隐私计算FATE-多分类神经网络算法测试

一、说明
本文分享基于 Fate 使用 横向联邦 神经网络算法 对 多分类 的数据进行 模型训练,并使用该模型对数据进行 多分类预测。
- 二分类算法:是指待预测的 label 标签的取值只有两种;直白来讲就是每个实例的可能类别只有两种(0 或者 1),例如性别只有 男 或者 女;此时的分类算法其实是在构建一个分类线将数据划分为两个类别。
- 多分类算法:是指待预测的 label 标签的取值可能有多种情况,例如个人爱好可能有 篮球、足球、电影 等等多种类型。常见算法:Softmax、SVM、KNN、决策树。
关于 Fate 的核心概念、单机部署、训练以及预测请参考以下相关文章:
二、准备训练数据
上传到 Fate 里的数据有两个字段名必需是规定的,分别是主键为 id 字段和分类字段为 y 字段,y 字段就是所谓的待预测的 label 标签;其他的特征字段(属性)可任意填写,例如下面例子中的 x0 - x9
例如有一条用户数据为:
收入: 10000,负债: 5000,是否有还款能力: 1 ;数据中的收入和负债就是特征字段,而是否有还款能力就是分类字段。
本文只描述关键部分,关于详细的模型训练步骤,请查看文章《隐私计算FATE-模型训练》
2.1. guest端
10条数据,包含1个分类字段 y 和 10 个标签字段 x0 - x9
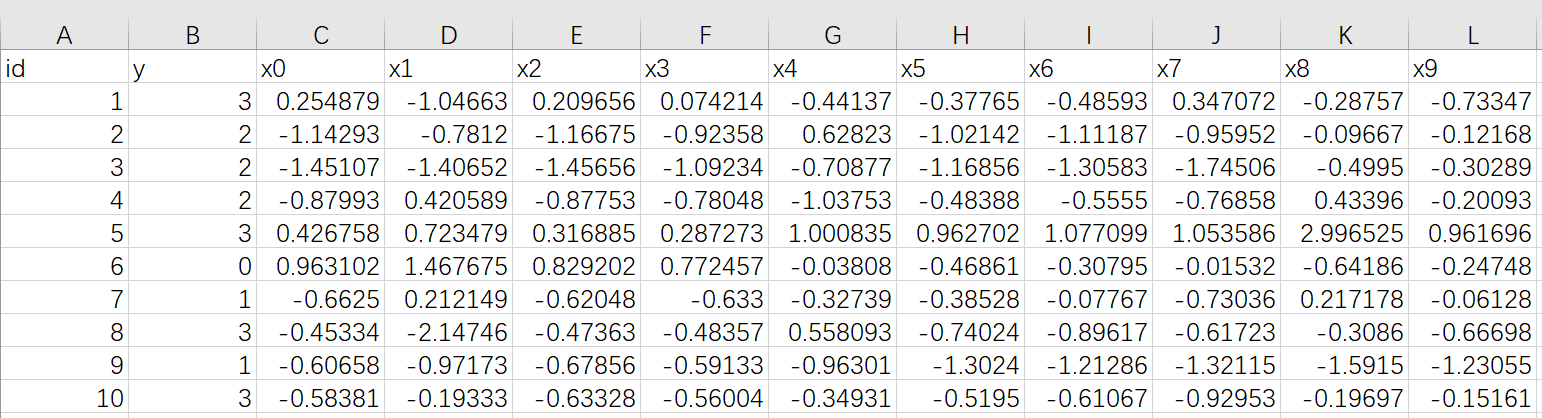
y 值有 0、1、2、3 四个分类
上传到 Fate 中,表名为 muti_breast_homo_guest 命名空间为 experiment
2.2. host端
10条数据,字段与 guest 端一样,但是内容不一样
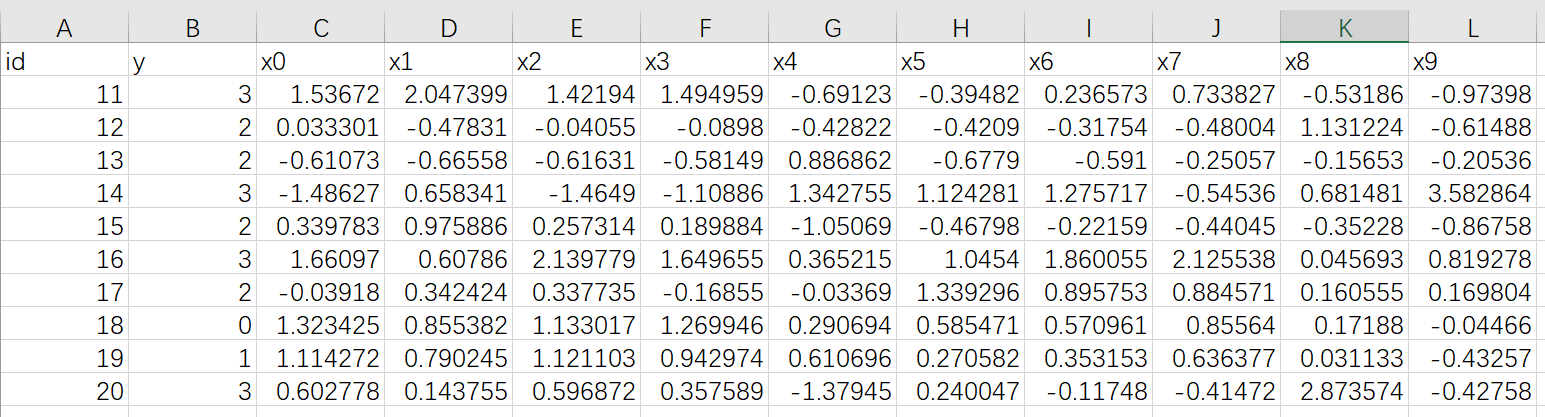
上传到 Fate 中,表名为 muti_breast_homo_host 命名空间为 experiment
三、执行训练任务
3.1. 准备dsl文件
创建文件 homo_nn_dsl.json 内容如下 :
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_nn_0": {
"module": "HomoNN",
"input": {
"data": {
"train_data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
}
}
}
3.2. 准备conf文件
创建文件 homo_nn_multi_label_conf.json 内容如下 :
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true
},
"homo_nn_0": {
"encode_label": true,
"max_iter": 15,
"batch_size": -1,
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"optimizer": {
"learning_rate": 0.05,
"decay": 0.0,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07,
"amsgrad": false,
"optimizer": "Adam"
},
"loss": "categorical_crossentropy",
"metrics": [
"accuracy"
],
"nn_define": {
"class_name": "Sequential",
"config": {
"name": "sequential",
"layers": [
{
"class_name": "Dense",
"config": {
"name": "dense",
"trainable": true,
"batch_input_shape": [
null,
18
],
"dtype": "float32",
"units": 5,
"activation": "relu",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
},
{
"class_name": "Dense",
"config": {
"name": "dense_1",
"trainable": true,
"dtype": "float32",
"units": 4,
"activation": "sigmoid",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
}
]
},
"keras_version": "2.2.4-tf",
"backend": "tensorflow"
},
"config_type": "keras"
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "muti_breast_homo_host",
"namespace": "experiment"
}
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "muti_breast_homo_guest",
"namespace": "experiment"
}
}
}
}
}
}
}
注意
reader_0组件的表名和命名空间需与上传数据时配置的一致。
3.3. 提交任务
执行以下命令:
flow job submit -d homo_nn_dsl.json -c homo_nn_multi_label_conf.json
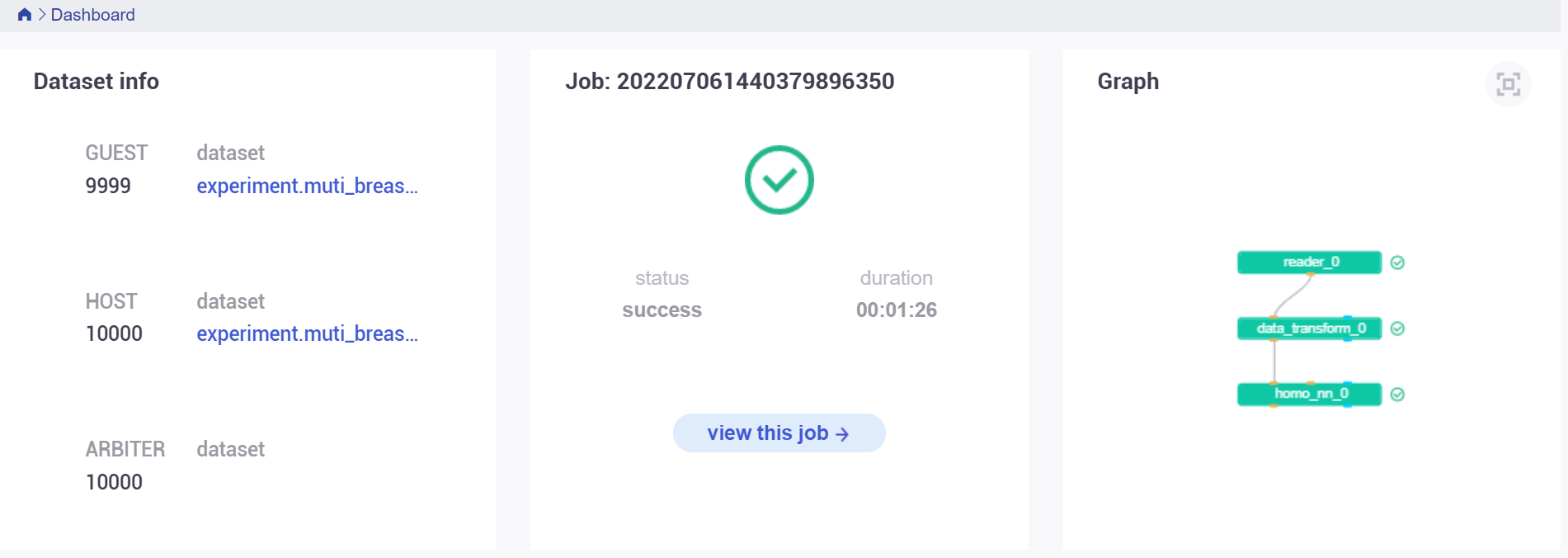
执行成功后,查看 dashboard 显示:
四、准备预测数据
与前面训练的数据字段一样,但是内容不一样,y 值全为 0
4.1. guest端
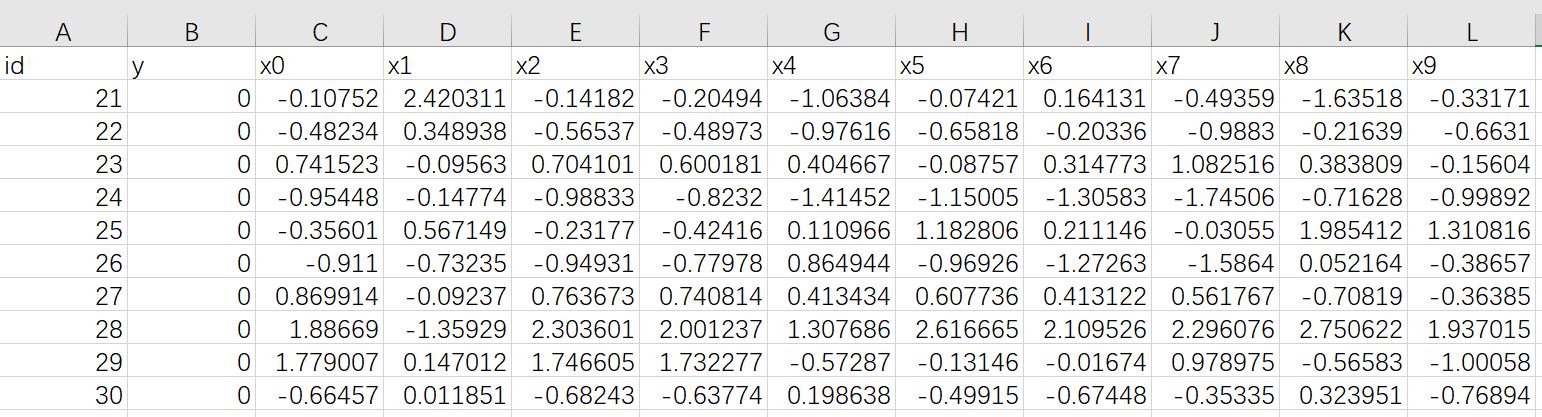
上传到 Fate 中,表名为 predict_muti_breast_homo_guest 命名空间为 experiment
4.2. host端
上传到 Fate 中,表名为 predict_muti_breast_homo_host 命名空间为 experiment
五、准备预测配置
本文只描述关键部分,关于详细的预测步骤,请查看文章《隐私计算FATE-离线预测》
创建文件 homo_nn_multi_label_predict.json 内容如下 :
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"job_parameters": {
"common": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202207061504081543620",
"job_type": "predict"
}
},
"component_parameters": {
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "predict_muti_breast_homo_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "predict_muti_breast_homo_host",
"namespace": "experiment"
}
}
}
}
}
}
}
注意以下两点:
model_id和model_version需修改为模型部署后的版本号。
reader_0组件的表名和命名空间需与上传数据时配置的一致。
五、执行预测任务
执行以下命令:
flow job submit -c homo_nn_multi_label_predict.json
执行成功后,查看 homo_nn_0 组件的数据输出:

可以看到算法输出的预测结果。
扫码关注有惊喜!

隐私计算FATE-多分类神经网络算法测试的更多相关文章
- 《BI那点儿事》Microsoft 神经网络算法
Microsoft神经网络是迄今为止最强大.最复杂的算法.要想知道它有多复杂,请看SQL Server联机丛书对该算法的说明:“这个算法通过建立多层感知神经元网络,建立分类和回归挖掘模型.与Micro ...
- 数据挖掘系列(9)——BP神经网络算法与实践
神经网络曾经很火,有过一段低迷期,现在因为深度学习的原因继续火起来了.神经网络有很多种:前向传输网络.反向传输网络.递归神经网络.卷积神经网络等.本文介绍基本的反向传输神经网络(Backpropaga ...
- 利用神经网络算法的C#手写数字识别
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 下载Demo - 2.77 MB (原始地址):handwritten_character_recognition.zip 下载源码 - 70. ...
- 使用Python scikit-learn 库实现神经网络算法
1:神经网络算法简介 2:Backpropagation算法详细介绍 3:非线性转化方程举例 4:自己实现神经网络算法NeuralNetwork 5:基于NeuralNetwork的XOR实例 6:基 ...
- 吴裕雄 python 人工智能——基于神经网络算法在智能医疗诊断中的应用探索代码简要展示
#K-NN分类 import os import sys import time import operator import cx_Oracle import numpy as np import ...
- 经典卷积神经网络算法(5):ResNet
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 利用神经网络算法的C#手写数字识别(一)
利用神经网络算法的C#手写数字识别 转发来自云加社区,用于学习机器学习与神经网络 欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 下载Demo - 2.77 MB (原始地址):handwri ...
- 隐私计算FATE-模型训练
一.说明 本文分享基于 Fate 自带的测试样例,进行 纵向逻辑回归 算法的模型训练,并且通过 FATE Board 可视化查看结果. 本文的内容为基于 <隐私计算FATE-概念与单机部署指南& ...
- 如何用70行Java代码实现深度神经网络算法(转)
对于现在流行的深度学习,保持学习精神是必要的——程序员尤其是架构师永远都要对核心技术和关键算法保持关注和敏感,必要时要动手写一写掌握下来,先不用关心什么时候用到——用不用是政治问题,会不会写是技术问题 ...
随机推荐
- stm32F103RCT6的DMA使用经历
DMA可以直接传输数据,减少了CPU的负担,是个很好的功能,但是用的时候难免会一头雾水.这次做个小小的串口收发程序就碰到了许多问题. 之前没有注意,选择了DMA的circular模式,然后奇怪的事 ...
- 详解Fiddler Classic过滤、重放、转发HTTP请求
更多干货文章,更多最新文章,欢迎到作者主博客 菜鸟厚非 一.简介 今天介绍一下 Fiddler Classic 对 HTPP 的过滤.重放.转发操作,这在开发中,尤其在微服务中调试中是经常用到的功能, ...
- 详解Kubernetes存储体系
Volume.PV.PVC.StorageClass由来 先思考一个问题,为什么会引入Volume这样一个概念? " 答案很简单,为了实现数据持久化,数据的生命周期不随着容器的消亡而消亡. ...
- Water 2.6.3 发布,一站式服务治理平台
Water(水孕育万物...) Water 为项目开发.服务治理,提供一站式解决方案(可以理解为微服务架构支持套件).基于 Solon 框架开发,并支持完整的 Solon Cloud 规范:已在生产环 ...
- IIS方式部署项目发布上线
VS2019如何把项目部署和发布 这里演示:通过IIS文件publish的方式部署到Windows本地服务器上 第一步(安装IIS) 1.在自己电脑上搜索Windows功能里的[启用或关闭Window ...
- 【面试普通人VS高手系列】说一说Mybatis里面的缓存机制
一个工作了 5年的程序员,在私信里面不断向我诉苦. 他说,他用了Mybatis这么久,怎么滴也算是精通Mybatis了吧. 结果竟然在Mybatis这个面试题上翻车了! 真的好烦! 好吧,我们今天来看 ...
- Dart 2.17 正式发布
文/ Michael Thomsen, Google Dart 团队产品经理,2022 年 5 月 12 日发表于 Dart 官方博客 随着 Flutter 3 在本次 I/O 大会的发布,我们也同时 ...
- zabbix-agent python脚本侦听服务器异常登录,并告警
py脚本 import re,subprocess,time,datetime #gpasswd -a zabbix adm def ftime(a): a = a.replace('Jan','01 ...
- idea maven 依赖还原不上的问题 method <init>()V not found
问题 还原项目依赖的时候报错: java.lang.RuntimeException: org.codehaus.plexus.component.repository.exception.Compo ...
- Redis设计与实现3.2:Sentinel
Sentinel哨兵 这是<Redis设计与实现>系列的文章,系列导航:Redis设计与实现笔记 哨兵:监视.通知.自动故障恢复 启动与初始化 Sentinel 的本质只是一个运行在特殊模 ...