[Scikit-learn] 1.4 Support Vector Regression
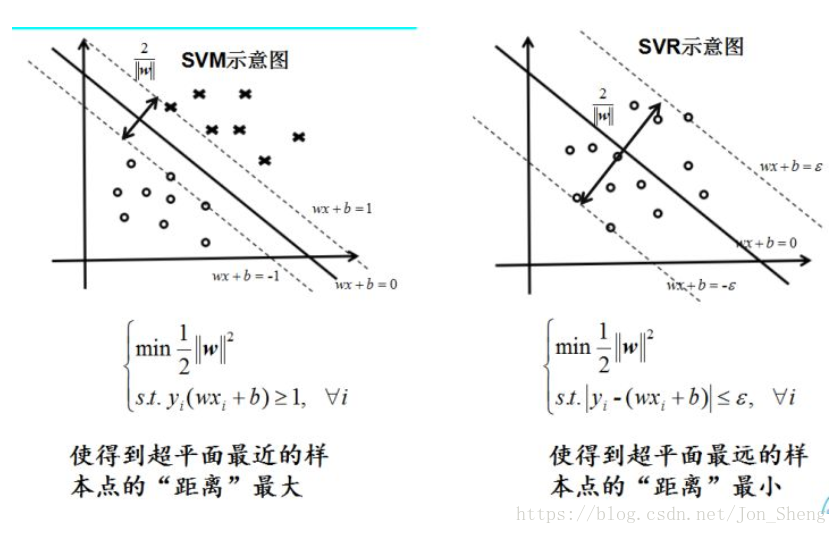
SVM算法
- 既可用于回归问题,比如SVR(Support Vector Regression,支持向量回归)
- 也可以用于分类问题,比如SVC(Support Vector Classification,支持向量分类)
这里简单介绍下SVR:https://scikit-learn.org/stable/modules/svm.html#svm-regression
SVM解决回归问题
一、原理示范
Ref: 支持向量机 svc svr svm
感觉不是很好的样子,没有 Bayesian Linear Regression的效果好;但其实也是取决于“核”的选取。
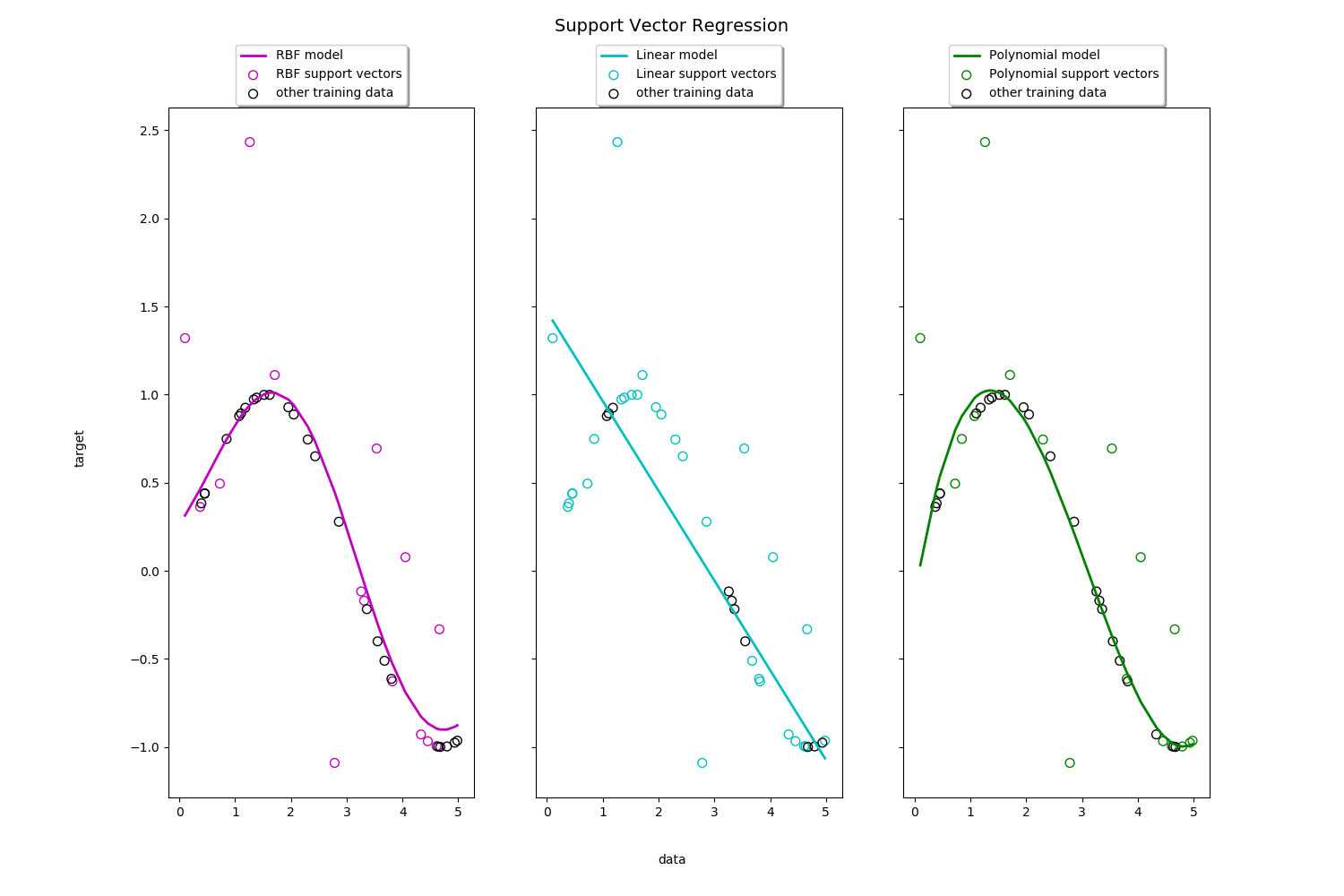
二、代码示范
print(__doc__) import numpy as np
from sklearn.svm import SVR
import matplotlib.pyplot as plt # #############################################################################
# Generate sample data
X = np.sort(5 * np.random.rand(40, 1), axis=0)
y = np.sin(X).ravel() # #############################################################################
# Add noise to targets
y[::5] += 3 * (0.5 - np.random.rand(8)) # #############################################################################
# Fit regression model
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1)
svr_lin = SVR(kernel='linear', C=100, gamma='auto')
svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1,
coef0=1) # #############################################################################
# Look at the results
lw = 2 svrs = [svr_rbf, svr_lin, svr_poly]
kernel_label = ['RBF', 'Linear', 'Polynomial']
model_color = ['m', 'c', 'g'] fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15, 10), sharey=True)
for ix, svr in enumerate(svrs):
axes[ix].plot(X, svr.fit(X, y).predict(X), color=model_color[ix], lw=lw,
label='{} model'.format(kernel_label[ix]))
axes[ix].scatter(X[svr.support_], y[svr.support_], facecolor="none",
edgecolor=model_color[ix], s=50,
label='{} support vectors'.format(kernel_label[ix]))
axes[ix].scatter(X[np.setdiff1d(np.arange(len(X)), svr.support_)],
y[np.setdiff1d(np.arange(len(X)), svr.support_)],
facecolor="none", edgecolor="k", s=50,
label='other training data')
axes[ix].legend(loc='upper center', bbox_to_anchor=(0.5, 1.1),
ncol=1, fancybox=True, shadow=True) fig.text(0.5, 0.04, 'data', ha='center', va='center')
fig.text(0.06, 0.5, 'target', ha='center', va='center', rotation='vertical')
fig.suptitle("Support Vector Regression", fontsize=14)
plt.show()
可见,RBF有了径向基中“贝叶斯概率”的特性,跟容易找到数据趋势的主体。
实践出真知
Ref: SVM: 实际中使用SVM的一些问题
一、核的选择
如果features的范围差别不大。
- 一种选择是不使用kernel(也称为linear kernel),直接使用x: 这种情况是当我们的n很大(即维度很高,features很多)但是训练样本却很少的情况下,我们一般不希望画出很复杂的边界线 (因为样本很少,画出很复杂的边界线就会过拟合),而是用线性的边界线。
- 一种选择是使用Gaussian kernel: 这种情况需要确定σ2(平衡bias还是variance)。这种情况是当x的维度不高,但是样本集很多的情况下。如上图中,n=2,但是m却很多,需要一个类似于圆的边界线。(即需要一个复杂的边界)
二、默塞尔定理
如果features的范围差别很大,在执行kernel之前要使用feature scaling。
我们最常用的是 高斯kernel 和 linear kernel (即不使用kernel),但是需要注意的是不是任何相似度函数都是有效的核函数,它们(包括我们常使用的高斯kernel)需要满足一个定理(默塞尔定理),这是因为SVM有很多数值优化技巧,为了有效地求解参数Θ,需要相似度函数满足默塞尔定理,这样才能确保SVM包能够使用优化的方法来求解参数Θ。
三、LR / SVM / DNN 比较
我们将logistic regression的cost function进行了修改得出了SVM,那么我们在什么情况下应该使用什么算法呢?
【量少】如果我们的features要比样本数要大的话(如n=10000 (维度),m=10-1000 (样本量)),我们使用logistic regression或者linear kernel,因为在样本较少的情况下,我们使用线性分类效果已经很好了,我们没有足够多的样本来支持我们进行复杂的分类。
【适量】如果n(维度)较小,m(样本量)大小适中的话,使用SVM with Gaussion kernel.如我们之前讲的有一个二维(n=2)的数据集,我们可以使用高斯核函数很好的将正负区分出来.
【量多】如果n(维度)较小,m(样本量)非常庞大的话,会创建一些features,然后再使用logistic regeression 或者linear kernel。因为当m非常大的话,使用高斯核函数会较慢。
logistic regeression 与linear kernel是非常相似的算法,如果其中一个适合运行的话,那么另一个也很有可能适合运行。
我们使用高斯kernel的范围很大,当m多达50000,n在1-1000(很常见的范围),都可以使用SVM with 高斯kernel,可以解决很多logistic regression不能解决的问题。
神经网络在任何情况下都适用,但是有一个缺点是它训练起来比较慢,相对于SVM来说
SVM求的不是局部最优解,而是全局最优解
相对于使用哪种算法来说,我们更重要的是
- 掌握更多的数据,
- 如何调试算法(bias/variance),
- 如何设计新的特征变量,
这些都比是使用SVM还是logistic regression重要。
但是SVM是一种被广泛使用的算法,并且在某个范围内,它的效率非常高,是一种有效地学习复杂的非线性问题的学习算法。
logistic regression,神经网络,SVM这三个学习算法使得我们可以解决很多前沿的机器学习问题。
End.
[Scikit-learn] 1.4 Support Vector Regression的更多相关文章
- support vector regression与 kernel ridge regression
前一篇,我们将SVM与logistic regression联系起来,这一次我们将SVM与ridge regression(之前的linear regression)联系起来. (一)kernel r ...
- 机器学习技法:06 Support Vector Regression
Roadmap Kernel Ridge Regression Support Vector Regression Primal Support Vector Regression Dual Summ ...
- [机器学习]回归--Support Vector Regression(SVR)
来计算其损失. 而支持向量回归则认为只要f(x)与y偏离程度不要太大,既可以认为预测正确,不用计算损失,具体的,就是设置阈值α,只计算|f(x)−y|>α的数据点的loss,如下图所示,阴影部分 ...
- 机器学习技法笔记:06 Support Vector Regression
Roadmap Kernel Ridge Regression Support Vector Regression Primal Support Vector Regression Dual Summ ...
- 翻译——2_Linear Regression and Support Vector Regression
续上篇 1_Project Overview, Data Wrangling and Exploratory Analysis 使用不同的机器学习方法进行预测 线性回归 在这本笔记本中,将训练一个线性 ...
- 【Support Vector Regression】林轩田机器学习技法
上节课讲了Kernel的技巧如何应用到Logistic Regression中.核心是L2 regularized的error形式的linear model是可以应用Kernel技巧的. 这一节,继续 ...
- [Scikit-learn] 1.4 Support Vector Machines - Linear Classification
Outline: 作为一种典型的应用升维的方法,内容比较多,自带体系,以李航的书为主,分篇学习. 函数间隔和几何间隔 最大间隔 凸最优化问题 凸二次规划问题 线性支持向量机和软间隔最大化 添加的约束很 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
随机推荐
- java中的String要点解析
String类使我们经常使用的一个类,经常用来表示字符串常量. 字符串一旦被创建赋值,就不能被改变,因为String 底层是数组实现的,且被定义成final类型.我们可以看String源码. /** ...
- ContextLoaderListener解析
推荐:spring源码 每一个整合spring框架的项目中,总是不可避免地要在web.xml中加入这样一段配置. <!-- Spring配置文件开始 --> <context-par ...
- HTML锚点控制,跳转页面后定位到相应位置
想在点击更多的页面 跳转后 用户能看到的是新闻 不用再用scollbar拖下来到新闻页面 这时候就需要在链接上 做下处理 <a href="/article/list/page/ ...
- 使用对象,面向对象创建div的方式
<script> // //对象div的创建 // var div = document.createElement("div"); // document.body. ...
- asp.net大文件分块上传断点续传demo
IE的自带下载功能中没有断点续传功能,要实现断点续传功能,需要用到HTTP协议中鲜为人知的几个响应头和请求头. 一. 两个必要响应头Accept-Ranges.ETag 客户端每次提交下载请求时,服务 ...
- 洛谷 P2010 回文日期 题解
P2010 回文日期 题目描述 在日常生活中,通过年.月.日这三个要素可以表示出一个唯一确定的日期. 牛牛习惯用88位数字表示一个日期,其中,前44位代表年份,接下来22位代表月 份,最后22位代表日 ...
- (3)Go运算符
运算符 Go 语言内置的运算符有: 算术运算符 关系运算符 逻辑运算符 位运算符 赋值运算符 算数运算符 运算符 描述 + 相加 - 相减 * 相乘 / 相除 % 求余 注意: ++(自增)和--(自 ...
- 加入购物车的功能wepy
1.先有一个加入购物车的按钮 <view wx:if="{{(detaildata.boughtNum < detaildata.buy_limit) && de ...
- JavaScript substr() 方法
定义和用法 substr() 方法可在字符串中抽取从 start 下标开始的指定数目的字符. 语法 stringObject.substr(start,length) 参数 描述 start 必需.要 ...
- React.createElement 与 JSX
DOM 向JSX的演进 网页由 DOM 元素构成.React DOM 并不是浏览器的 DOM,而React DOM 只是用来告诉浏览器如何创建 DOM 的方法.通常情况下,我们并不需要 React 就 ...