1. 背景
Block Replica Placement——数据块复本存储策略,HDFS Namenode以此为依据选取数据块复本应存储至哪些HDFS Datanodes,策略的设计需要权衡以下三个因素:
注:本文均以数据块复本因子为3来讨论。
我们以两个比较极端的例子来说明上述三个因素之间的关系。
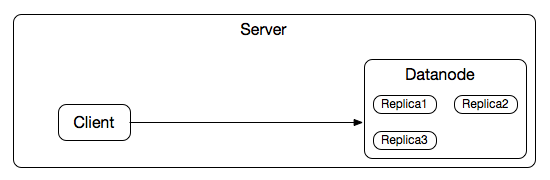
(1)数据块的三个复本集中存储至一台HDFS Datanode;
如果Client(数据写入客户端)与Datanode不是同一台机器,如下图:
数据块的第一个复本需要Client通过网络传输将数据写入Datanode,其余两个复本为本地写入,写带宽的开销为数据块的大小;
如果Client与Datanode是同一台机器,如下图:
数据块的三个复本均为本地写入,没有任何的网络数据传输,写带宽的开销为零。
这种策略的写带宽或为数据块大小,或为零,可以说是所有策略中写带宽开销最小的。但缺陷也比较明显,数据块的三个复本全部存储至一台Datanode,其它Datanodes中没有任何的冗余复本,如果这台Datanode出现故障,整个数据块的数据会全部丢失;数据的集中存储,也不利于“本地性计算”,如果这个数据块涉及的计算任务无法调度至这台Datanode实例所处的机器上运行,则数据需要远程读取,即需要跨机架(交换机)读取,读带宽开销较大。
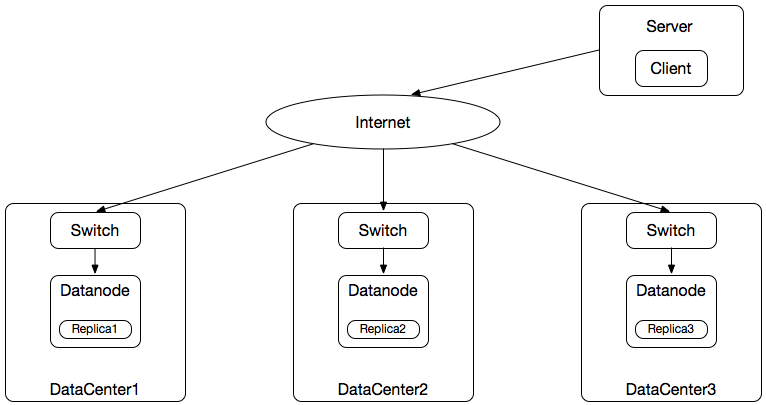
(2)数据块的全部复本分散存储至不同的数据中心(Data Center);
数据块的三个复本分别被存储至不同的三个数据中心的Datanode,数据可靠性最高,但数据的写入和读取大多需要通过互联网,写带宽和读带宽的开销较大。
可以看出,数据块复本存储策略的设计需要综合考虑可靠性、写带宽、读带宽三者之间的相互影响。
为什么说跨机架(交换机)或跨数据中心的带宽开销较大?
跨机架的服务器之间的通信需要通过交换机,跨数据中心的服务器之间的通信需要通过专线连接,对于公司而言,交换机和专线的带宽资源都是有限的,跨机架或数据中心的服务器之间大量的数据传输通常都会带来比较高昂的带宽成本。
2. Hadoop默认数据块复本存储策略
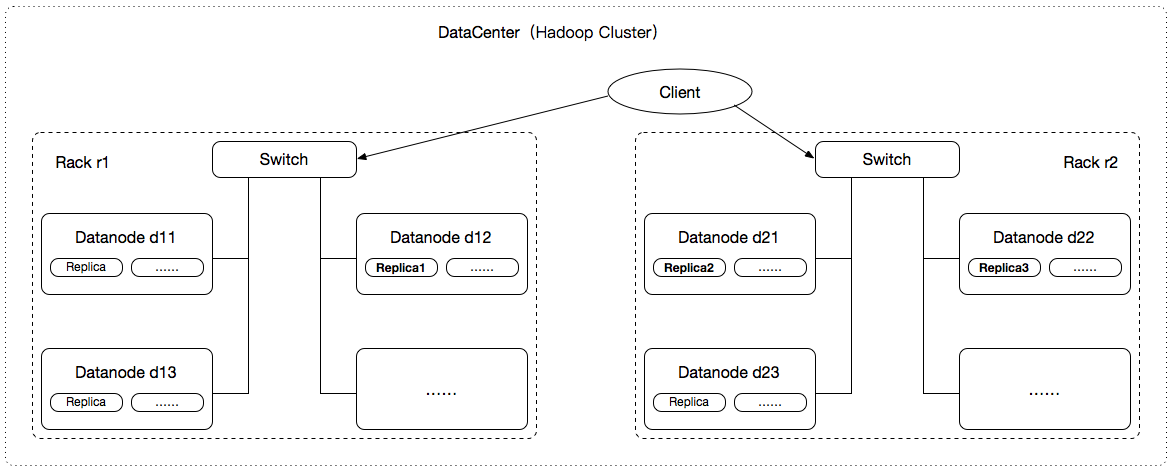
Hadoop默认数据块复本存储策略是以“一个数据中心、多个机架”为基础设计的,如下图所示:
(1)从HDFS Cluster中随机选取一个Datanode(Rack r1/Datanode d12)用于存储第一个复本Replica1;
(2)从其它机架(非Rack r1)中选取一个Datanode(Rack r2/Datanode d21)用于存储第二个复本Replica2;
(3)从机架Rack r2中随机选取一个Datanode(Rack r2/Datanode d22)用于存储第三个复本Replica3;
(4)如果复制因子大于3,则继续从HDFS Cluster中随机选取Datanode用于存储第n(n >= 4)个复本Replica;
说明:
(1)选取的Datanode需要满足:磁盘空间使用不是很多,系统负载不是很高(Datanode不是很繁忙);
(2)同一个机架中不要存储同一个数据块太多的复本;
3. 核心源码剖析
HDFS提供的数据块复本存储策略类结构如下:
HDFS 默认数据块复本存储策略实现类:org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault,它有三个非常重要的组成部分:
(1)NetworkTopology clusterMap;
(2)chooseTarget;
(3)getPipeline;
3.1 NetworkTopology
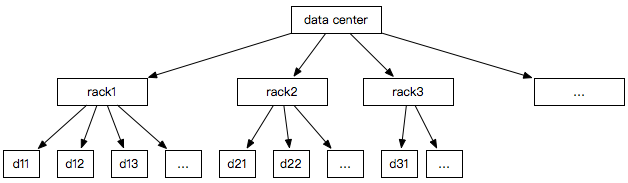
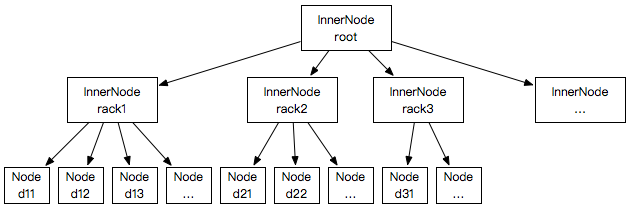
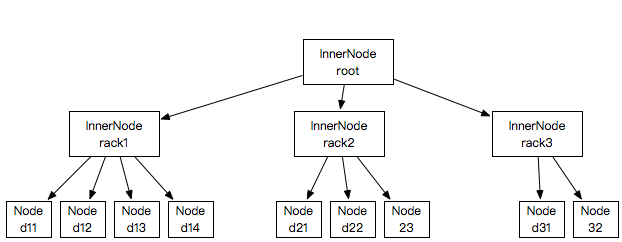
NetworkTopology(org.apache.hadoop.net.NetworkTopology)使用树形层级结构表示集群内部的网络拓扑结构,如下图:
HDFS默认数据块复本存储策略只考虑目前比较常见的一个数据中心(Data Center)的场景,如下图:
网络拓扑结构(NetworkTopology)的建立过程中涉及到一个非常重要的问题:机架感知,即在一个集群(数据中心)中,HDFS Namenode如何知道一个HDFS Datanode归属于哪个机架位?
在HDFS的实现中,机架感知有一个接口DNSToSwitchMapping(org.apache.hadoop.net.DNSToSwitchMapping):
其中,方法resolve用于解析机器主机名(域名)或IP地址(后续讨论统一使用IP地址)对应的机架ID。也就是说,所谓的机架感知,实际是通过一定的方式根据IP地址解析出对应的机架ID。DNSToSwitchMapping有很多的实现类(机架ID的解析方式可以有很多种),HDFS具体使用哪一种实现,可以通过属性“net.topology.node.switch.mapping.impl”进行指定,这里我们仅仅介绍默认实现:ScriptBasedMapping(org.apache.hadoop.net.ScriptBasedMapping)。
ScriptBasedMapping是DNSToSwitchMapping的一种实现,允许我们提供一个自定义的脚本,用于完成IP地址与机架ID之间的解析。自定义的脚本使用时需要我们在配置文件core-default.xml中进行声明,与之相关的有两个重要的属性:
net.topology.script.file.name:自定义脚本的绝对路径;
net.topology.script.number.args:自定义脚本最多可接受的参数个数,默认值为100;
ScriptBasedMapping每次解析IP地址(可能有多个)对应的机架ID时,均需要调用resolve方法,工作过程如下:
(1)将需要解析的IP地址以列表(List)的参数形式传入resolve方法,即resolve方法可以一次性解析多个IP地址对应的机架ID;
(2)resolve方法内部将IP地址列表转换为自定义脚本可接受的“多个参数”,执行自定义脚本;
(3)获取自定义脚本的输出,并从中解析出与IP地址列表一一对应的机架ID,并以列表(List)的形式返回;
注:受限于自定义脚本最多可接受的参数个数(net.topology.script.number.args),resolve方法内部可能需要将IP地址列表分批多次调用自定义脚本,完成整个解析过程。
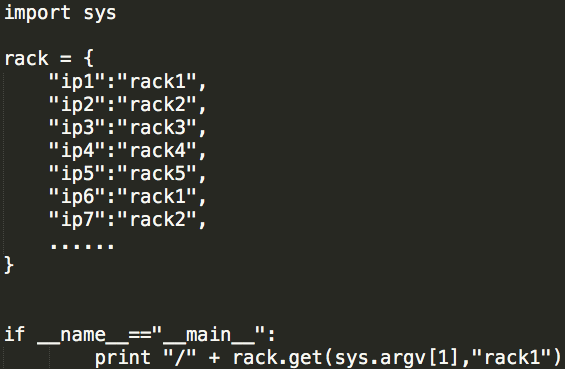
假设自定义脚本使用Python语言实现,且仅可以接受一个参数(net.topology.script.number.args=1),脚本示例如下:
如果IP列表为:
ip1
ip3
ip6
解析出的机架ID:
/rack1
/rack3
/rack1
自定义脚本的执行是由ShellCommandExecutor(org.apache.hadoop.util.Shell.ShellCommandExecutor)驱动的,它的内部使用java.lang.ProcessBuilder、java.lang.Process,将脚本以子进程的方式执行,然后通过java.lang.Process.getInputStream()获取脚本的输出内容(一行字符串),最后通过java.util.StringTokenizer从输出内容中获取机架ID。
ShellCommandExecutor执行自定义脚本的过程中,需要注意以下几个问题:
(1)脚本的执行过程是以子进程的形式进行的,高并发调用下可能带来比较大的性能开销;
(2)脚本需要支持接收多个参数,这里特指多个以空格分隔的IP地址字符串;
(3)因为脚本可能接收多个IP地址(2),因此脚本输出可能包含多个机架ID,与输入的IP地址一一对应;如上所述,脚本的输出内容为一行字符串,为了能够从中解析出多个机架ID,该字符串必须以空格、\t、\n、\r、\f之一作为分隔符,否则java.util.StringTokenizer无法正确解析。
综上所述,HDFS默认使用的机架感知策略是通过我们自定义的一个脚本实现的,这给了我们很大的自由度,可以根据自身的实际情况任意调整HDFS Datanode归属的机架ID。
那么,网络拓扑结构,即NetworkTopology实例的内部数据结构,是在什么时候被建立的?
众所周知,HDFS使用的是Master-Slave模式,Namenode相当于Master,Datanode相当于Slave,Datanode启动之后需要向Namenode进行注册,一个个Datanode向Namenode注册的过程中,就包含着机架感知、网络拓扑结构的建立过程,相关代码可以参考:org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode。
NetworkTopology实例的内部数据结构大致如下图所示:
InnerNode与Node的代码可以参考:org.apache.hadoop.net.NetworkTopology.InnerNode、org.apache.hadoop.net.Node。
3.2 chooseTarget
如上文2.1中所述,BlockPlacementPolicyDefault chooseTarget的工作过程可以简要归纳为四步,具体实现时这四步可以对应到四个方法:
(1)从HDFS Cluster中随机选取一个Datanode(Rack r1/Datanode d12)用于存储第一个复本Replica1;
chooseLocalStorage(org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseLocalStorage);
(2)从其它机架(非Rack r1)中选取一个Datanode(Rack r2/Datanode d21)用于存储第二个复本Replica2;
chooseRemoteRack(org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseRemoteRack);
(3)从机架Rack r2中随机选取一个Datanode(Rack r2/Datanode d22)用于存储第三个复本Replica3;
chooseLocalRack(org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseLocalRack);
(4)如果复制因子大于3,则依次从HDFS Cluster中随机选取Datanode用于存储第n(n >= 4)个复本Replica;
chooseRandom(org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseRandom);
实际上,chooseLocalStorage、chooseRemoteRack、chooseLocalRack最终都会将调用请求转发给chooseRandom进行处理,这是为什么呢?
chooseLocalStorage:从整个集群中“随机”选取一个Node或直接选取本机(忽略这种情况);
chooseRemoteRack:从整个集群中的其它(即排除指定机架)机架中“随机”选取一个Node;
chooseLocalRack:从集群中的指定机架中“随机”选取一个Node;
这三个方法的工作过程中都涉及到“随机”的选取过程,而chooseRandom的方法参数设计过程中已经考虑到了上述三个情况:
chooseLocalStorage调用chooseRandom时:
numOfReplicas:1,表示我们需要选取多少个Node;
scope:网络拓扑结构的根节点(root),即"";表示从整个集群中随机选取;
excludedNodes:空值或已经被选取的Nodes,表示选取出的Node不能出现在这些excludedNodes中;
chooseRemoteRack调用chooseRandom时:
numOfReplicas:1,表示我们需要选取多少个Node;
scope:~rack,表示从整个集群中非rack机架中随机选取;
excludedNodes:空值或已经被选取的Nodes,表示选取出的Node不能出现在这些excludedNodes中;
chooseLocalRack调用chooseRandom时:
numOfReplicas:1,表示我们需要选取多少个Node;
scope:rack,表示从集群机架rack中随机选取;
excludedNodes:空值或已经被选取的Nodes,表示选取出的Node不能出现在这些excludedNodes中;
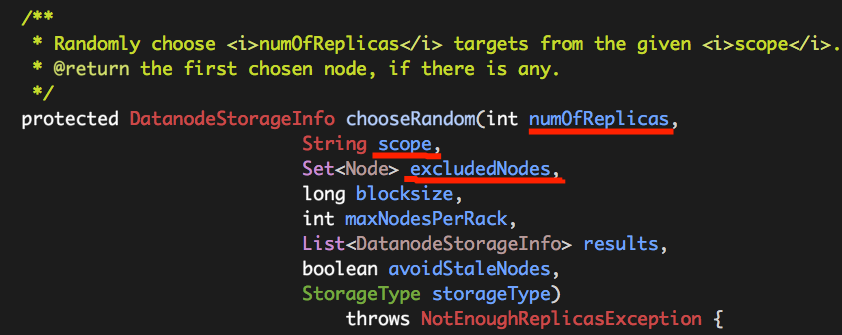
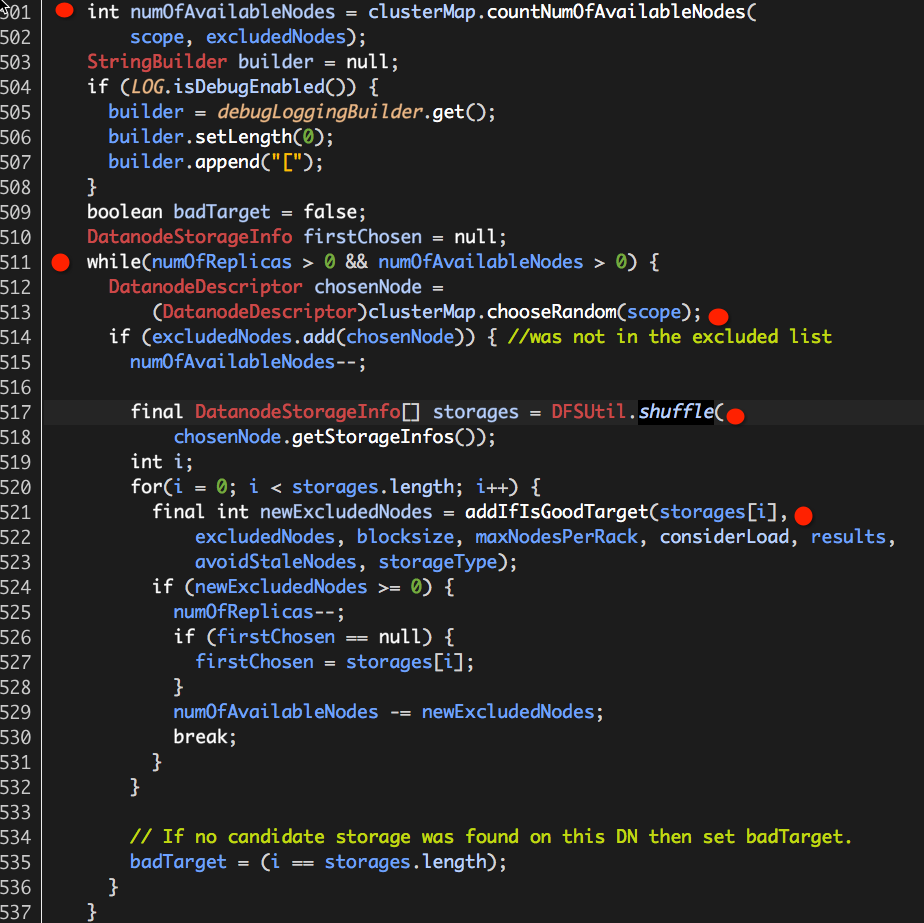
chooseRandom核心源码如下:
可以看出,chooseRandom整个工作流程可以理解为一个循环选取的过程,循环条件即为:“numOfReplicas > 0 && numOfAvailableNodes > 0”,它表示着两个含义:
(1)numOfReplicas > 0,表示仍需要继续选取Node用于存在数据块复本;在我们的讨论中,它的值恒为1;
(2)numOfAvailableNodes > 0,集群中尚有可用的Node用于选取;它的值是通过NetworkTopology countNumOfAvailableNodes(org.apache.hadoop.net.NetworkTopology.countNumOfAvailableNodes)计算而得的;根据计算上下文(chooseLocalStorage、chooseRemoteRack、chooseLocalRack)的不同,它可以计算整个集群、整个集群排除某机架、集群中指定机架的可用Node数目;
每一次的选取可以大致分为以下几步:
(1)从集群网络拓扑结构(NetworkTopology)中随机选取一个Node firstChosen(DatanodeDescriptor,实现Node接口,用于描述HDFS Datanode信息);
(2)如果firstChosen没有出现在excludedNodes中,则继续;否则,结束本次选取;
(3)获取firstChosen中存储信息storages(每一个HDFS Datanode可以指定多个存储位置,每一个存储位置使用DatanodeStorageInfo表示),并对这些storages进行随机排序(shuffle);
(4)依次从这些storages中寻找“适合”(addIfIsGoodTarget)的存储位置(DatanodeStorageInfo);
也就是说,最终返回的不只是某一个HDFS Datanode,还包括具体的存储位置,即DatanodeStorageInfo。
NetworkTopology chooseRandom
我们以一个具体的示例来说明集群网络拓扑结构的“随机选取”的过程。
假设我们的集群网络拓扑结构如下:
“随机选取”仅仅选取“Leaf Node”(叶子节点,表示Datanode),以“深度优先”的方式依次输出这些“Leaf Node”:
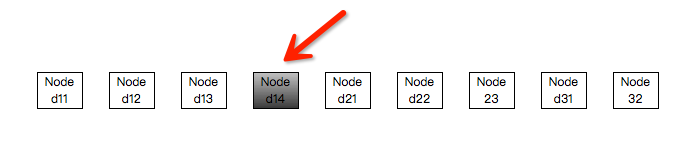
(1)整个集群中选取;
整个集群中可供选取的Node数目为9,取1~9之间的随机数,假设为4,则选取Node的方式为:从头部开始,选取第4个Node即可。
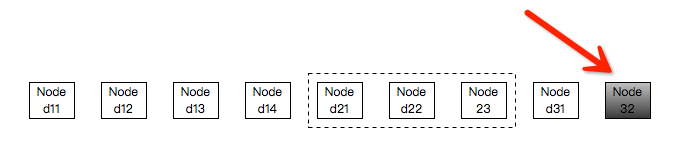
(2)整个集群中选取,且排除机架rack2;
整个集群需要排除机架rack2包含的Nodes,可供选取的Node数目为6,取1~6之间的随机数,假设为6,则选取Node的方式为:从头部开始,选取第6个Node即可。
(3)集群机架rack1中选取;
集群机架rack1中可供选取的Node数目为4,取1~4之间的随机数,假设为3,则选取Node的方式为:从头部开始,选取第3个Node即可。
BlockPlacementPolicyDefault addIfIsGoodTarget
如前所述,每一个Datanode可以包含多个存储位置(Datanode指定多个目录用于存储数据块复本,每一个目录挂载一块磁盘),选取Datanode完成之后,还需要从中寻找出“合适”的存储位置(DatanodeStorageInfo),如果从这个Datanode中无法找到“合适”的存储位置,则需要继续选取Node的过程。
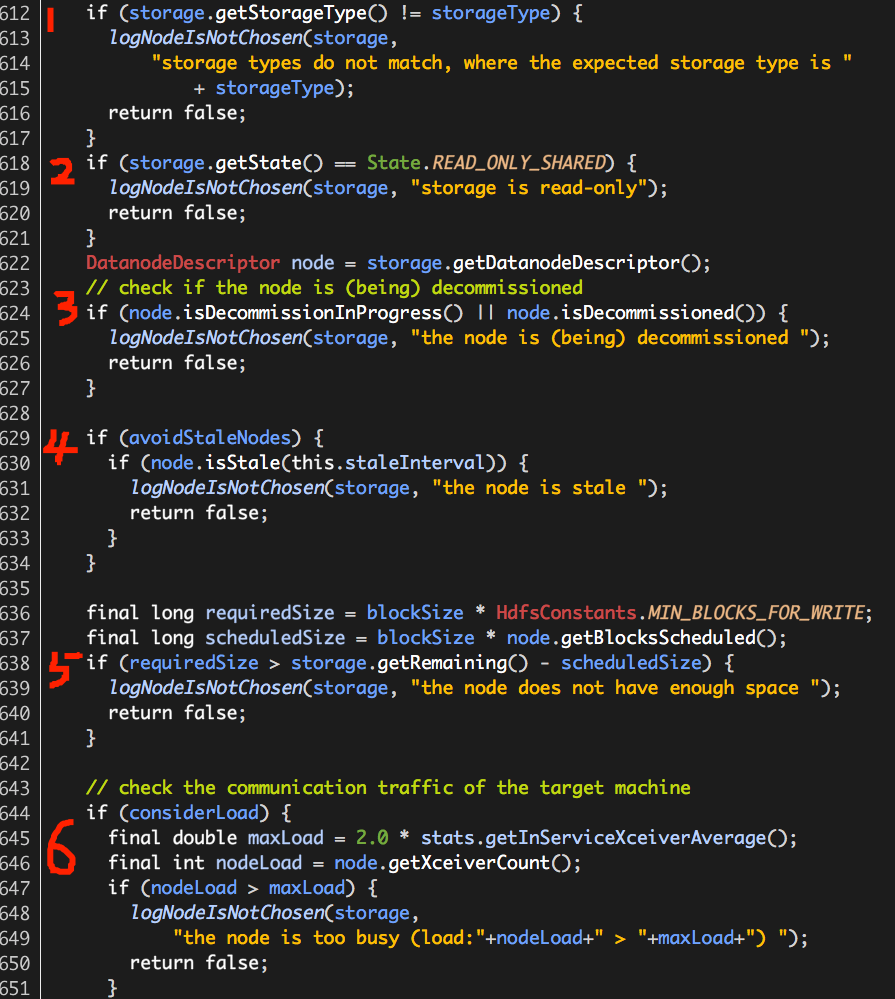
“合适”包括七个方面,源码如下:
(1)存储类型是否匹配,SSD/DISK;
(2)存储是否为只读;
(3)存储所处的Datanode是否处于下线状态;
(4)存储所处的Datanode状态是否异常;
(5)存储空间是否足够;
(6)存储所处的Datanode负载是否过高;
(7)存储所处的Datanode归属的机架中存储同一数据块的复本的Datanodes数目是否超过设置maxNodesPerRack;
注:(7)中maxNodesPerRack的计算公式:int maxNodesPerRack = (totalNumOfReplicas-1)/clusterMap.getNumOfRacks()+2;
3.3 getPipeline
用于存储数据块复本的Nodes选取完毕之后,还需要将Client与这些Nodes形成一个“管道”,而且这个“管道”的“节点距离之和”(数据传输距离)必须最短,getPipeline就是用来实现这个“管道”的形成过程的,实际就是一个排序的过程。
注:关于“节点距离”的概念可参考<<Hadoop The Definitive Guide>>章节:“Anatomy of a File Read”。
假设我们有一个Client和选取出的5个Nodes:d1、d2、d3、d4、d5,排序过程如下:
(1)从d1、d2、d3、d4、d5中找出与Client之间距离最短的Node,假设为d2;
(2)从d1、d3、d4、d5中找出与d2之间距离最短的Node,假设为d4;
(3)从d1、d3、d5中找出与d4之间距离最短的Node,假设为d1;
(4)从d3、d5中找出与d1之间的距离最短的Node,假设为d5;
最后我们即得到一个“节点距离之和”的管道:Client、d2、d4、d1、d5、d3。
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hdfs block数据块大小的设置规则
1.概述 hadoop集群中文件的存储都是以块的形式存储在hdfs中. 2.默认值 从2.7.3版本开始block size的默认大小为128M,之前版本的默认值是64M. 3.如何修改block块的 ...
- Kafka Topic Partition Replica Assignment实现原理及资源隔离方案
本文共分为三个部分: Kafka Topic创建方式 Kafka Topic Partitions Assignment实现原理 Kafka资源隔离方案 1. Kafka Topic创建方式 ...
- Block中__block实现原理
三.Block中__block实现原理 我们继续研究一下__block实现原理. 1.普通非对象的变量 先来看看普通变量的情况. #import <Foundation/Foundation.h ...
- 2本Hadoop技术内幕电子书百度网盘下载:深入理解MapReduce架构设计与实现原理、深入解析Hadoop Common和HDFS架构设计与实现原理
这是我收集的两本关于Hadoop的书,高清PDF版,在此和大家分享: 1.<Hadoop技术内幕:深入理解MapReduce架构设计与实现原理>董西成 著 机械工业出版社2013年5月出 ...
- CDH版HDFS Block Balancer方法
命令: sudo -u hdfs hdfs balancer 默认会检查每个datanode的磁盘使用情况,对磁盘使用超过整个集群10%的datanode移动block到其他datanode达到均衡作 ...
- block的内部实现原理
一.简单定义 block是一个指向结构体的指针,编译器将block内部代码生成对应的函数,上述结构体中的函数指针(funcPtr)指向该函数的实现: 二.相关概念 形参和实参 形参:形式参数,用于定义 ...
- block引用外部变量原理
block在赋值时才会生成对应的block结构体实例(结构体数据结构在编译时已经生成),赋值时会扫一遍里面引用的外部变量(嵌套block中的外部变量也算,只不过嵌套block中的外部变量会被内外两个b ...
- HDFS的HA集群原理分析
1.简单hdfs集群中存在的问题 不能存在两个NameNode 单节点问题 单节点故障转移 2.解决单节点问题 找额外一个NameNode备份原有的数据 会出现脑裂 脑裂:一个集群中多个管理者数据 ...
随机推荐
- 在VS中关于MySQL的相关问题
最近在vs上折腾mysql数据库 遇到了一些小问题,这里记录一下 问题一:数据源选择中没有mysql数据库的选项 解放方法: 1.安装MySql的VS插件(版本请下载最新版)mysql-for-vis ...
- Android模拟器对应的电脑快捷键说明
Home键(小房子键) 在键盘上映射的就是home键,这倒是很好记. Menu键 用于打开菜单的按键,在键盘上映射的是F2键,PgUp键同样可以.另外,看英文原文的意思,貌似这个键在某些机型上会被设计 ...
- SOA,ESB 与 SCA
SOA,ESB与 SCA SOA 与 ESB SOA(Service Oriented Architecture),面向服务体系结构,是一种组件模型架构,一种支撑软件运行的相对稳定的结构.其本质是一种 ...
- ios专题 - Scrum
什么是Scrum? Scrum是一个敏捷开发框架,是一个增量的.迭代的开发过程.在这个框架中,整个开发过程由若干个短的迭代周期组成,一个短的迭代周期称为一个 Sprint,每个Sprint的建议长度是 ...
- cocos2d-x 2.2.0 如何在lua中注册回调函数给C++
cocos2d-x内部使用tolua进行lua绑定,但是引擎并没有提供一个通用的接口让我们可以把一个lua函数注册给C++层面的回调事件.翻看引擎的lua绑定代码,我们可以仿照引擎中的方法来做.值得吐 ...
- 学习protobuf
一.认识Protobuf ref:http://blog.csdn.net/program_think/article/details/4229773摘要:1. protobuf是一个开源项目.2. ...
- 如何在本地安装测试ECSHOP 转载
如何在本地安装测试ECSHOP 如何在本地(自己的电脑)上先安装ECShop 一.创建PHP环境 1.下载AppServ 因为ECShop在线网上商店系统是用PHP语言开发的,所以,在本地架设网店之前 ...
- (三)跟我一起玩Linux网络服务:DHCP服务配置之主服务器配置
我们今天来做DHCP服务器的配置,我们的前提示要实现用一台虚拟机做DHCP服务器 1.首先,我们要有DHCP软件,我们用到下面两个软件(可以使用其他方法从网上直接安装,具体方法网络搜索) dhcp-3 ...
- Gherkin学习笔记
前言 由于项目准备使用BDD模式开发,所以最近在学习BDD,同时也记录下自己的学习点滴. 参考原文:https://github.com/cucumber/cucumber/wiki/Gherkin ...
- js设计模式--鸭子类型
1.简介 JavaScript没有提供传统面向对象语言的类式继承通过原型委托的形式实现对象与对象之间的继承没有对抽象类和接口的支持 编程语言按数据类型可分为静态类型语言和动态类型语言 变量的类型要到程 ...