加班?不存在的啦~Python处理Excel,学会这十四个方法,工作量减少大半
现在Python横行的年代,财务、人事、行政等等岗位多少得学点Python,省事又不费脑!
所有操作都用Python自动实现,
加班?不存在的!

excel和python其实都是工具,不要也不用拿去做对比,研究哪个好用,excel作为最为全球广泛的数据处理工具,垄断多年,肯定在数据处理方面有自己的优点,Python只是令 一些庞大的,费时间的操作加速处理,方便工作嘛。
当然也有很多excel的操作比用Python自动处理更加简单方便。
比如:对各列求和并在最下一行显示出来,excel就是对一列总一个sum()函数,然后往左一拉就解决,而python则要定义一个函数,python要判断格式,若非数值型数据会直接。我就不一一举例了!
好了,我们开始正题。
在网上找的销售数据,差不多长这样。
销售数据
1、数据透视表
需求
想知道每个地区的业务员分别赚取的利润总和与利润平均数
pd.pivot_table(sale,index="地区名称",columns="业务员名称",values="利润",aggfunc=[np.sum,np.mean])
兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。
那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及视频源的源代码!
还会有大佬解答!
都在这个裙里了
点我快速进入
欢迎加入,一起讨论 一起学习!
2、去除重复值
需求
去除业务员编码的重复值
sale.drop_duplicates("业务员编码",inplace=True)
3、分类汇总
需求
北京区域各业务员的利润总额
sale.groupby(["地区名称","业务员名称"])["利润"].sum()
4、关联公式:Vlookup
vlookup是excel几乎最常用的公式,一般用于两个表的关联查询等。
所以我先把这张表分为两个表。
df1=sale[['订单明细号','单据日期','地区名称', '业务员名称','客户分类', '存货编码', '客户名称', '业务员编码', '存货名称', '订单号',
'客户编码', '部门名称', '部门编码']]
df2=sale[['订单明细号','存货分类', '税费', '不含税金额', '订单金额', '利润', '单价','数量']]
需求
想知道df1的每一个订单对应的利润是多少
利润一列存在于df2的表格中,所以想知道df1的每一个订单对应的利润是多少。
用excel的话首先确认订单明细号是唯一值,然后在df1新增一列写:=vlookup(a2,df2!a:h,6,0) ,然后往下拉就ok了。
那用python是如何实现的呢?
#查看订单明细号是否重复,结果是没。
df1["订单明细号"].duplicated().value_counts()
df2["订单明细号"].duplicated().value_counts()
df_c=pd.merge(df1,df2,on="订单明细号",how="left")
5、条件计算
需求
存货名称含“三星字眼”并且税费高于1000的订单有几个?
这些订单的利润总和和平均利润是多少?(或者最小值,最大值,四分位数,标注差)
sale.loc[sale["存货名称"].str.contains("三星")&(sale["税费"]>=1000)][["订单明细号","利润"]].describe()
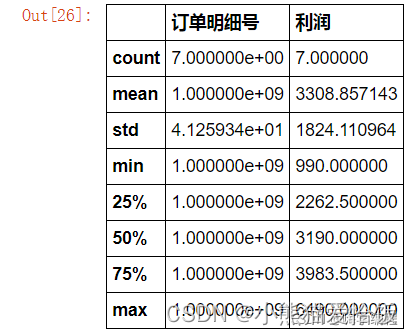
6、分组
需求
根据利润数据分布把地区分组为:“较差”,“中等”,“较好”,“非常好”
首先,当然是查看利润的数据分布呀,这里我们采用四分位数去判断。
sale.groupby("地区名称")["利润"].sum().describe()
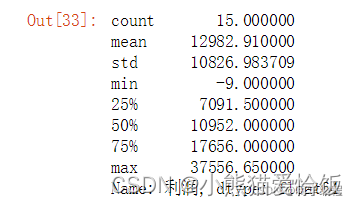
根据四分位数把地区总利润为[-9,7091]区间的分组为“较差”,(7091,10952]区间的分组为"中等"
(10952,17656]分组为较好,(17656,37556]分组为非常好。
#先建立一个Dataframe
sale_area=pd.DataFrame(sale.groupby("地区名称")["利润"].sum()).reset_index()
#设置bins,和分组名称
bins=[-10,7091,10952,17656,37556]
groups=["较差","中等","较好","非常好"]
#使用cut分组
#sale_area["分组"]=pd.cut(sale_area["利润"],bins,labels=groups)
7、对比两列差异
因为这表每列数据维度都不一样,比较起来没啥意义,所以我先做了个订单明细号的差异再进行比较。
需求:比较订单明细号与订单明细号2的差异并显示出来。
sale["订单明细号2"]=sale["订单明细号"]
#在订单明细号2里前10个都+1.
sale["订单明细号2"][1:10]=sale["订单明细号2"][1:10]+1
#差异输出
result=sale.loc[sale["订单明细号"].isin(sale["订单明细号2"])==False]
8、异常值替换
首先用describe()函数简单查看一下数据有无异常值。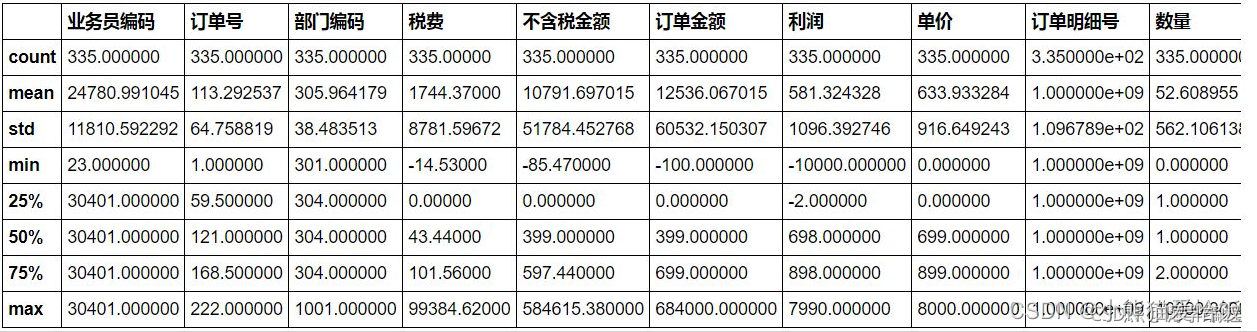
需求
用0代替异常值。
sale["订单金额"]=sale["订单金额"].replace(min(sale["订单金额"]),0)
9、缺失值处理
先查看销售数据哪几列有缺失值
#列的行数小于index的行数的说明有缺失值,这里客户名称329<335,说明有缺失值
sale.info()

需求
用0填充缺失值或则删除有客户编码缺失值的行
实际上缺失值处理的办法是很复杂的,这里只介绍简单的处理方法,若是数值变量,最常用平均数或中位数或众数处理,比较复杂的可以用随机森林模型根据其他维度去预测结果填充。
若是分类变量,根据业务逻辑去填充准确性比较高。
比如这里的需求填充客户名称缺失值:就可以根据存货分类出现频率最大的存货所对应的客户名称去填充。
这里我们用简单的处理办法:用0填充缺失值或则删除有客户编码缺失值的行。
#用0填充缺失值
sale["客户名称"]=sale["客户名称"].fillna(0)
#删除有客户编码缺失值的行
sale.dropna(subset=["客户编码"])
10、数据分列

需求
将日期与时间分列
sale=pd.merge(sale,pd.DataFrame(sale["单据日期"].str.split(" ",expand=True)),how="inner",left_index=True,right_index=True)
11、 模糊筛选数据
需求
筛选存货名称含有"三星"或则含有"索尼"的信息
sale.loc[sale["存货名称"].str.contains("三星|索尼")]
12、删除数据间的空格
需求
删除存货名称两边的空格
sale["存货名称"].map(lambda s :s.strip(""))
13、根据业务逻辑定义标签
需求
销售利润率(即利润/订单金额)大于30%的商品信息并标记它为优质商品,小于5%为一般商品。
sale.loc[(sale["利润"]/sale["订单金额"])>0.3,"label"]="优质商品"
sale.loc[(sale["利润"]/sale["订单金额"])<0.05,"label"]="一般商品"
14、多条件筛选
需求
想知道业务员张爱,在北京区域卖的商品订单金额大于6000的信息。
sale.loc[(sale["地区名称"]=="北京")&(sale["业务员名称"]=="张爱")&(sale["订单金额"]>5000)]
这里只是列举了一些比较常用的,但是excel常用的操作还有很多,如果还想实现哪些操作,大家可以在评论区一起交流。大家如果对这这些操作有更好的写法,也可以在评论区一起交流!感谢!
加班?不存在的啦~Python处理Excel,学会这十四个方法,工作量减少大半的更多相关文章
- Python之路【第十四篇】:AngularJS --暂无内容-待更新
Python之路[第十四篇]:AngularJS --暂无内容-待更新
- Python 3标准库 第十四章 应用构建模块
Python 3标准库 The Python3 Standard Library by Example -----------------------------------------第十四章 ...
- python学习笔记:(十四)面向对象
1.类(class): 用来描述具有相同的属性和方法的对象的集合.它定义了该集合中每个对象所共有的属性和方法 2.类变量: 类变量在整个实例化的对象中是公用的.类变量定义在类中且在函数体之外.类变量通 ...
- Python之路,第十四篇:Python入门与基础14
python3 模块2 标准模块 随机模块random 假设导入 import random as R 函数: R.random() 返回一个[0 ,1) 之间的随机数 R.getr ...
- Python之路【第二十四篇】Python算法排序一
什么是算法 1.什么是算法 算法(algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为输出.简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果. ...
- Python之路【第二十四篇】:Python学习路径及练手项目合集
Python学习路径及练手项目合集 Wayne Shi· 2 个月前 参照:https://zhuanlan.zhihu.com/p/23561159 更多文章欢迎关注专栏:学习编程. 本系列Py ...
- python运维开发(二十四)----crm权限管理系统
内容目录: 数据库设计 easyUI的使用 数据库设计 权限表Perssion 角色表Role 权限和角色关系表RoleToPermission 用户表UserInfo 用户和角色关系表UserInf ...
- Python学习笔记【第十四篇】:Python网络编程二黏包问题、socketserver、验证合法性
TCP/IP网络通讯粘包问题 案例:模拟执行shell命令,服务器返回相应的类容.发送指令的客户端容错率暂无考虑,按照正确的指令发送即可. 服务端代码 # -*- coding: utf- -*- # ...
- Python学习之旅(十四)
Python基础知识(13):函数(Ⅳ) Python内置函数 1.abs:取绝对值 abs(-1) 1 2.all:把序列中的每一个元素拿出来做布尔运算,都为真则返回True,如果序列中有None. ...
随机推荐
- 推荐一个我写的Python库——PyNAS
介绍 PyNAS是一个以Python的Updog的库为基础,制作而来的库 安装 pip安装(推荐) pip install PyNAS 源码安装(推荐) Github: git clone https ...
- 2021.08.16 P1300 城市街道交通费系统(dfs)
2021.08.16 P1300 城市街道交通费系统(dfs) P1300 城市街道交通费系统 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题意: 城市街道交费系统最近创立了.一 ...
- python学习-Day22
目录 今日内容详细 hashlib加密模块 什么是加密 加密算法 加密的使用 基本使用 指定算法(md5) 将明文数据传递给算法对象 获取加密之后的密文数据 加密补充 加盐处理 动态加盐 加密应用场景 ...
- XCTF练习题---WEB---simple_js
XCTF练习题---WEB---simple_js flag:Cyberpeace{786OsErtk12} 解题步骤: 1.观察题目,打开场景 2.打开该场景后发现是一个登录界面,随便输入一个密码, ...
- bs4 & 二进制写入图片视频
适用于:数据都在网页源代码上,可以直接从中提取到对应数据 例子:北京新发地网 原理:拿到页面源代码的文本,交给BeautifulSoup解析,然后找到对应的标签,获取值 关键词:BeautifulSo ...
- 看 AWS 如何通过 Nitro System 构建竞争优势
目录 目录 目录 前言 Amazon Nitro System Overview AWS EC2 的虚拟化技术演进之路 Nitro Hypervisor Nitro Cards Nitro Contr ...
- Nature | DNA甲基化测序助力人多能干细胞向胚胎全能8细胞的人工诱导|易基因项目文章
北京时间2022年3月22日凌晨,<Nature>期刊在线刊登了由中国科学院广州生物医学与健康研究所等单位牵头,深圳市易基因科技有限公司.中国科学技术大学等单位参与,应用人多能干细胞向胚胎 ...
- SpringCloud微服务实战——搭建企业级开发框架(四十):使用Spring Security OAuth2实现单点登录(SSO)系统
一.单点登录SSO介绍 目前每家企业或者平台都存在不止一套系统,由于历史原因每套系统采购于不同厂商,所以系统间都是相互独立的,都有自己的用户鉴权认证体系,当用户进行登录系统时,不得不记住每套系统的 ...
- 2022年5月11日,NBMiner发布了41.3版本,在内核中加入了100%LHR解锁器,从此NVIDIA的显卡再无锁卡一说
2022年5月11日,NBMiner发布NBMiner_41.3版本,主要提升了稳定性. 2022年5月8日,NBMiner发布NBMiner_41.0版本,在最新的内核 ...
- 1903021121—刘明伟—Java第三周作业—学习在eclipse上创建并运行java程序
项目 内容 课程班级博客链接 19信计班(本) 作业要求链接 第三周作业 作业要求 每道题要有题目,代码,截图 扩展阅读 eclipse如何创建java程序 java语言基础(上) 扩展阅读心得: 想 ...