自然语言处理2.1——NLTK文本语料库
1.获取文本语料库
NLTK库中包含了大量的语料库,下面一一介绍几个:
(1)古腾堡语料库:NLTK包含古腾堡项目电子文本档案的一小部分文本。该项目目前大约有36000本免费的电子图书。
>>>import nltk
>>>nltk.corpus.gutenberg.fileids()
['austen-emma.txt','austen-persuasion.txt' 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt','bryant-stories.txt','burgess-busterbrown.tx'carroll-alice.txt', 'chesterton-ball.txt','chesterton-brown.txt','chesterton-thursday.tx'edgeworth-parents.txt'
'melville-moby_dick.txt'milton-paradise.txt', 'shakespeare-caesar.txt, 'shakespeare-hamlet.txt, 'shakespeare-macbeth.txt 'whitman-leaves.txt']
使用:from nltk.corpus import gutenberg
写一段简短的程序,通过遍历前面所列出的与gutenberg文体标识符相应的fileid,然后统计每个文本:
import nltk
from nltk.corpus import gutenberg for fileid in gutenberg.fileids():
num_chars=len(gutenberg.raw(fileid)) ###统计字符数
num_words=len(gutenberg.words(fileid)) ##统计单词书
num_sent=len(gutenberg.sents(fileid)) ###统计句子数
num_vocab=len(set([w.lower() for w in gutenberg.words(fileid)])) ###唯一化单词
print(int(num_chars/num_words),int(num_words/num_sent),int(num_words/num_vocab),fileid)
结果为:4 24 26 austen-emma.txt
4 26 16 austen-persuasion.txt
4 28 22 austen-sense.txt
4 33 79 bible-kjv.txt
4 19 5 blake-poems.txt
4 19 14 bryant-stories.txt
4 17 12 burgess-busterbrown.txt
4 20 12 carroll-alice.txt
4 20 11 chesterton-ball.txt
4 22 11 chesterton-brown.txt
4 18 10 chesterton-thursday.txt
4 20 24 edgeworth-parents.txt
4 25 15 melville-moby_dick.txt
4 52 10 milton-paradise.txt
4 11 8 shakespeare-caesar.txt
4 12 7 shakespeare-hamlet.txt
4 12 6 shakespeare-macbeth.txt
4 36 12 whitman-leaves.txt
这个结果显示了每个文本的3个统计量:平局词长,平均句子长度和文本中每个词出现的平均次数。
(2)网络和聊天文本:
这部分代表的是非正式的语言,包括Firefox交流论坛、在纽约无意听到的对话、《加勒比海盗》电影剧本。个人广告以及葡萄酒的评论。
导入:from nltk.corpus import webtext
import nltk
from nltk.corpus import webtext for fileid in webtext.fileids():
print( fileid,webtext.raw(fileid)[:65],'...')
结果为:firefox.txt Cookie Manager: "Don't allow sites that set removed cookies to se ...
grail.txt SCENE 1: [wind] [clop clop clop]
KING ARTHUR: Whoa there! [clop ...
overheard.txt White guy: So, do you have any plans for this evening?
Asian girl ...
pirates.txt PIRATES OF THE CARRIBEAN: DEAD MAN'S CHEST, by Ted Elliott & Terr ...
singles.txt 25 SEXY MALE, seeks attrac older single lady, for discreet encoun ...
wine.txt Lovely delicate, fragrant Rhone wine. Polished leather and strawb ...
还有一个即时聊天会话语料库,最初由海军研究生院为研究自动检测互联网入侵者而收集的:
>>>from nltk.corpus import nps_chat
(3)布朗语意库:
布朗语意库是第一个百万词集的英语电子语料库,有布朗大学于1961年创建,包含500多个不同来源的文本,按照文本类型,如新闻、社评等分类。
>>>import nltk
>>>from nltk.corpus import brown >>>print(brown.categories()) ['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
布朗语料库是一个研究文体之间系统性差异的资源。让我们来比较不同文体的情态动词的用法。步骤如下:
第一步:对特定文体进行计数。
import nltk
from nltk.corpus import brown news_text=brown.words(categories='news')
fdist=nltk.FreqDist([w.lower() for w in news_text])
modals=['can','could','may','might','must','will']
for m in modals:
print(m+':',fdist[m])
结果如下:can: 94,could: 87,may: 93,might: 38,must: 53,will: 389
第二步:统计每一个感兴趣的文体。我们使用NLTK提供的条件概率分布函数。
cfd=nltk.ConditionalFreqDist((genre,word) for genre in brown.categories() for word in brown.words(categories=genre)) genres=['news','religion','hobbies','science_fiction','romance','humor']
modals=['can','could','may','might','must','will']
cfd.tabulate(conditions=genres,samples=modals)
输出结果为:
can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
(4)路透社语料库
路透社语料库包括10788个新闻文档,共计130万字。这些文档分成了90个主题,按照‘训练’和‘测试’分为两组。因此,编号为‘test/14826’的文档属于测试组。这样分割是为了方便运用训练和测试算法的自动检验文档的主题。
(5)就职演说语料库
语料库实际上是55个文本的集合,每个文本都是一个总统的演讲。这个集合的显著特征就是时间维度。
import nltk
from nltk.corpus import inaugural
print(inaugural.fileids())
['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', '1801-Jefferson.txt', '1805-Jefferson.txt', '1809-Madison.txt', '1813-Madison.txt', '1817-Monroe.txt', '1821-Monroe.txt', '1825-Adams.txt', '1829-Jackson.txt', '1833-Jackson.txt', '1837-VanBuren.txt', '1841-Harrison.txt', '1845-Polk.txt', '1849-Taylor.txt', '1853-Pierce.txt', '1857-Buchanan.txt', '1861-Lincoln.txt', '1865-Lincoln.txt', '1869-Grant.txt', '1873-Grant.txt', '1877-Hayes.txt', '1881-Garfield.txt', '1885-Cleveland.txt', '1889-Harrison.txt', '1893-Cleveland.txt', '1897-McKinley.txt', '1901-McKinley.txt', '1905-Roosevelt.txt', '1909-Taft.txt', '1913-Wilson.txt', '1917-Wilson.txt', '1921-Harding.txt', '1925-Coolidge.txt', '1929-Hoover.txt', '1933-Roosevelt.txt', '1937-Roosevelt.txt', '1941-Roosevelt.txt', '1945-Roosevelt.txt', '1949-Truman.txt', '1953-Eisenhower.txt', '1957-Eisenhower.txt', '1961-Kennedy.txt', '1965-Johnson.txt', '1969-Nixon.txt', '1973-Nixon.txt', '1977-Carter.txt', '1981-Reagan.txt', '1985-Reagan.txt', '1989-Bush.txt', '1993-Clinton.txt', '1997-Clinton.txt', '2001-Bush.txt', '2005-Bush.txt', '2009-Obama.txt']
可以发现,每个文本的年代都出现在他的文件名中。要从文件名中提取出年代,只需要使用fileid[:4]即可。
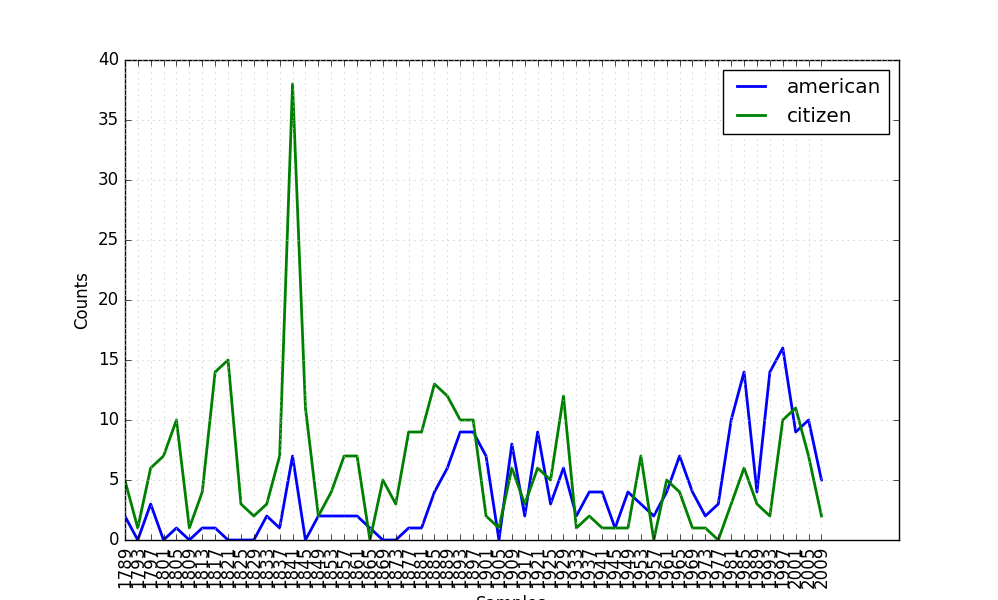
例子:我们可以看看‘American’和‘citizen’随着时间推移的使用情况。
import nltk
from nltk.corpus import inaugural
cfd=nltk.ConditionalFreqDist((target,fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['american','citizen']
if w.lower().startswith(target) ) cfd.plot()
结果如下:
(6)标注文本语料库和其他语言语料库
自然语言处理2.1——NLTK文本语料库的更多相关文章
- 自然语言处理(1)之NLTK与PYTHON
自然语言处理(1)之NLTK与PYTHON 题记: 由于现在的项目是搜索引擎,所以不由的对自然语言处理产生了好奇,再加上一直以来都想学Python,只是没有机会与时间.碰巧这几天在亚马逊上找书时发现了 ...
- 自然语言处理——NLTK中文语料库语料库
Python NLTK库中包含着大量的语料库,但是大部分都是英文,不过有一个Sinica(中央研究院)提供的繁体中文语料库,值得我们注意. 在使用这个语料库之前,我们首先要检查一下是否已经安装了这个语 ...
- python+NLTK 自然语言学习处理二:文本
在前面讲nltk安装的时候,我们下载了很多的文本.总共有9个文本.那么如何找到这些文本呢: text1: Moby Dick by Herman Melville 1851 text2: Sense ...
- 自然语言20_The corpora with NLTK
QQ:231469242 欢迎喜欢nltk朋友交流 https://www.pythonprogramming.net/nltk-corpus-corpora-tutorial/?completed= ...
- 自然语言23_Text Classification with NLTK
QQ:231469242 欢迎喜欢nltk朋友交流 https://www.pythonprogramming.net/text-classification-nltk-tutorial/?compl ...
- 机器学习之路: python nltk 文本特征提取
git: https://github.com/linyi0604/MachineLearning 分别使用词袋法和nltk自然预言处理包提供的文本特征提取 from sklearn.feature_ ...
- 自然语言19.1_Lemmatizing with NLTK(单词变体还原)
QQ:231469242 欢迎喜欢nltk朋友交流 https://www.pythonprogramming.net/lemmatizing-nltk-tutorial/?completed=/na ...
- 自然语言14_Stemming words with NLTK
https://www.pythonprogramming.net/stemming-nltk-tutorial/?completed=/stop-words-nltk-tutorial/ # -*- ...
- 自然语言13_Stop words with NLTK
https://www.pythonprogramming.net/stop-words-nltk-tutorial/?completed=/tokenizing-words-sentences-nl ...
随机推荐
- WEB ui快速构建
http://www.runoob.com/bootstrap/bootstrap-ui-editor.html 1http://pingendo.com/ 2http://www.layoutit. ...
- php大力力 [026节] php开发状态要随时做好整理工作
php大力力 [026节] php开发状态要随时做好整理工作: 1.整理了开发目录,以及文件命名: 2.做了各个页面的快捷方式: 3.把浏览器safari的很多没来得及消化的页面链接,写入了我的在线 ...
- 多数求和(java)
实验题目:从命令行接受多个数字,求和之后输出结果. 设计思想:命令行输入的字符会赋值给args数组,所以在命令行输入数字后,直接取出args的数组长度,作为循环语句的终点判断,然后利用循环将字符型改为 ...
- 调度 Quartz 时间格式配置
1. CronTrigger时间格式配置说明 CronTrigger配置格式: 格式: [秒] [分] [小时] [日] [月] [周] [年]
- 怎样修改Response中的内容
重写Stream public class CatchTextStream : Stream { private Stream output; public CatchTextStream(Strea ...
- React Native 组件之TextInput
React Native 组件之TextInput类似于iOS中的UITextView或者UITextField,是作为一个文字输入的组件,下面的TextInput的用法和相关属性. /** * Sa ...
- HDU1166-敌兵布阵(线段树)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1166 #include<cstdio> #include<string> #i ...
- 【转】Fiddler 教程
原文转自:http://www.cnblogs.com/tankxiao/archive/2012/02/06/2337728.html Fiddler是最强大最好用的Web调试工具之一,它能记录所有 ...
- AssemblyInfo.cs的作用
总结:用来设置项目生成的dll的常规信息.(如版本.版权等等)它就相当于一个资源文件,存放资源信息. http://www.cnblogs.com/xuyuantao/articles/927285. ...
- 游戏buff设计参见
其实这类帖子并没有多少的设计理论,对于策划的提升和帮助也并不大,原因其实在于其适用性太窄,当我要设计XX象棋的时候,它就滚一边去了. 废话不多说切入正题: 游戏中的BUFF/DEBUFF我们见过很多, ...