com/m ...
- SpringMVC之请求部分
1.接收请求之限定请求类型 只接受Post请求 @RequestMapping(value="",method=RequestMethod.POST) 只接受get请求 @Requ ...
- spaceclaim脚本(线生成面体)
#新建一个列表,用来保存修剪曲线(PS:修建曲线的意思是开始点和结束点不在一起,圆就不属于修建曲线) #注意和Line,Circle类型等的区别 curves = List[ITrimmedCurve ...
- 第06组 Alpha冲刺(3/6)
队名:拾光组 组长博客链接 作业博客链接 团队项目情况 燃尽图(组内共享) 组长:宋奕 过去两天完成了哪些任务 主要完成了用户论坛模块的接口设计 完善后端的信息处理 GitHub签入记录 接下来的计划 ...
- MXNet/Gluon 中网络和参数的存取方式
https://blog.csdn.net/caroline_wendy/article/details/80494120 Gluon是MXNet的高层封装,网络设计简单易用,与Keras类似.随着深 ...
- 004 API约定
在具体的学习前,我还是决定学一下,REST风格中在ES中的约定. 1.多重索引 先准备数据: 如果不小心,json里的值写错了,修改过来,重新执行即可. PUT index1/_doc/1 { &qu ...
- Could not attach to pid : "xx"最近启动Xcode运行项目都会出现这个问题,再次启动或者多启动几次,就可以正常运行工程了。
最近启动Xcode运行项目都会出现这个问题,再次启动或者多启动几次,就可以正常运行工程了. 普及一下:PID(进程控制符)英文全称为Process Identifier,它也属于电工电子类技术术语. ...
- mysql 安装参考
https://blog.csdn.net/qq_38756992/article/details/84929787 https://www.cnblogs.com/joyny/p/10991194. ...
- bat批处理文件怎么将路径添加到path环境变量中
bat批处理文件怎么将路径添加到path环境变量中 摘自:https://zhidao.baidu.com/question/1887763143433391788.html 永久性的: @echo ...