Hadoop(14)-MapReduce框架原理-切片机制
1.FileInputFormat切片机制
切片机制

比如一个文件夹下有5个小文件,切片时会切5个片,而不是一个片
案例分析

2.FileInputFormat切片大小的参数配置
源码中计算切片大小的公式

切片大小设置

获取切片大小API

3. CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
1)应用场景
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值
3)切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分

(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
(2)切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
4.CombineTextInputFormat案例实操
准备四个小文件,大小在1M左右,以之前的wordcount代码为基础
直接运行代码,观察console

在WcDriver.class中,增加如下代码
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
观察console
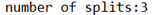
继续修改Wcdriver.class
//虚拟存储切片最大值设置20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520)
观察console
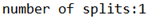
Hadoop(14)-MapReduce框架原理-切片机制的更多相关文章
- Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析
1.MapReduce的数据流 1) Input -> Mapper阶段 这一阶段的主要分工就是将文件切片和把文件转成K,V对 输入源是一个文件,经过InputFormat之后,到了Mapper ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- Hadoop(20)-MapReduce框架原理-OutputFormat
1.outputFormat接口实现类 2.自定义outputFormat 步骤: 1). 定义一个类继承FileOutputFormat 2). 定义一个类继承RecordWrite,重写write ...
- Hadoop(19)-MapReduce框架原理-Combiner合并
1. Combiner概述 2. 自定义Combiner实现步骤 1). 定义一个Combiner继承Reducer,重写reduce方法 public class WordcountCombiner ...
- Hadoop(15)-MapReduce框架原理-FileInputFormat的实现类
1. TextInputFormat 2.KeyValueTextInputFormat 3. NLineInputFormat
随机推荐
- 安装lombok(eclipse)
下载 lombok.jar (https://projectlombok.org/download.html) 将 lombok.jar 放在eclipse安装目录下,和 eclipse.ini 文件 ...
- RBG灯颜色渐变(颜色要尽可能多)程序分析
相信很多调过RBG灯的朋友都是通过分别改变R.B.G的占空比来改变颜色的,但是不是发现了一个问题,那就是不管怎样调都很难实现几十种颜色的变化,一般只有是7种颜色的渐变.下面给朋友们分享一个可以实现几十 ...
- MVG配置
MVG的配置:(前提是一个表的字段包含多值字段,一般是1:M或M:M的关系) 想要在学生界面显示多个教师的名称. 1.首先在一个Project中,建两张表学生表和教师表T_Stu与T_Tea和一张中间 ...
- 使用 yield生成迭代对象函数
https://www.cnblogs.com/python-life/articles/4549996.html https://www.liaoxuefeng.com/wiki/001431608 ...
- (六)svn 服务器端使用之权限管理
权限管理(了解) 认证授权机制 在企业开发中会为每位程序员.测试人员等相关人员分配一个账号,用户通过使用svn客户端连接svn服务时需要输入账号和密码,svn服务对账号和密码进行校验,输入正确可以继续 ...
- vue 单页应用中微信支付的坑
vue 单页应用中微信支付的坑 标签(空格分隔): 微信 支付 坑 vue 场景 在微信H5页面(使用 vue-router2 控制路由的 vue2 单页应用项目)中使用微信 jssdk 进行微信支付 ...
- python入门6 字符串拼接、格式化输出
字符串拼接方式 1 使用 + 拼接字符串 2 格式化输出:%s字符串 %d整数 %f浮点数 %%输出% %X-16进制 %r-原始字符串 3 str.format() 代码如下: #codin ...
- robotframework_如何用Chrome模拟手机打开H5页面
由于公司目前的产品大部分都是APP端的H5页面,APP原生页面很少,测试H5页面如果去搭建appium或者macaca这类自动化平台太费时,太重而不能快速落地:与自动化的目标:提高测试效率相悖.但如果 ...
- nautilus命令
nautilus 是图形程式效果是以当前用户打开图形界面所以如果想以root打开图形界面使用时记得先切为root,sudo没有用的
- bzoj5000 OI树
Description 几天之后小跳蚤即将结束自己在lydsy星球上的旅行.这时,lydsy人却发现他们的超空间传送装置的能量早在小跳蚤通过石板来到lydsy星球时就已经消耗光了.这时,小跳蚤了解到自 ...